[ad_1]
Machine studying (ML) fashions have gotten extra deeply built-in into many services we use every single day. This proliferation of synthetic intelligence (AI)/ML expertise raises a number of issues about privateness breaches, mannequin bias, and unauthorized use of information to coach fashions. All of those areas level to the significance of getting versatile and responsive management over the information a mannequin is educated on. Retraining a mannequin from scratch to take away particular knowledge factors, nevertheless, is usually impractical because of the excessive computational and monetary prices concerned. Analysis into machine unlearning (MU) goals to develop new strategies to take away knowledge factors effectively and successfully from a mannequin with out the necessity for in depth retraining. On this publish, we talk about our work on machine unlearning challenges and supply suggestions for extra sturdy analysis strategies.
Machine Unlearning Use Instances
The significance of machine unlearning can’t be understated. It has the potential to deal with essential challenges, corresponding to compliance with privateness legal guidelines, dynamic knowledge administration, reversing unintended inclusion of unlicensed mental property, and responding to knowledge breaches.
- Privateness safety: Machine unlearning can play a vital position in implementing privateness rights and complying with rules just like the EU’s GDPR (which features a proper to be forgotten for customers) and the California Client Privateness Act (CCPA). It permits for the elimination of non-public knowledge from educated fashions, thus safeguarding particular person privateness.
- Safety enchancment: By eradicating poisoned knowledge factors, machine unlearning might improve the safety of fashions towards knowledge poisoning assaults, which purpose to control a mannequin’s conduct.
- Adaptability enhancement: Machine unlearning at broader scale might assist fashions keep related as knowledge distributions change over time, corresponding to evolving buyer preferences or market tendencies.
- Regulatory compliance: In regulated industries like finance and healthcare, machine unlearning may very well be essential for sustaining compliance with altering legal guidelines and rules.
- Bias mitigation: MU might supply a approach to take away biased knowledge factors recognized after mannequin coaching, thus selling equity and decreasing the chance of unfair outcomes.
Machine Unlearning Competitions
The rising curiosity in machine unlearning is obvious from latest competitions which have drawn vital consideration from the AI neighborhood:
- NeurIPS Machine Unlearning Problem: This competitors attracted greater than 1,000 groups and 1,900 submissions, highlighting the widespread curiosity on this area. Apparently, the analysis metric used on this problem was associated to differential privateness, highlighting an necessary connection between these two privacy-preserving methods. Each machine unlearning and differential privateness contain a trade-off between defending particular data and sustaining total mannequin efficiency. Simply as differential privateness introduces noise to guard particular person knowledge factors, machine unlearning might trigger a normal “wooliness” or lower in precision for sure duties because it removes particular data. The findings from this problem present beneficial insights into the present state of machine unlearning methods.
- Google Machine Unlearning Problem: Google’s involvement in selling analysis on this space underscores the significance of machine unlearning for main tech corporations coping with huge quantities of person knowledge.
These competitions not solely showcase the variety of approaches to machine unlearning but additionally assist in establishing benchmarks and greatest practices for the sphere. Their recognition additionally evince the quickly evolving nature of the sphere. Machine unlearning could be very a lot an open drawback. Whereas there’s optimism about machine unlearning being a promising resolution to lots of the privateness and safety challenges posed by AI, present machine unlearning strategies are restricted of their measured effectiveness and scalability.
Technical Implementations of Machine Unlearning
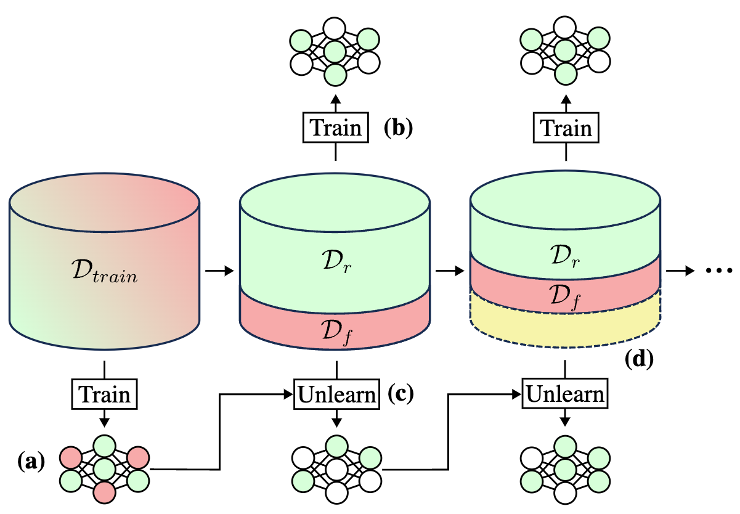
Most machine unlearning implementations contain first splitting the unique coaching dataset into knowledge (Dtrain) that must be stored (the retain set, or Dr) and knowledge that must be unlearned (the overlook set, or Df), as proven in Determine 1.
{kind=link}
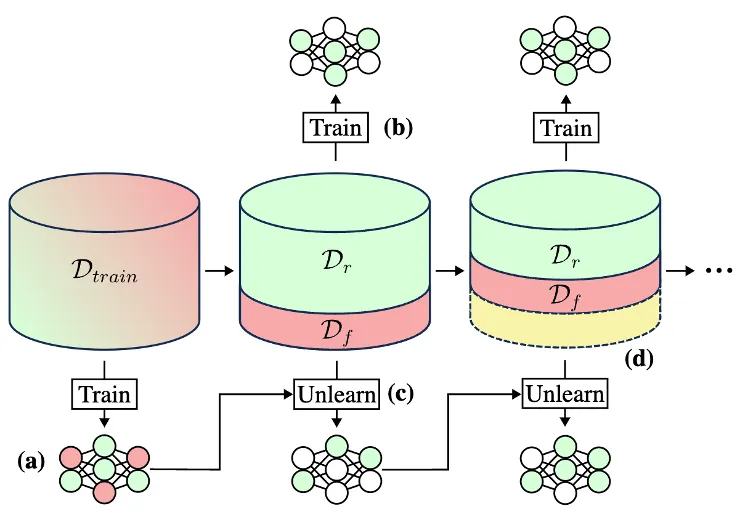
Determine 1: Typical ML mannequin coaching (a) entails utilizing all of the of the coaching knowledge to switch the mannequin’s parameters. Machine unlearning strategies contain splitting the coaching knowledge (Dtrain) into retain (Dr) and overlook (Df) units then iteratively utilizing these units to switch the mannequin parameters (steps b-d). The yellow part represents knowledge that has been forgotten throughout earlier iterations.
Subsequent, these two units are used to change the parameters of the educated mannequin. There are a selection of methods researchers have explored for this unlearning step, together with:
- Tremendous-tuning: The mannequin is additional educated on the retain set, permitting it to adapt to the brand new knowledge distribution. This system is easy however can require numerous computational energy.
- Random labeling: Incorrect random labels are assigned to the overlook set, complicated the mannequin. The mannequin is then fine-tuned.
- Gradient reversal: The signal on the load replace gradients is flipped for the information within the overlook set throughout fine-tuning. This instantly counters earlier coaching.
- Selective parameter discount: Utilizing weight evaluation methods, parameters particularly tied to the overlook set are selectively diminished with none fine-tuning.
The vary of various methods for unlearning displays the vary of use circumstances for unlearning. Totally different use circumstances have totally different desiderata—particularly, they contain totally different tradeoffs between unlearning effectiveness, effectivity, and privateness issues.
Analysis and Privateness Challenges
One problem of machine unlearning is evaluating how properly an unlearning method concurrently forgets the desired knowledge, maintains efficiency on retained knowledge, and protects privateness. Ideally a machine unlearning technique ought to produce a mannequin that performs as if it have been educated from scratch with out the overlook set. Widespread approaches to unlearning (together with random labeling, gradient reversal, and selective parameter discount) contain actively degrading mannequin efficiency on the datapoints within the overlook set, whereas additionally attempting to keep up mannequin efficiency on the retain set.
Naïvely, one might assess an unlearning technique on two easy aims: excessive efficiency on the retain set and poor efficiency on the overlook set. Nevertheless, this strategy dangers opening one other privateness assault floor: if an unlearned mannequin performs significantly poorly for a given enter, that would tip off an attacker that the enter was within the unique coaching dataset after which unlearned. Such a privateness breach, known as a membership inference assault, might reveal necessary and delicate knowledge a few person or dataset. It is important when evaluating machine unlearning strategies to check their efficacy towards these kinds of membership inference assaults.
Within the context of membership inference assaults, the phrases “stronger” and “weaker” check with the sophistication and effectiveness of the assault:
- Weaker assaults: These are less complicated, extra easy makes an attempt to deduce membership. They could depend on fundamental data just like the mannequin’s confidence scores or output possibilities for a given enter. Weaker assaults usually make simplifying assumptions in regards to the mannequin or the information distribution, which might restrict their effectiveness.
- Stronger assaults: These are extra refined and make the most of extra data or extra superior methods. They could:
- use a number of question factors or fastidiously crafted inputs
- exploit information in regards to the mannequin structure or coaching course of
- make the most of shadow fashions to raised perceive the conduct of the goal mannequin
- mix a number of assault methods
- adapt to the precise traits of the goal mannequin or dataset
Stronger assaults are usually more practical at inferring membership and are thus more durable to defend towards. They signify a extra practical menace mannequin in lots of real-world eventualities the place motivated attackers might need vital assets and experience.
Analysis Suggestions
Right here within the SEI AI division, we’re engaged on creating new machine unlearning evaluations that extra precisely mirror a manufacturing setting and topic fashions to extra practical privateness assaults. In our latest publication “Gone However Not Forgotten: Improved Benchmarks for Machine Unlearning,” we provide suggestions for higher unlearning evaluations based mostly on a assessment of the present literature, suggest new benchmarks, reproduce a number of state-of-the-art (SoTA) unlearning algorithms on our benchmarks, and examine outcomes. We evaluated unlearning algorithms for accuracy on retained knowledge, privateness safety with regard to the overlook knowledge, and velocity of undertaking the unlearning course of.
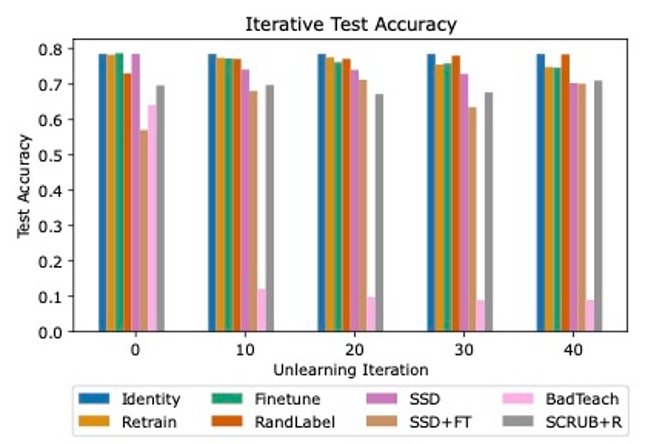
Our evaluation revealed giant discrepancies between SoTA unlearning algorithms, with many struggling to seek out success in all three analysis areas. We evaluated three baseline strategies (Id, Retrain, and Finetune on retain) and 5 state-of-the-art unlearning algorithms (RandLabel, BadTeach, SCRUB+R, Selective Synaptic Dampening [SSD], and a mix of SSD and finetuning).
{kind=link}
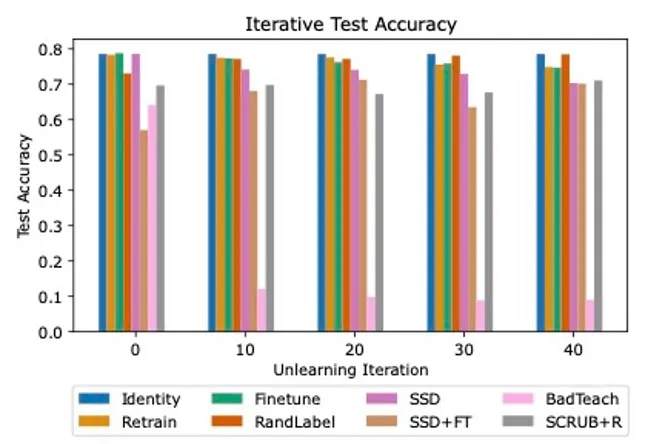
Determine 2: Iterative unlearning outcomes for ResNet18 on CIFAR10 dataset. Every bar represents the outcomes for a special unlearning algorithm. Observe the discrepancies in take a look at accuracy amongst the assorted algorithms. BadTeach quickly degrades mannequin efficiency to random guessing, whereas different algorithms are capable of keep or in some circumstances improve accuracy over time.
In keeping with earlier analysis, we discovered that some strategies that efficiently defended towards weak membership inference assaults have been fully ineffective towards stronger assaults, highlighting the necessity for worst-case evaluations. We additionally demonstrated the significance of evaluating algorithms in an iterative setting, as some algorithms more and more damage total mannequin accuracy over unlearning iterations, whereas some have been capable of constantly keep excessive efficiency, as proven in Determine 2.
Primarily based on our assessments, we advocate that practitioners:
1) Emphasize worst-case metrics over average-case metrics and use robust adversarial assaults in algorithm evaluations. Customers are extra involved about worst-case eventualities—corresponding to publicity of non-public monetary data—not average-case eventualities. Evaluating for worst-case metrics gives a high-quality upper-bound on privateness.
2) Contemplate particular forms of privateness assaults the place the attacker has entry to outputs from two totally different variations of a mannequin, for instance, leakage from mannequin updates. In these eventualities, unlearning may end up in worse privateness outcomes as a result of we’re offering the attacker with extra data. If an update-leakage assault does happen, it must be no extra dangerous than an assault on the bottom mannequin. Presently, the one unlearning algorithms benchmarked on update-leakage assaults are SISA and GraphEraser.
3) Analyze unlearning algorithm efficiency over repeated purposes of unlearning (that’s, iterative unlearning), particularly for degradation of take a look at accuracy efficiency of the unlearned fashions. Since machine studying fashions are deployed in consistently altering environments the place overlook requests, knowledge from new customers, and unhealthy (or poisoned) knowledge arrive dynamically, it’s essential to guage them in an analogous on-line setting, the place requests to overlook datapoints arrive in a stream. At current, little or no analysis takes this strategy.
Wanting Forward
As AI continues to combine into numerous elements of life, machine unlearning will seemingly develop into an more and more very important software—and complement to cautious curation of coaching knowledge—for balancing AI capabilities with privateness and safety issues. Whereas it opens new doorways for privateness safety and adaptable AI methods, it additionally faces vital hurdles, together with technical limitations and the excessive computational price of some unlearning strategies. Ongoing analysis and growth on this area are important to refine these methods and guarantee they are often successfully applied in real-world eventualities.
[ad_2]