[ad_1]

Picture by Creator
Sturdy Python and SQL abilities are each integral to many knowledge professionals. As a knowledge skilled, you’re most likely snug with Python programming—a lot that writing Python code feels fairly pure. However are you following one of the best practices when engaged on knowledge science initiatives with Python?
Although it is simple to study Python and construct knowledge science functions with it, it is, maybe, simpler to put in writing code that’s laborious to take care of. That will help you write higher code, this tutorial explores some Python coding greatest practices which assist with dependency administration and maintainability resembling:
- Organising devoted digital environments when engaged on knowledge science initiatives regionally
- Enhancing maintainability utilizing sort hints
- Modeling and validating knowledge utilizing Pydantic
- Profiling code
- Utilizing vectorized operations when doable
So let’s get coding!
1. Use Digital Environments for Every Venture
Digital environments guarantee venture dependencies are remoted, stopping conflicts between completely different initiatives. In knowledge science, the place initiatives usually contain completely different units of libraries and variations, Digital environments are notably helpful for sustaining reproducibility and managing dependencies successfully.
Moreover, digital environments additionally make it simpler for collaborators to arrange the identical venture surroundings with out worrying about conflicting dependencies.
You should utilize instruments like Poetry to create and handle digital environments. There are numerous advantages to utilizing Poetry but when all you want is to create digital environments in your initiatives, you can too use the built-in venv module.
If you’re on a Linux machine (or a Mac), you may create and activate digital environments like so:
# Create a digital surroundings for the venture
python -m venv my_project_env
# Activate the digital surroundings
supply my_project_env/bin/activate
When you’re a Home windows consumer, you may test the docs on learn how to activate the digital surroundings. Utilizing digital environments for every venture is, due to this fact, useful to maintain dependencies remoted and constant.
2. Add Sort Hints for Maintainability
As a result of Python is a dynamically typed language, you do not have to specify within the knowledge sort for the variables that you just create. Nevertheless, you may add sort hints—indicating the anticipated knowledge sort—to make your code extra maintainable.
Let’s take an instance of a perform that calculates the imply of a numerical characteristic in a dataset with acceptable sort annotations:
from typing import Listing
def calculate_mean(characteristic: Listing[float]) -> float:
# Calculate imply of the characteristic
mean_value = sum(characteristic) / len(characteristic)
return mean_value
Right here, the sort hints let the consumer know that the calcuate_mean perform takes in a listing of floating level numbers and returns a floating-point worth.
Keep in mind Python doesn’t implement varieties at runtime. However you need to use mypy or the like to lift errors for invalid varieties.
3. Mannequin Your Knowledge with Pydantic
Beforehand we talked about including sort hints to make code extra maintainable. This works wonderful for Python features. However when working with knowledge from exterior sources, it is usually useful to mannequin the information by defining lessons and fields with anticipated knowledge sort.
You should utilize built-in dataclasses in Python, however you don’t get knowledge validation assist out of the field. With Pydantic, you may mannequin your knowledge and likewise use its built-in knowledge validation capabilities. To make use of Pydantic, you may set up it together with the e-mail validator utilizing pip:
$ pip set up pydantic[email-validator]
Right here’s an instance of modeling buyer knowledge with Pydantic. You possibly can create a mannequin class that inherits from BaseModel and outline the varied fields and attributes:
from pydantic import BaseModel, EmailStr
class Buyer(BaseModel):
customer_id: int
title: str
e-mail: EmailStr
cellphone: str
deal with: str
# Pattern knowledge
customer_data = {
'customer_id': 1,
'title': 'John Doe',
'e-mail': '[email protected]',
'cellphone': '123-456-7890',
'deal with': '123 Most important St, Metropolis, Nation'
}
# Create a buyer object
buyer = Buyer(**customer_data)
print(buyer)
You possibly can take this additional by including validation to test if the fields all have legitimate values. When you want a tutorial on utilizing Pydantic—defining fashions and validating knowledge—learn Pydantic Tutorial: Knowledge Validation in Python Made Easy.
4. Profile Code to Establish Efficiency Bottlenecks
Profiling code is useful in case you’re seeking to optimize your utility for efficiency. In knowledge science initiatives, you may profile reminiscence utilization and execution occasions relying on the context.
Suppose you are engaged on a machine studying venture the place preprocessing a big dataset is a vital step earlier than coaching your mannequin. Let’s profile a perform that applies frequent preprocessing steps resembling standardization:
import numpy as np
import cProfile
def preprocess_data(knowledge):
# Carry out preprocessing steps: scaling and normalization
scaled_data = (knowledge - np.imply(knowledge)) / np.std(knowledge)
return scaled_data
# Generate pattern knowledge
knowledge = np.random.rand(100)
# Profile preprocessing perform
cProfile.run('preprocess_data(knowledge)')
If you run the script, you must see an analogous output:
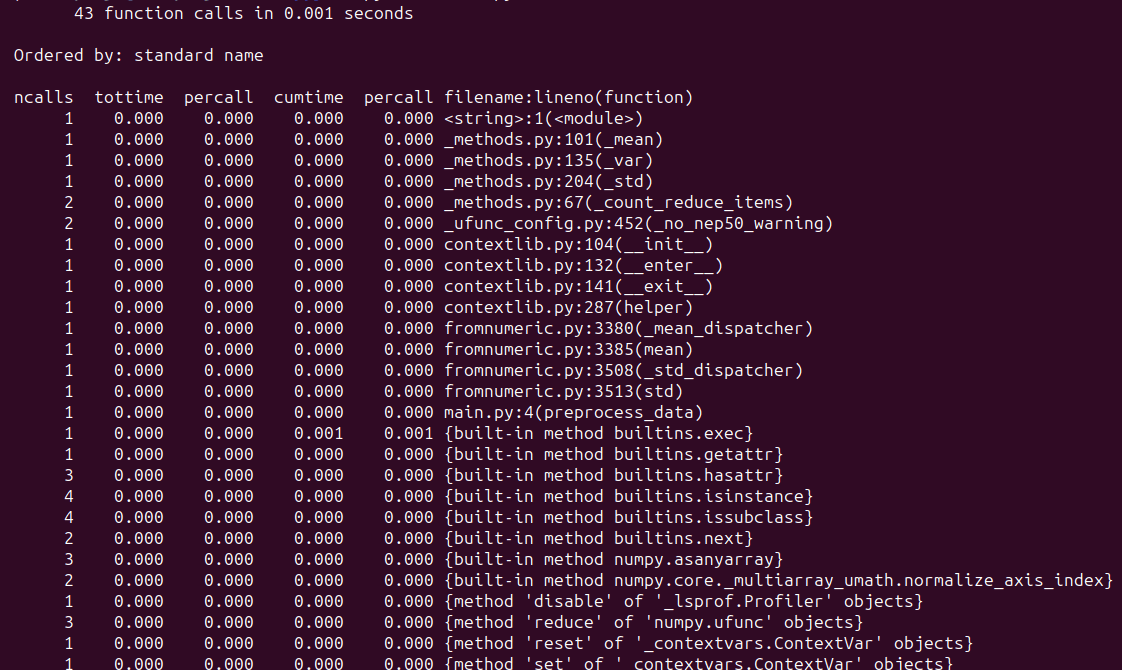
On this instance, we’re profiling the preprocess_data() perform, which preprocesses pattern knowledge. Profiling, typically, helps determine any potential bottlenecks—guiding optimizations to enhance efficiency. Listed here are tutorials on profiling in Python which you will discover useful:
5. Use NumPy’s Vectorized Operations
For any knowledge processing activity, you may at all times write a Python implementation from scratch. However you could not need to do it when working with massive arrays of numbers. For most typical operations—which will be formulated as operations on vectors—that you’ll want to carry out, you need to use NumPy to carry out them extra effectively.
Let’s take the next instance of element-wise multiplication:
import numpy as np
import timeit
# Set seed for reproducibility
np.random.seed(42)
# Array with 1 million random integers
array1 = np.random.randint(1, 10, measurement=1000000)
array2 = np.random.randint(1, 10, measurement=1000000)
Listed here are the Python-only and NumPy implementations:
# NumPy vectorized implementation for element-wise multiplication
def elementwise_multiply_numpy(array1, array2):
return array1 * array2
# Pattern operation utilizing Python to carry out element-wise multiplication
def elementwise_multiply_python(array1, array2):
end result = []
for x, y in zip(array1, array2):
end result.append(x * y)
return end result
Let’s use the timeit perform from the timeit module to measure the execution occasions for the above implementations:
# Measure execution time for NumPy implementation
numpy_execution_time = timeit.timeit(lambda: elementwise_multiply_numpy(array1, array2), quantity=10) / 10
numpy_execution_time = spherical(numpy_execution_time, 6)
# Measure execution time for Python implementation
python_execution_time = timeit.timeit(lambda: elementwise_multiply_python(array1, array2), quantity=10) / 10
python_execution_time = spherical(python_execution_time, 6)
# Examine execution occasions
print("NumPy Execution Time:", numpy_execution_time, "seconds")
print("Python Execution Time:", python_execution_time, "seconds")
We see that the NumPy implementation is ~100 occasions sooner:
Output >>>
NumPy Execution Time: 0.00251 seconds
Python Execution Time: 0.216055 seconds
Wrapping Up
On this tutorial, we’ve got explored a number of Python coding greatest practices for knowledge science. I hope you discovered them useful.
If you’re concerned with studying Python for knowledge science, try 5 Free Programs Grasp Python for Knowledge Science. Completely happy studying!
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, knowledge science, and content material creation. Her areas of curiosity and experience embrace DevOps, knowledge science, and pure language processing. She enjoys studying, writing, coding, and occasional! At the moment, she’s engaged on studying and sharing her information with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra. Bala additionally creates participating useful resource overviews and coding tutorials.
[ad_2]