[ad_1]
Incorporating demonstrating examples, often known as in-context studying (ICL), considerably enhances massive language fashions (LLMs) and huge multimodal fashions (LMMs) with out requiring parameter updates. Current research verify the efficacy of few-shot multimodal ICL, significantly in bettering LMM efficiency on out-of-domain duties. With longer context home windows in superior fashions like GPT-4o and Gemini 1.5 Professional, researchers can now examine the impression of accelerating demonstrating examples, an element beforehand constrained by context window limitations.
Some researchers noticed enhanced efficiency in LLMs with elevated in-context examples, albeit constrained by context measurement. Current research prolonged this exploration, demonstrating enhancements with over 1,000 examples, apart from in text-only benchmarks. Multimodal ICL analysis stays rising, with research exhibiting advantages for fashions like GPT-4V and Gemini in out-domain duties. Batch querying methods provide effectivity positive factors in inference, with current variations proposed to optimize efficiency, using bigger context home windows in current fashions.
To look at the potential of superior multimodal basis fashions in many-shot ICL, researchers from Stanford execute an intensive array of experiments to evaluate mannequin efficacy throughout 10 datasets overlaying varied domains and picture classification duties. This includes considerably growing the variety of demonstrating examples to gauge mannequin efficiency.
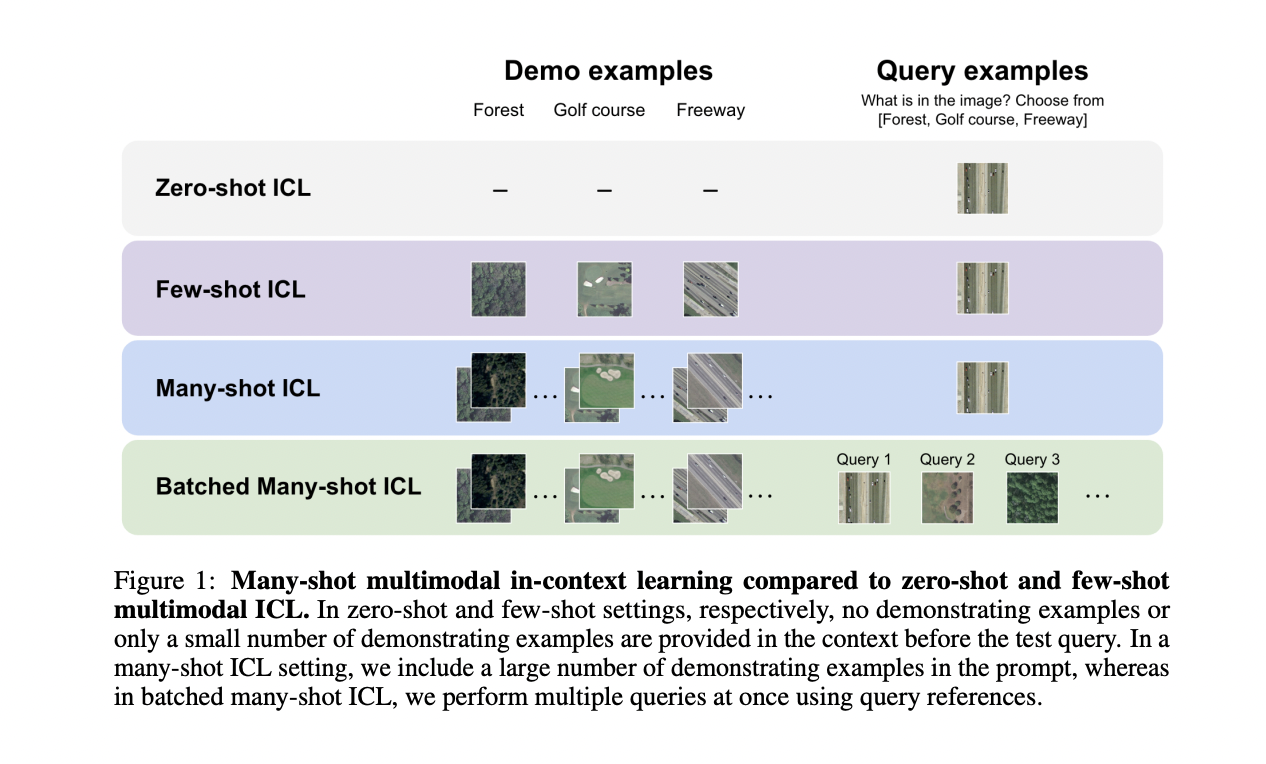
The Key findings of this research embody:
1. Elevated demonstrating examples considerably improve mannequin efficiency, with Gemini 1.5 Professional exhibiting constant log-linear enhancements in comparison with GPT-4o.
2. Gemini 1.5 Professional demonstrates increased ICL information effectivity in comparison with GPT-4o throughout most datasets.
3. Combining a number of queries right into a single request can ship comparable or superior efficiency to particular person queries in a many-shot situation. This method additionally reduces per-example latency considerably and gives a more cost effective inference course of.
4. Batched questioning notably enhances efficiency in zero-shot eventualities, attributed to area and sophistication calibrated and self-generated demonstrating examples by means of autoregressive decoding.
Three superior multimodal basis fashions—GPT-4o, GPT4(V)-Turbo, and Gemini 1.5 Professional—are employed, with GPT-4o and Gemini 1.5 Professional emphasised because of superior efficiency. Claude3-Opus is excluded from experiments because of its 20-image restrict per request. Every mannequin is accessed by means of particular endpoints, with OpenAI’s API service for GPT-4o and GPT-4(V)-Turbo, and Google Cloud’s Vertex AI for Gemini 1.5 Professional. Zero temperature is ready for all fashions, and a random seed ensures deterministic responses. Sampling methods guarantee class stability in demonstration and check units throughout 10 datasets spanning varied domains and classification duties, with demonstration examples scaled up whereas sustaining stability for analysis.
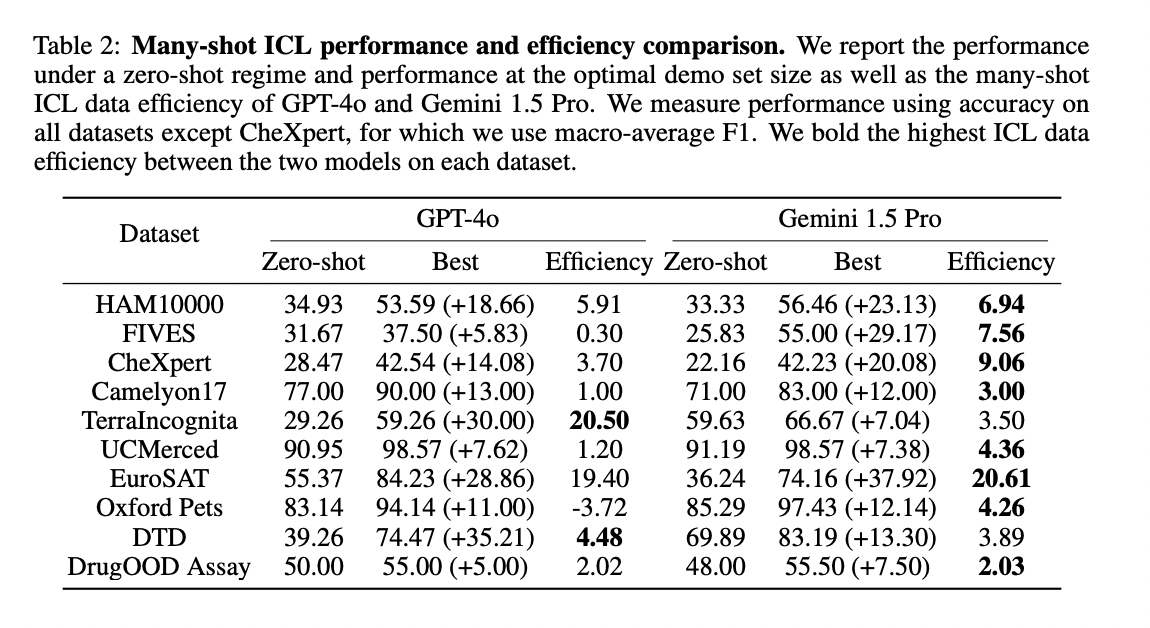
Gemini 1.5 Professional persistently demonstrates vital efficiency enhancements throughout most datasets as demonstrating examples enhance, apart from DrugOOD Assay. Significantly vital enhancements are noticed in HAM10000 (+23% accuracy in comparison with zero-shot), FIVES (+29% accuracy), and EuroSAT (+38% accuracy). for five out of the ten datasets (FIVES, UCMerced, EuroSAT, Oxford Pets, and
DTD), Gemini 1.5 Professional efficiency continues to enhance as much as the best variety of demonstrating
examples thought-about (~1,000 examples). Conversely, GPT-4o displays efficiency enhancements on most datasets however with much less consistency, exhibiting V-shaped scaling curves on many datasets. GPT-4o’s efficiency on DrugOOD Assay additionally shows excessive variance, just like Gemini 1.5 Professional, with peak efficiency at 50 demo examples.
To recapitulate, This research assesses many-shot ICL of state-of-the-art multimodal basis fashions throughout 10 datasets, revealing constant efficiency enhancements. Batching queries with many-shot ICL considerably reduces per-example latency and inference prices with out sacrificing efficiency. These findings recommend the potential of using massive numbers of demonstrating examples to adapt fashions rapidly to new duties and domains, circumventing the necessity for conventional fine-tuning. Future analysis ought to examine the comparative effectiveness and information effectivity of conventional fine-tuning versus many-shot ICL. Additionally, analyzing points like hallucinations and biases within the context of many-shot ICL and batched queries is essential for mannequin refinement and mitigating biases throughout various sub-groups.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]