[ad_1]
OpenAI has launched its newest and most superior language mannequin but – GPT-4o, also referred to as the “Omni” mannequin. This revolutionary AI system represents a large leap ahead, with capabilities that blur the road between human and synthetic intelligence.
On the coronary heart of GPT-4o lies its native multimodal nature, permitting it to seamlessly course of and generate content material throughout textual content, audio, pictures, and video. This integration of a number of modalities right into a single mannequin is a primary of its form, promising to reshape how we work together with AI assistants.
However GPT-4o is far more than only a multimodal system. It boasts a staggering efficiency enchancment over its predecessor, GPT-4, and leaves competing fashions like Gemini 1.5 Professional, Claude 3, and Llama 3-70B within the mud. Let’s dive deeper into what makes this AI mannequin actually groundbreaking.
Unparalleled Efficiency and Effectivity
Probably the most spectacular points of GPT-4o is its unprecedented efficiency capabilities. In accordance with OpenAI’s evaluations, the mannequin has a outstanding 60 Elo level lead over the earlier high performer, GPT-4 Turbo. This important benefit locations GPT-4o in a league of its personal, outshining even probably the most superior AI fashions at present out there.
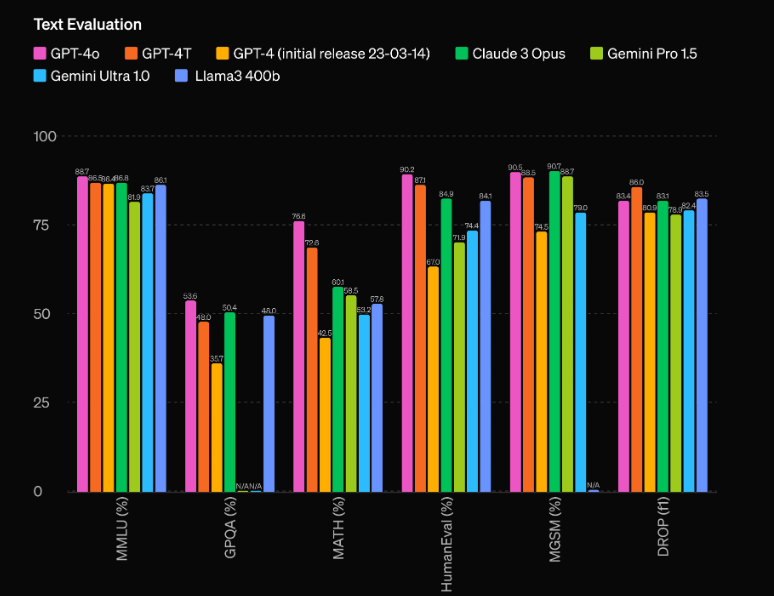
However uncooked efficiency is not the one space the place GPT-4o shines. The mannequin additionally boasts spectacular effectivity, working at twice the velocity of GPT-4 Turbo whereas costing solely half as a lot to run. This mix of superior efficiency and cost-effectiveness makes GPT-4o a particularly enticing proposition for builders and companies seeking to combine cutting-edge AI capabilities into their purposes.
Multimodal Capabilities: Mixing Textual content, Audio, and Imaginative and prescient
Maybe probably the most groundbreaking side of GPT-4o is its native multimodal nature, which permits it to seamlessly course of and generate content material throughout a number of modalities, together with textual content, audio, and imaginative and prescient. This integration of a number of modalities right into a single mannequin is a primary of its form, and it guarantees to revolutionize how we work together with AI assistants.
With GPT-4o, customers can interact in pure, real-time conversations utilizing speech, with the mannequin immediately recognizing and responding to audio inputs. However the capabilities do not cease there – GPT-4o may interpret and generate visible content material, opening up a world of potentialities for purposes starting from picture evaluation and technology to video understanding and creation.
Probably the most spectacular demonstrations of GPT-4o’s multimodal capabilities is its skill to investigate a scene or picture in real-time, precisely describing and decoding the visible components it perceives. This function has profound implications for purposes reminiscent of assistive applied sciences for the visually impaired, in addition to in fields like safety, surveillance, and automation.
However GPT-4o’s multimodal capabilities prolong past simply understanding and producing content material throughout totally different modalities. The mannequin may seamlessly mix these modalities, creating actually immersive and fascinating experiences. For instance, throughout OpenAI’s reside demo, GPT-4o was in a position to generate a track primarily based on enter situations, mixing its understanding of language, music principle, and audio technology right into a cohesive and spectacular output.
Utilizing GPT0 utilizing Python
import openai
# Exchange along with your precise API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Operate to extract the response content material
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("decisions") and len(response_dict["choices"]) > 0:
content material = response_dict["choices"][0]["message"]["content"].strip()
if content material:
for token in exclude_tokens:
content material = content material.substitute(token, '')
return content material
increase ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous operate to ship a request to the OpenAI chat API
async def send_openai_chat_request(immediate, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"function": "person", "content material": immediate}
response = await openai.ChatCompletion.acreate(
mannequin=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Instance utilization
async def essential():
immediate = "Hi there!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(immediate, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(essential())
I’ve:
- Imported the openai module straight as a substitute of utilizing a customized class.
- Renamed the openai_chat_resolve operate to get_response_content and made some minor adjustments to its implementation.
- Changed the AsyncOpenAI class with the openai.ChatCompletion.acreate operate, which is the official asynchronous methodology supplied by the OpenAI Python library.
- Added an instance essential operate that demonstrates the right way to use the send_openai_chat_request operate.
Please observe that you might want to substitute “your_openai_api_key_here” along with your precise OpenAI API key for the code to work accurately.





[ad_2]