[ad_1]

In a earlier weblog put up, we explored the facility of Cloudera Observability in offering high-level actionable insights and summaries for Hive service customers. On this weblog, we’ll delve deeper into the perception Cloudera Observability brings to queries executed on Hive.
As a fast recap, Cloudera Observability is an utilized observability resolution that gives visibility into Cloudera deployments and its varied providers. The device permits computerized actions to forestall damaging penalties like extreme useful resource consumption and price range overruns. Amongst different capabilities, Cloudera Observability delivers complete options to troubleshoot and optimize Hive queries. Moreover, it offers insights from deep analytics for quite a lot of supported engines utilizing question plans, system metrics, configuration, and far more.
A vital objective for a Hive SQL developer is guaranteeing that queries run effectively. If there are points within the question execution, it must be potential to debug and diagnose these shortly. In relation to particular person queries, the next questions sometimes crop up:
- What if my question efficiency deviates from the anticipated path?
- When my question goes astray, how do I detect deviations from the anticipated efficiency? Are there any baselines for varied metrics about my question? Is there a approach to evaluate totally different executions of the identical question?
- Am I overeating, or do I would like extra sources?
- What number of CPU/reminiscence sources are consumed by my question? And the way a lot was accessible for consumption when the question ran? Are there any automated well being checks to validate the sources consumed by my question?
- How do I detect issues as a consequence of skew?
- Are there any automated well being checks to detect points that may outcome from skew in knowledge distribution?
- How do I make sense of the stats?
- How do I take advantage of system/service/platform metrics to debug Hive queries and enhance their efficiency?
- I need to carry out an in depth comparability of two totally different runs; the place ought to I begin?
- What info ought to I take advantage of? How do I evaluate the configurations, question plans, metrics, knowledge volumes, and so forth?
Let’s examine how Cloudera Observability solutions the above questions and helps you detect issues with particular person queries.
What if my question efficiency deviates from the anticipated path?
Think about a periodic ETL or analytics job you run on Hive service for months instantly turns into sluggish. It’s a situation that’s not unusual, contemplating the multitude of things that have an effect on your queries. Ranging from the best, a job may decelerate as a result of your enter or output knowledge quantity elevated, knowledge distribution is now totally different due to the underlying knowledge modifications, concurrent queries are affecting the usage of shared sources, or system {hardware} points comparable to a sluggish disk. It might be a tedious process to search out out the place precisely your queries slowed down. This requires an understanding of how a question is executed internally and totally different metrics that customers ought to contemplate.
Enter Cloudera Observability’s baselining function, your troubleshooting companion. From execution occasions to intricate particulars in regards to the Hive question and its execution plan, each important facet is taken into account for baselining. This baseline is meticulously shaped utilizing historic knowledge from prior question executions. So if you detect efficiency deviations to your Hive queries, this function turns into your information, pointing you to metrics of curiosity.
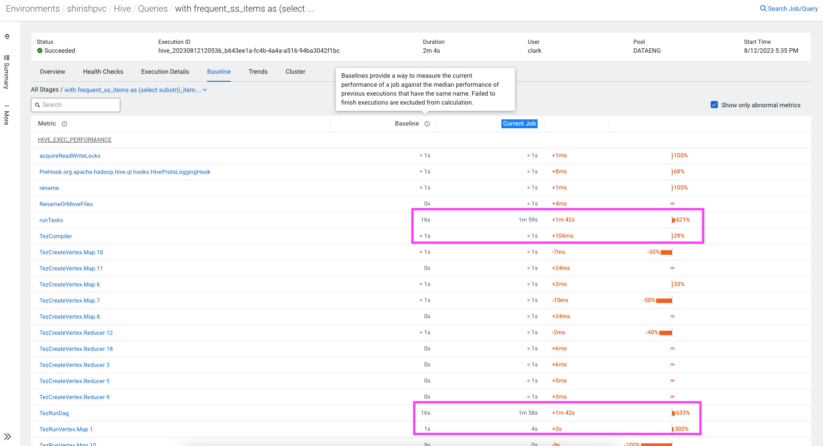
Am I overeating, or do I would like extra sources?
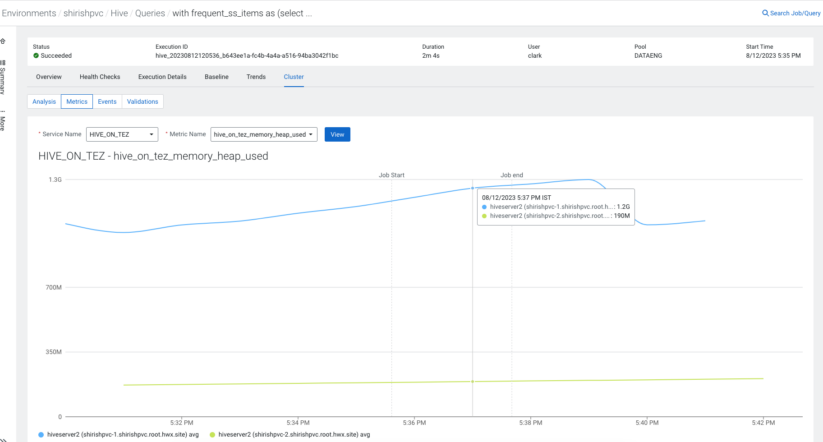
As an SQL developer, placing a steadiness between question execution and optimum use of sources is important. Naturally, you’ll need a simple approach to learn the way many sources had been consumed by your question and what number of had been accessible. Moreover, you additionally need to be a very good neighbor when utilizing shared system sources and never monopolize their use.
The “Cluster Metrics” function in Cloudera Observability helps you obtain this.
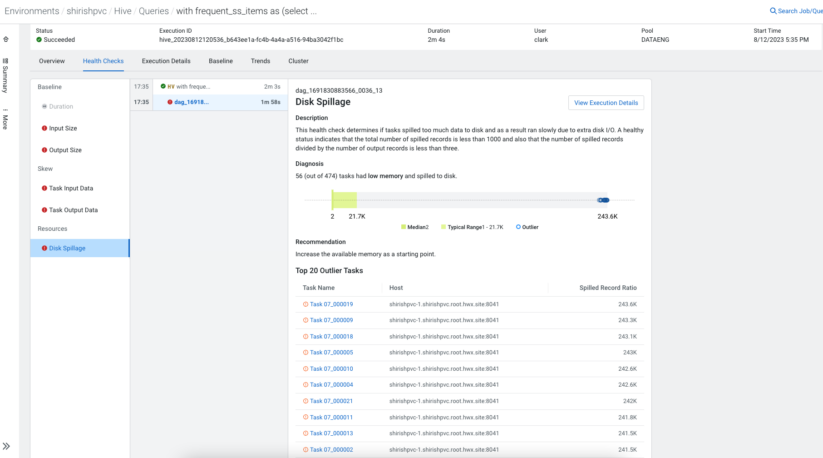
Challenges may come up you probably have fewer sources than your question wants. Cloudera Observability steps in with a number of automated question well being checks that provide help to establish the issues as a consequence of useful resource shortage.
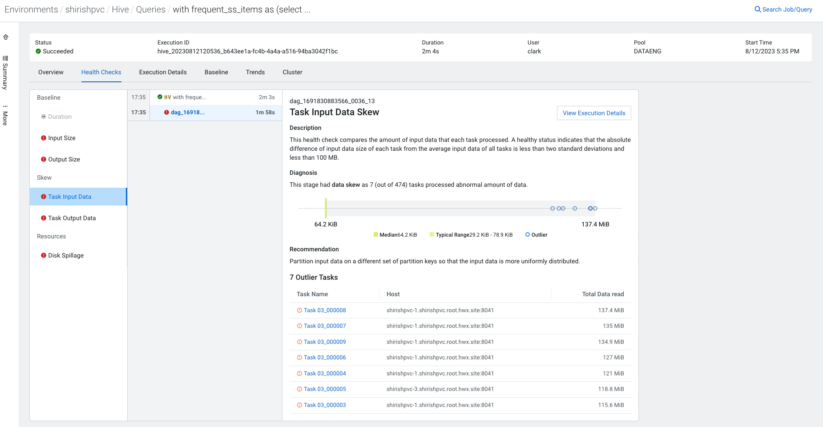
How do I detect issues as a consequence of skew?
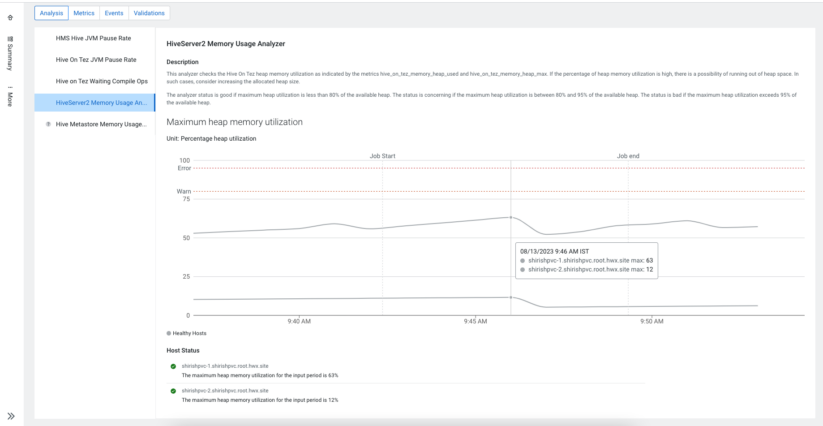
Within the realm of distributed databases (and Hive is not any exception), there may be a vital rule that knowledge must be distributed evenly. The non-uniform distribution of the information set is known as knowledge “skew.” Information skew could cause efficiency points and result in non-optimized utilization of obtainable sources. As such, the flexibility to detect points as a consequence of skew and supply suggestions to resolve these helps Hive customers significantly. Cloudera Observability comes armed with a number of built-in well being checks to detect issues as a consequence of skew to assist customers optimize queries.
How do I make sense of the stats?
In right now’s tech world, metrics have change into the soul of observability, flowing from working programs to complicated setups like distributed programs. Nevertheless, with 1000’s of metrics being generated each minute, it turns into difficult to search out out the metrics that have an effect on your question jobs.
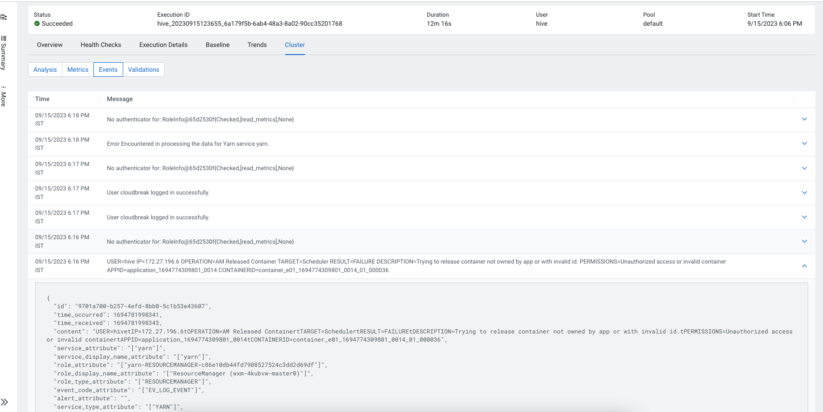
The Cloudera platform offers many such metrics to make it observable and help in debugging. Cloudera Observability goes a step additional and offers built-in analyzers that carry out well being checks on these metrics and spot any points. With the assistance of those analyzers, it’s straightforward to identify system and cargo points. Moreover, Cloudera Observability offers you the flexibility to look metric values for essential Hive metrics that will have affected your question execution. It additionally offers attention-grabbing occasions that will have occurred in your clusters whereas the question ran.
I need to carry out an in depth comparability of two totally different runs; the place ought to I begin?
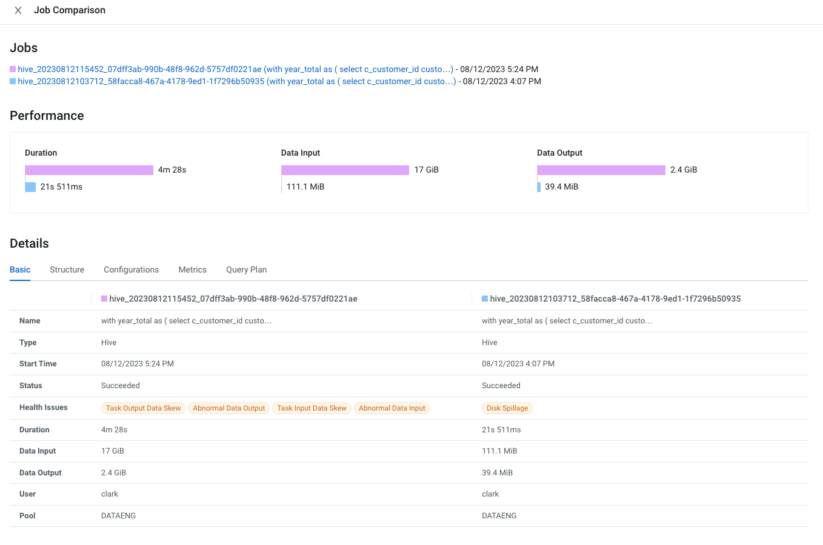
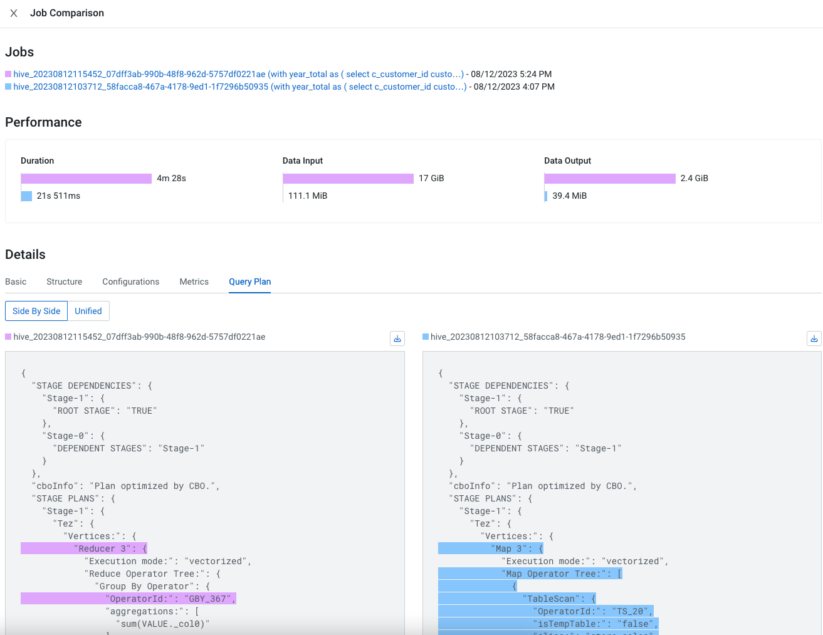
It’s commonplace to watch a degradation in question efficiency for varied causes. As a developer, you might be on a mission to check two totally different runs and spot the variations. However the place would you begin? There may be a lot to search out out and evaluate. For instance, ranging from essentially the most simple metrics like execution length or enter/output knowledge sizes, to complicated ones like variations between question plans, Hive configuration when the question was executed, the DAG construction, question execution metrics, and extra. A built-in function that achieves that is of nice use, and Cloudera Observability does this exactly for you.
With the question comparability function in Cloudera Observability, you possibly can evaluate the entire above components between two executions of the question. Now it’s easy to identify modifications between the 2 executions and take applicable actions.
As illustrated, gaining perception into your Cloudera Hive queries is a breeze with Cloudera Observability. Analyzing and troubleshooting Hive queries has by no means been this simple, enabling you to spice up efficiency and catch any points with a eager eye.
To seek out out extra about Cloudera Observability, go to our web site. To get began, get in contact together with your Cloudera account supervisor or contact us immediately.
[ad_2]