[ad_1]
Introduction
The article presents Anthropic’s newest Generative AI massive language mannequin, Claude 3.5 Sonnet, which is extremely proficient at arithmetic, reasoning, coding, and multilingual actions. It additionally covers its imaginative and prescient capabilities, real-world makes use of, safety precautions, and prospects going ahead with fashions like Haiku and Opus. The article emphasizes Claude 3.5 Sonnet’s essential contribution to the event of AI.
Overview
- Perceive how Anthropic’s Claude 3.5 Sonnet improves efficiency in reasoning, math, coding, and multilingual duties.
- Discover Claude 3.5 Sonnet’s capabilities in visible reasoning and textual content transcription from pictures.
- Be taught sensible makes use of of Claude 3.5 Sonnet in instruments like APIs for pure language processing and knowledge extraction.
- Uncover security measures in Claude 3.5 Sonnet guaranteeing privateness and ASL-2 compliance.
- Anticipate future Claude fashions like Haiku and Opus, and enhancements in reminiscence and new modalities.

What’s Claude 3.5 Sonnet?
In March 2024, Anthropic launched its Claude 3 household of fashions setting a brand new customary for efficiency and cost-effectiveness. GPT-4o and Gemini 1.5 Professional surpassed Claude 3 inside a number of months in each arenas. Now, it’s time for Anthropic to make a comeback with its Claude 3.5 Sonnet which is the very best mannequin on each efficiency and cost-effectiveness.
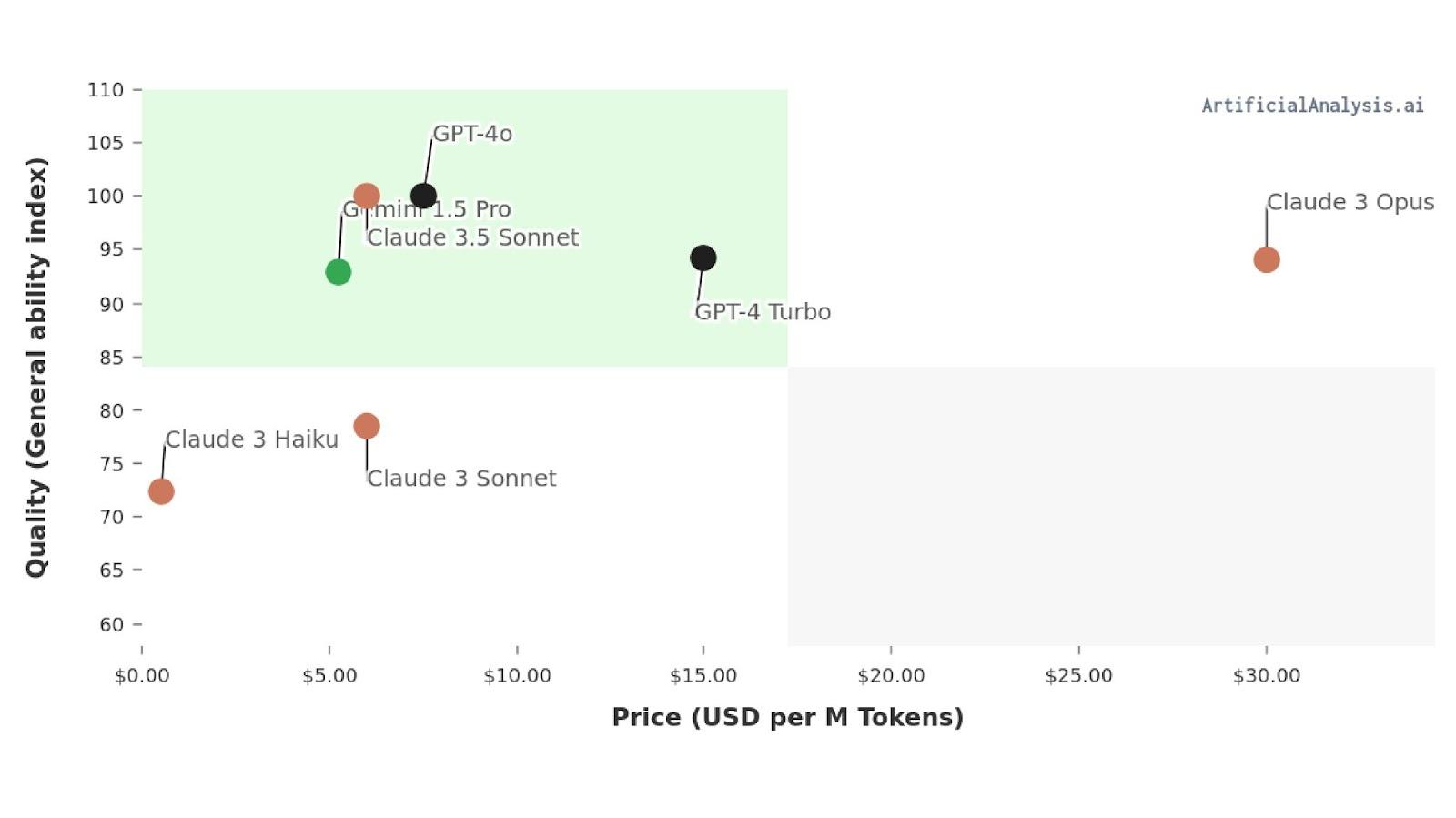
As we are able to see from the above picture, the Claude 3.5 Sonnet has the very best quality and is less expensive than the beforehand best-performing GPT-4o mannequin.
Reasoning and Query Answering
It units new benchmarks for many of the industry-standard metrics masking reasoning, studying comprehension, math, science, and coding.
- GPQA (Graduate Degree Q&A): Claude 3.5 Sonnet leads with 59.4% (0-shot) and 67.2% (5-shot), outperforming others.
- MMLU (Normal Reasoning): It scores highest at 90.4% (5-shot), displaying superior reasoning talents.
- MATH (Mathematical Drawback Fixing): Claude 3.5 Sonnet achieves 71.1% (0-shot), increased than earlier fashions.
- HumanEval (Python Coding): It excels with a 92.0% rating, indicating robust coding proficiency.
- MGSM (Multilingual Math): The mannequin scores 91.6% (0-shot), main in multilingual math.
- DROP (Studying Comprehension): It achieves 87.1% (F1 Rating, 3-shot), displaying robust comprehension expertise.
- BIG-Bench Laborious (Combined Evaluations): It scores 93.1% (3-shot), indicating strong combined process efficiency.
- GSM8K (Grade College Math): Claude 3.5 Sonnet leads with 96.4% (0-shot), demonstrating wonderful math problem-solving expertise.

Imaginative and prescient Capabilities
Claude 3.5 Sonnet is essentially the most highly effective imaginative and prescient mannequin on customary imaginative and prescient benchmarks. It excels in visible reasoning duties, resembling decoding charts and graphs, and precisely transcribes textual content from imperfect pictures.
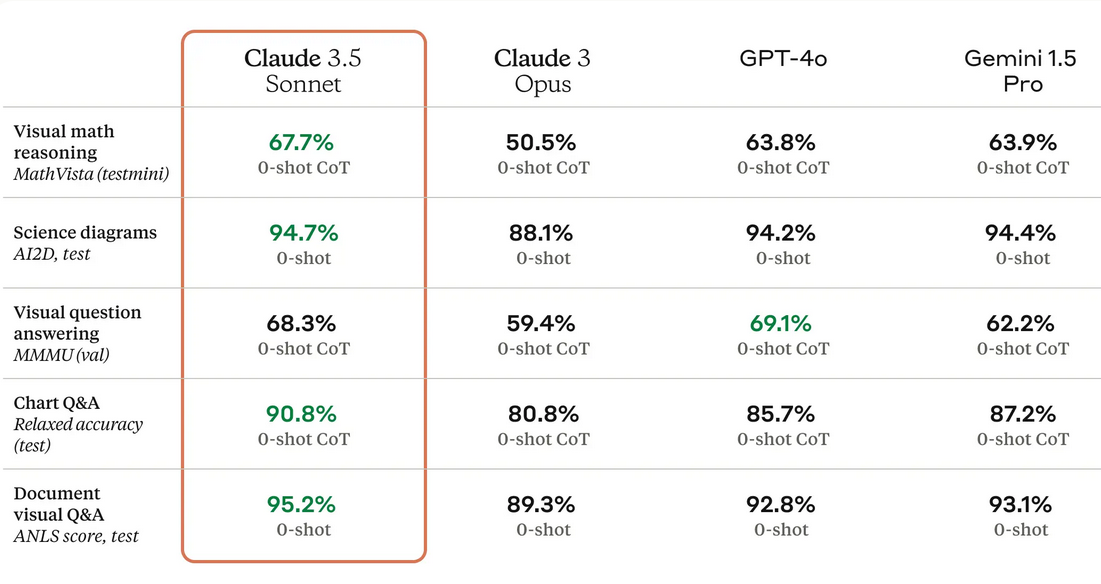
It will probably use exterior instruments relying on the duty at hand, and carry out varied duties like returning API calls with pure language requests, extracting structured knowledge, answering questions by looking databases, and many others. We will even study from Anthropic programs on GitHub itself about easy methods to combine instruments.
Artifacts
Anthropic launched a brand new function that revolutionizes person interplay with Claude. When customers request content material like code snippets, textual content paperwork, or web site designs, these Artifacts now seem in a devoted window alongside their dialog. This enhancement not solely improves usability but additionally units a brand new customary for interactive AI options.
Now let’s check the mannequin’s imaginative and prescient capabilities with artifacts.
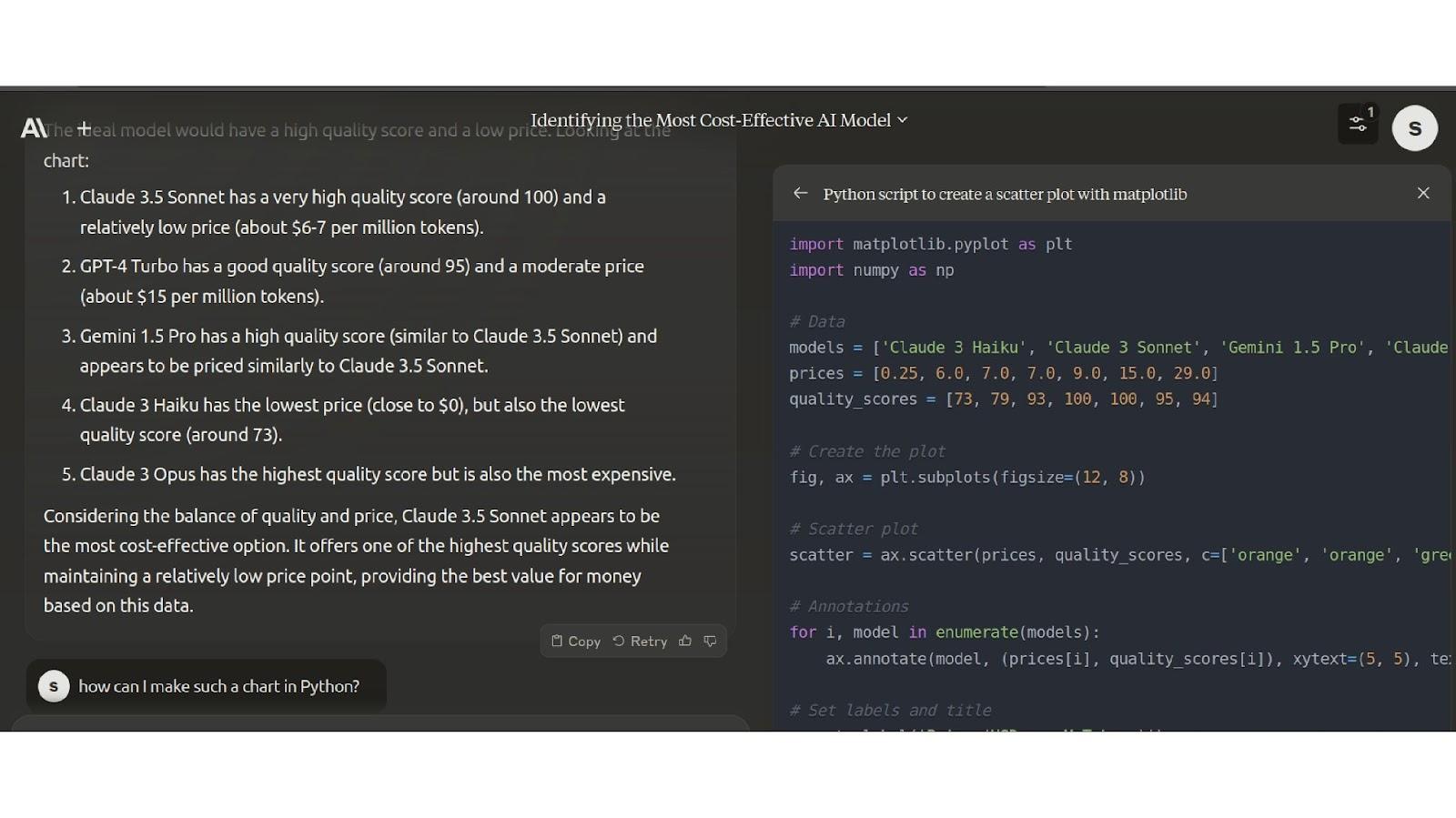
Right here, we have now given the ‘high quality vs worth’ chart taken from the above to the mannequin and requested it “Which mannequin is most cost-effective primarily based on this chart?”
As we are able to see from the picture, it solutions the query appropriately.
Then, we requested, “How can I make such a chart in Python?”. The mannequin generated the code and displayed it on the aspect.
We will allow the artifact function in ‘function preview’ if it isn’t already enabled.
And Claude 3.5 Sonnet can even acknowledge that the chart is displaying it’s the best-performing mannequin.
Methods to Use?
Claude 3.5 Sonnet is the default mannequin in Claude.ai chat. Within the free model, there are limits on the variety of messages per day which might differ relying on the visitors. If we are able to improve to Professional, we are able to additionally get entry to Claude 3 Haiku and Opus fashions.
We will additionally entry the mannequin via Anthropic API. It prices $3 / 1 Million tokens, and $15 / 1 Million tokens for enter and output respectively.
Security and Privateness
All fashions bear in depth testing to attenuate misuse. Regardless of its leap in intelligence, Claude 3.5 Sonnet maintains an ASL-2 security degree, verified via rigorous purple teaming assessments. All present LLMs seem like ASL-2.
Claude 3.5 Sonnet was evaluated by the UK’s Synthetic Intelligence Security Institute, earlier than deployment, with outcomes shared with the US AI Security Institute.
Suggestions from coverage consultants and organizations like Thorn has been built-in to deal with rising misuse tendencies. These insights have helped refine classifiers and enhance mannequin resilience towards varied abuses.
This mannequin doesn’t use user-submitted knowledge for coaching generative fashions until explicitly permitted by the person, guaranteeing strong safety of person privateness.
Conclusion
Just like the Claude 3 household, Haiku and Opus fashions can be launched quickly. Along with that options like reminiscence, and new modalities are prone to be added. And naturally, anticipate new fashions from OpenAI and Google as competitors heats up.
Incessantly Requested Questions
A. It’s Anthropic’s newest AI mannequin, excelling in arithmetic, reasoning, coding, and multilingual duties.
A. It leads in varied metrics resembling GPQA, MMLU, MATH, HumanEval, MGSM, DROP, BIG-Bench Laborious, and GSM8K.
A. It Excels in visible reasoning, decoding charts and graphs, and transcribing textual content from imperfect pictures.
[ad_2]