[ad_1]
Massive language fashions (LLMs) have considerably superior the sector of pure language processing (NLP). These fashions, famend for his or her means to generate and perceive human language, are utilized in varied domains resembling chatbots, translation providers, and content material creation. Steady improvement on this subject goals to boost the effectivity and effectiveness of those fashions, making them extra responsive and correct for real-time functions.
A serious problem LLMs face is the substantial computational value and time required for inference. As these fashions improve, producing every token throughout autoregressive duties turns into slower, impeding real-time functions. Addressing this challenge is essential to bettering functions’ efficiency and person expertise counting on LLMs, significantly when fast responses are important.
Present strategies to alleviate this challenge embody speculative sampling strategies, which generate and confirm tokens in parallel to scale back latency. Conventional speculative sampling strategies typically depend on static draft timber that don’t account for context, resulting in inefficiencies and suboptimal acceptance charges of draft tokens. These strategies goal to scale back inference time however nonetheless face limitations in efficiency.
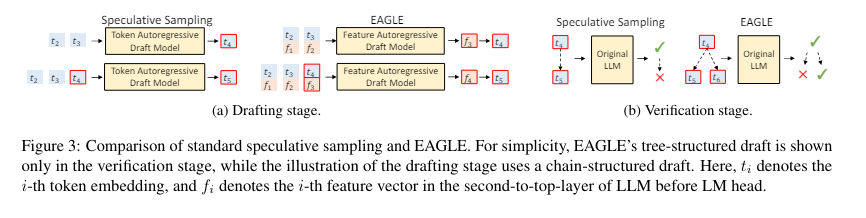

Researchers from Peking College, Microsoft Analysis, the College of Waterloo and Vector Institute launched EAGLE-2, a way leveraging a context-aware dynamic draft tree to boost speculative sampling. EAGLE-2 builds upon the earlier EAGLE technique, providing important enhancements in pace whereas sustaining the standard of generated textual content. This technique dynamically adjusts the draft tree primarily based on context, utilizing confidence scores from the draft mannequin to approximate acceptance charges.
EAGLE-2 dynamically adjusts the draft tree primarily based on context, enhancing speculative sampling. Its methodology consists of two major phases: enlargement and reranking. The method begins with the enlargement part, the place the draft mannequin inputs essentially the most promising nodes from the most recent layer of the draft tree to kind the following layer. Confidence scores from the draft mannequin approximate acceptance charges, permitting environment friendly prediction and verification of tokens. Throughout the reranking part, tokens with increased acceptance possibilities are chosen for the unique LLM’s enter throughout verification. This two-phase strategy ensures the draft tree adapts to the context, considerably bettering token acceptance charges and general effectivity. This technique eliminates the necessity for a number of ahead passes, thus accelerating the inference course of with out compromising the standard of the generated textual content.
The proposed technique confirmed exceptional outcomes. As an illustration, in multi-turn conversations, EAGLE-2 achieved a speedup of roughly 4.26x, whereas in code technology duties, it reached as much as 5x. The typical variety of tokens generated per drafting-verification cycle was considerably increased than different strategies, roughly twice that of ordinary speculative sampling. This efficiency increase makes EAGLE-2 a invaluable device for real-time NLP functions.
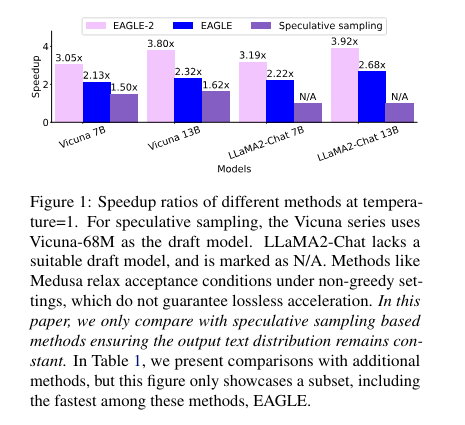
Efficiency evaluations additionally present that EAGLE-2 achieves speedup ratios between 3.05x and 4.26x throughout varied duties and LLMs, outperforming the earlier EAGLE technique by 20%-40%. It maintains the distribution of the generated textual content, making certain no loss within the output high quality regardless of the elevated pace. EAGLE-2 demonstrated the perfect efficiency in in depth checks throughout six duties and three collection of LLMs, confirming its robustness and effectivity.
In conclusion, EAGLE-2 successfully addresses computational inefficiencies in LLM inference by introducing a context-aware dynamic draft tree. This technique presents a considerable efficiency increase with out compromising the standard of the generated textual content, making it a major development in NLP. Future analysis and functions ought to think about integrating dynamic context changes to boost the efficiency of LLMs additional.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular knowledge with the primary compound AI system, Gretel Navigator, now usually out there! [Advertisement]
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]