[ad_1]
Massive Language Fashions (LLMs) have demonstrated outstanding talents in tackling varied reasoning duties expressed in pure language, together with math phrase issues, code technology, and planning. Nevertheless, because the complexity of reasoning duties will increase, even essentially the most superior LLMs wrestle with errors, hallucinations, and inconsistencies because of their auto-regressive nature. This problem is especially evident in duties requiring a number of reasoning steps, the place LLMs’ “System 1” considering—quick and instinctive however much less correct—falls brief. The necessity for extra deliberative, logical “System 2” considering turns into essential for fixing complicated reasoning issues precisely and constantly.
A number of makes an attempt have been made to beat the challenges confronted by LLMs in complicated reasoning duties. Supervised Fantastic-Tuning (SFT) and Reinforcement Studying from Human Suggestions (RLHF) purpose to align LLM outputs with human expectations. Direct Desire Optimization (DPO) and Aligner strategies have additionally been developed to enhance alignment. Within the realm of enhancing LLMs with planning capabilities, Tree-of-Ideas (ToT), A* search, and Monte Carlo Tree Search (MCTS) have been utilized. For math reasoning and code technology, methods equivalent to immediate engineering, fine-tuning with task-specific corpora, and coaching reward fashions have been explored. Nevertheless, these strategies usually require intensive experience, important computational sources, or task-specific modifications, limiting their generalizability and effectivity.
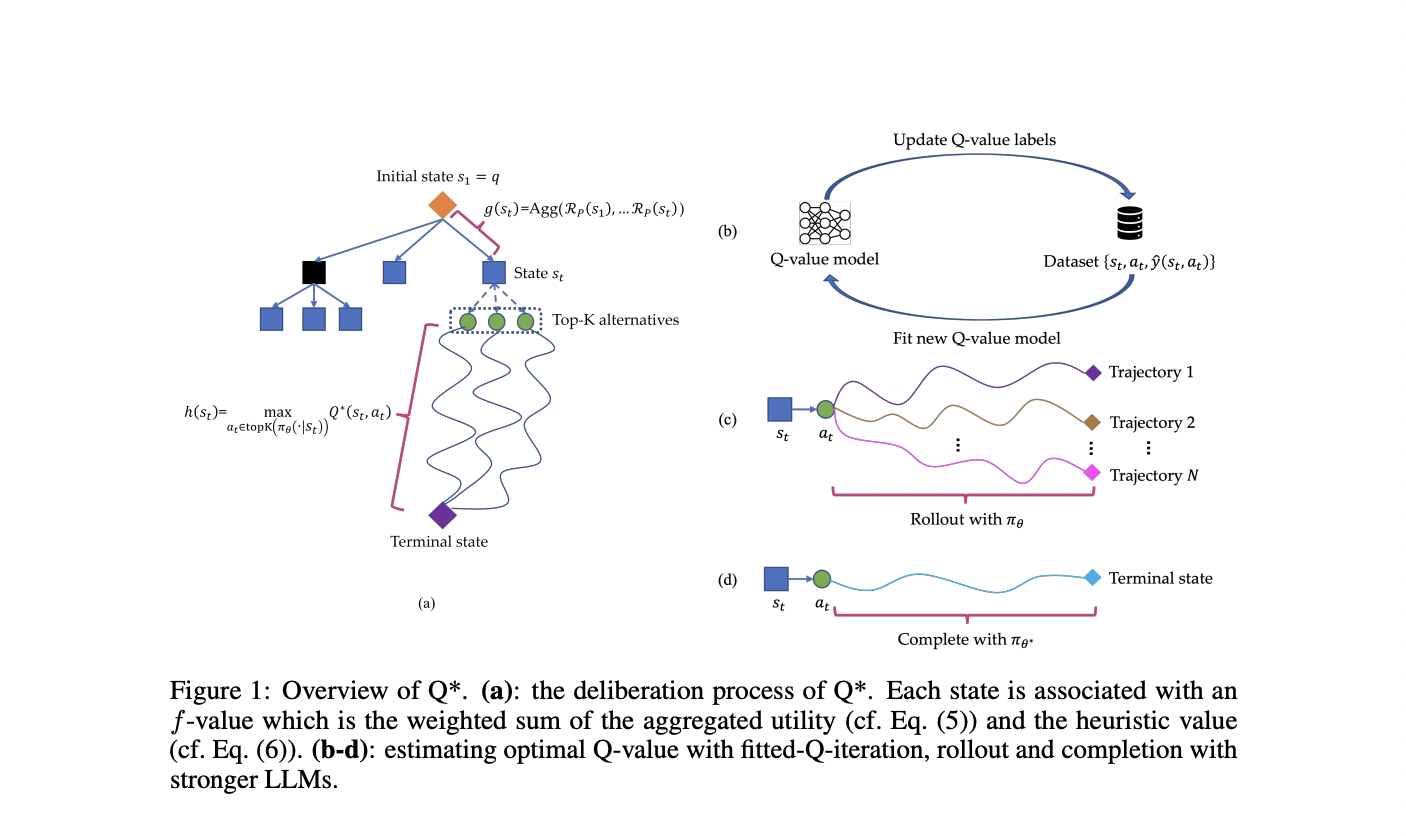
Researchers from Skywork AI and Nanyang Technological College current Q*, a sturdy framework designed to boost the multi-step reasoning capabilities of LLMs by deliberative planning. This strategy formalizes LLM reasoning as a Markov Choice Course of (MDP), the place the state combines the enter immediate and former reasoning steps, the motion represents the subsequent reasoning step, and the reward measures process success. Q* introduces basic strategies for estimating optimum Q-values of state-action pairs, together with offline reinforcement studying, finest sequence choice from rollouts, and completion utilizing stronger LLMs. By framing multi-step reasoning as a heuristic search downside, Q* employs plug-and-play Q-value fashions as heuristic features inside an A* search framework, guiding LLMs to pick essentially the most promising subsequent steps effectively.
The Q* framework employs a classy structure to boost LLMs’ multi-step reasoning capabilities. It formalizes the method as a heuristic search downside, using an A* search algorithm. The framework associates every state with an f-value, computed as a weighted sum of aggregated utility and a heuristic worth. The aggregated utility is calculated utilizing a process-based reward perform, whereas the heuristic worth is estimated utilizing the optimum Q-value of the state. Q* introduces three strategies for estimating optimum Q-values: offline reinforcement studying, studying from rollouts, and approximation utilizing stronger LLMs. These strategies allow the framework to be taught from coaching information with out task-specific modifications. The deliberative planning course of follows an A* search algorithm. It maintains two units of states: unvisited and visited. The algorithm iteratively selects the state with the very best f-value from the unvisited set, expands it utilizing the LLM coverage, and updates each units accordingly. This course of continues till a terminal state (full trajectory) is reached, at which level the reply is extracted from the ultimate state.
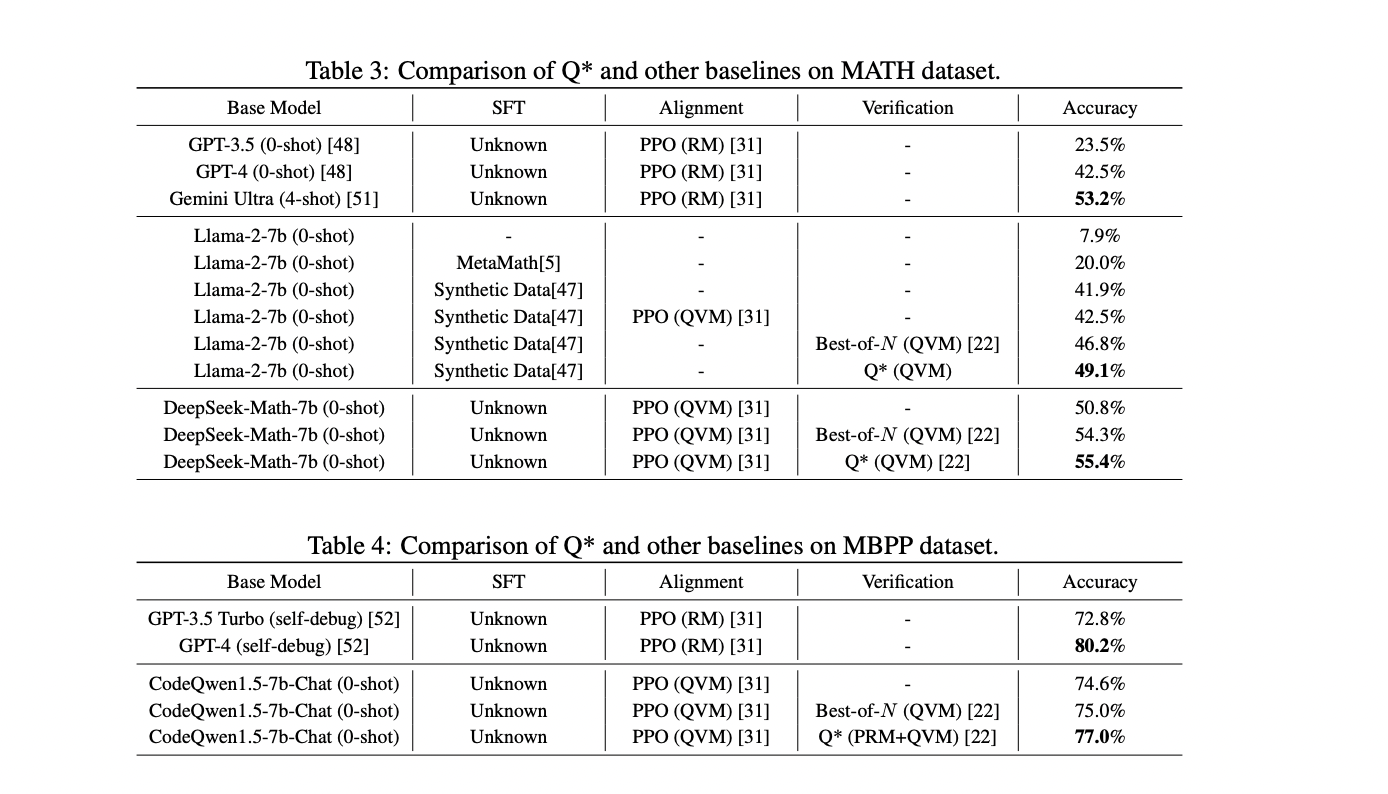
Q* demonstrated important efficiency enhancements throughout varied reasoning duties. On the GSM8K dataset, it enhanced Llama-2-7b to realize 80.8% accuracy, surpassing ChatGPT-turbo. For the MATH dataset, Q* improved Llama-2-7b and DeepSeekMath-7b, reaching 55.4% accuracy, outperforming fashions like Gemini Extremely (4-shot). In code technology, Q* boosted CodeQwen1.5-7b-Chat to 77.0% accuracy on the MBPP dataset. These outcomes constantly present Q*’s effectiveness in enhancing LLM efficiency throughout math reasoning and code technology duties, outperforming conventional strategies and a few closed-source fashions.
Q* emerges as an efficient technique to beat the problem of multi-step reasoning in LLMs by introducing a sturdy deliberation framework. This strategy enhances LLMs’ skill to resolve complicated issues that require in-depth, logical considering past easy auto-regressive token technology. Not like earlier strategies that depend on task-specific utility features, Q* makes use of a flexible Q-value mannequin skilled solely on ground-truth information, making it simply adaptable to varied reasoning duties with out modifications. The framework employs plug-and-play Q-value fashions as heuristic features, guiding LLMs successfully with out the necessity for task-specific fine-tuning, thus preserving efficiency throughout numerous duties. Q*’s agility stems from its single-step consideration strategy, contrasting with extra computationally intensive strategies like MCTS. In depth experiments in math reasoning and code technology exhibit Q*’s superior efficiency, highlighting its potential to enhance LLMs’ complicated problem-solving capabilities considerably.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular information with the primary compound AI system, Gretel Navigator, now usually accessible! [Advertisement]
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]