[ad_1]
Till now, the vast majority of the world’s knowledge transformations have been carried out on prime of information warehouses, question engines, and different databases that are optimized for storing a lot of knowledge and querying them for analytics sometimes. These options have labored effectively for the batch ELT world over the previous decade, the place knowledge groups are used to coping with knowledge that’s solely sometimes refreshed and analytics queries that may take minutes and even hours to finish.
The world, nevertheless, is shifting from batch to real-time, and knowledge transformations aren’t any exception.
Each knowledge freshness and question latency necessities have gotten increasingly strict, with trendy knowledge purposes and operational analytics necessitating recent knowledge that by no means will get stale. With the velocity and scale at which new knowledge is consistently being generated in right now’s real-time world, such analytics primarily based on knowledge that’s days, hours, and even minutes outdated might now not be helpful. Complete analytics require extraordinarily strong knowledge transformations, which is difficult and costly to make real-time when your knowledge is residing in applied sciences not optimized for real-time analytics.
Introducing dbt Core + Rockset
Again in July, we launched our dbt-Rockset adapter for the primary time which introduced real-time analytics to dbt, an immensely standard open-source knowledge transformation software that lets groups shortly and collaboratively deploy analytics code to ship greater high quality knowledge units. Utilizing the adapter, you may now load knowledge into Rockset and create collections by writing SQL SELECT statements in dbt. These collections might then be constructed on prime of each other to assist extremely advanced knowledge transformations with many dependency edges.
At present, we’re excited to announce the primary main replace to our dbt-Rockset adapter which now helps all 4 core dbt materializations:
With this beta launch, now you can carry out the entire hottest workflows utilized in dbt for performing real-time knowledge transformations on Rockset. This comes on the heels of our newest product releases round extra accessible and inexpensive real-time analytics with Rollups on Streaming Information and Rockset Views.
Actual-Time Streaming ELT Utilizing dbt + Rockset
As knowledge is ingested into Rockset, we are going to mechanically index it utilizing Rockset’s Converged Index™ know-how, carry out any write-time knowledge transformations you outline, after which make that knowledge queryable inside seconds. Then, while you execute queries on that knowledge, we are going to leverage these indexes to finish any read-time knowledge transformations you outline utilizing dbt with sub-second latency.
Let’s stroll by way of an instance workflow for establishing real-time streaming ELT utilizing dbt + Rockset:
Write-Time Information Transformations Utilizing Rollups and Discipline Mappings
Rockset can simply extract and cargo semi-structured knowledge from a number of sources in real-time. For prime velocity knowledge, mostly coming from knowledge streams, you may roll it up at write-time. As an example, let’s say you’ve streaming knowledge coming in from Kafka or Kinesis. You’ll create a Rockset assortment for every knowledge stream, after which arrange SQL-Based mostly Rollups to carry out transformations and aggregations on the info as it’s written into Rockset. This may be useful while you need to scale back the scale of huge scale knowledge streams, deduplicate knowledge, or partition your knowledge.
Collections can be created from different knowledge sources together with knowledge lakes (e.g. S3 or GCS), NoSQL databases (e.g. DynamoDB or MongoDB), and relational databases (e.g. PostgreSQL or MySQL). You’ll be able to then use Rocket’s SQL-Based mostly Discipline Mappings to rework the info utilizing SQL statements as it’s written into Rockset.
Learn-Time Information Transformations Utilizing Rockset Views
There’s solely a lot complexity you may codify into your knowledge transformations throughout write-time, so the subsequent factor you’ll need to attempt is utilizing the adapter to arrange knowledge transformations as SQL statements in dbt utilizing the View Materialization that may be carried out throughout read-time.
Create a dbt mannequin utilizing SQL statements for every transformation you need to carry out in your knowledge. Once you execute dbt run, dbt will mechanically create a Rockset View for every dbt mannequin, which is able to carry out all the info transformations when queries are executed.
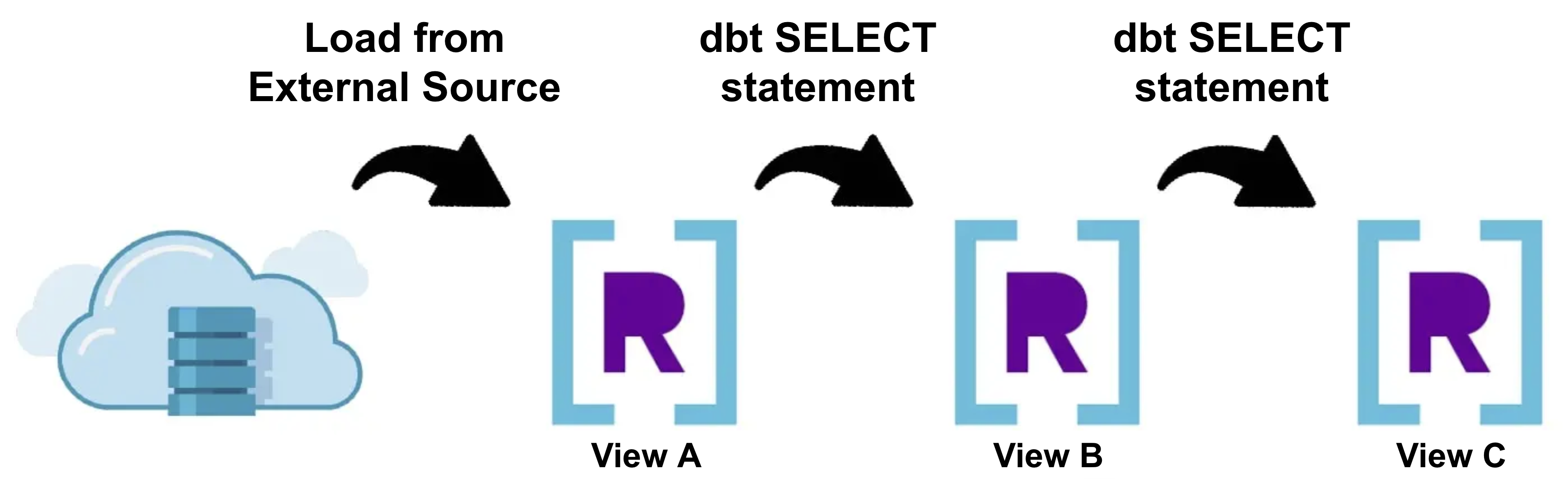
Should you’re in a position to match your entire transformation into the steps above and queries full inside your latency necessities, then you’ve achieved the gold customary of real-time knowledge transformations: Actual-Time Streaming ELT.
That’s, your knowledge will probably be mechanically stored up-to-date in real-time, and your queries will at all times replicate probably the most up-to-date supply knowledge. There isn’t a want for periodic batch updates to “refresh” your knowledge. In dbt, which means that you’ll not have to execute dbt run once more after the preliminary setup except you need to make modifications to the precise knowledge transformation logic (e.g. including or updating dbt fashions).
Persistent Materializations Utilizing dbt + Rockset
If utilizing solely write-time transformations and views is just not sufficient to satisfy your utility’s latency necessities or your knowledge transformations develop into too advanced, you may persist them as Rockset collections. Be mindful Rockset additionally requires queries to finish in beneath 2 minutes to cater to real-time use instances, which can have an effect on you in case your read-time transformations are too involuted. Whereas this requires a batch ELT workflow because you would wish to manually execute dbt run every time you need to replace your knowledge transformations, you need to use micro-batching to run dbt extraordinarily often to maintain your remodeled knowledge up-to-date in close to real-time.
An important benefits to utilizing persistent materializations is that they’re each quicker to question and higher at dealing with question concurrency, as they’re materialized as collections in Rockset. For the reason that bulk of the info transformations have already been carried out forward of time, your queries will full considerably quicker since you may decrease the complexity essential throughout read-time.
There are two persistent materializations obtainable in dbt: incremental and desk.
Materializing dbt Incremental Fashions in Rockset
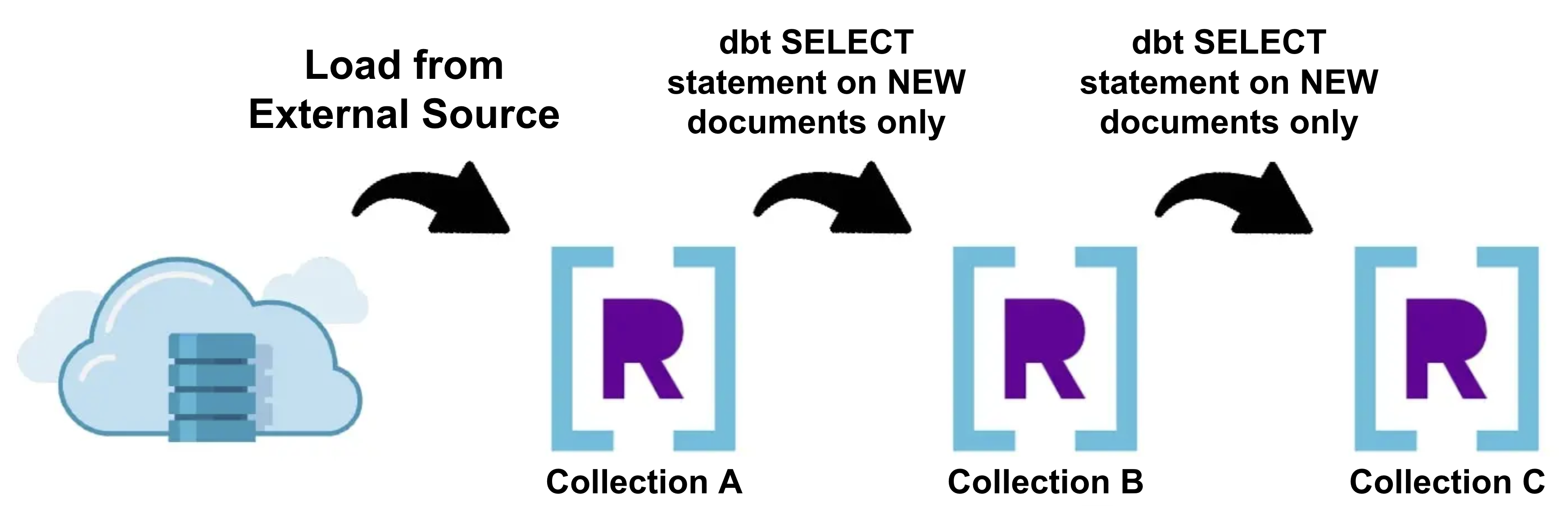
Incremental Fashions are a sophisticated idea in dbt which let you insert or replace paperwork right into a Rockset assortment for the reason that final time dbt was run. This will considerably scale back the construct time since we solely have to carry out transformations on the brand new knowledge that was simply generated, somewhat than dropping, recreating, and performing transformations on everything of the info.
Relying on the complexity of your knowledge transformations, incremental materializations might not at all times be a viable possibility to satisfy your transformation necessities. Incremental materializations are normally greatest fitted to occasion or time-series knowledge streamed immediately into Rockset. To inform dbt which paperwork it ought to carry out transformations on throughout an incremental run, merely present SQL that filters for these paperwork utilizing the is_incremental() macro in your dbt code. You’ll be able to study extra about configuring incremental fashions in dbt right here.
Materializing dbt Desk Fashions in Rockset

Desk Fashions in dbt are transformations which drop and recreate whole Rockset collections with every execution of dbt run with a view to replace that assortment’s remodeled knowledge with probably the most up-to-date supply knowledge. That is the best method to persist remodeled knowledge in Rockset, and leads to a lot quicker queries for the reason that transformations are accomplished prior to question time.
However, the most important disadvantage to utilizing desk fashions is that they are often sluggish to finish since Rockset is just not optimized for creating solely new collections from scratch on the fly. This may occasionally trigger your knowledge latency to extend considerably as it might take a number of minutes for Rockset to provision sources for a brand new assortment after which populate it with remodeled knowledge.
Placing It All Collectively

Understand that with each desk fashions and incremental fashions, you may at all times use them along with Rockset views to customise the right stack with a view to meet the distinctive necessities of your knowledge transformations. For instance, you would possibly use SQL-based rollups to first remodel your streaming knowledge throughout write-time, remodel and persist them into Rockset collections by way of incremental or desk fashions, after which execute a sequence of view fashions throughout read-time to rework your knowledge once more.
Beta Associate Program
The dbt-Rockset adapter is totally open-sourced, and we’d love your enter and suggestions! Should you’re serious about getting in contact with us, you may join right here to affix our beta associate program for the dbt-Rockset adapter, or discover us on the dbt Slack neighborhood within the #db-rockset channel. We’re additionally internet hosting an workplace hours on October twenty sixth at 10am PST the place we’ll present a reside demo of real-time transformations and reply any technical questions. Hope you may be a part of us for the occasion!
[ad_2]