[ad_1]
Giant language fashions (LLMs) have gained vital consideration for his or her capacity to retailer huge quantities of factual information inside their weights throughout pretraining. This functionality has led to promising ends in knowledge-intensive duties, significantly factual question-answering. Nevertheless, a vital problem persists: LLMs typically generate believable however incorrect responses to queries, undermining their reliability. This inconsistency in factual accuracy poses a major hurdle within the widespread adoption and belief of LLMs for knowledge-based purposes. Researchers are grappling with the problem of enhancing the factuality of LLM outputs whereas sustaining their versatility and generative capabilities. The issue is additional difficult by the remark that even when LLMs possess the right info, they might nonetheless produce inaccurate solutions, suggesting underlying points in information retrieval and utility.
Researchers have tried varied approaches to enhance factuality in LLMs. Some research concentrate on the influence of unfamiliar examples throughout fine-tuning, revealing that these can doubtlessly worsen factuality because of overfitting. Different approaches look at the reliability of factual information, exhibiting LLMs typically underperform on obscure info. Strategies to boost factuality embody manipulating consideration mechanisms, utilizing unsupervised inside probes, and creating strategies for LLMs to abstain from answering unsure questions. Some researchers have launched fine-tuning methods to encourage LLMs to refuse questions outdoors their information boundaries. Additionally, research have investigated LLM mechanisms and coaching dynamics, inspecting how details are saved and extracted, and analyzing pretraining dynamics of syntax acquisition and a spotlight patterns. Regardless of these efforts, challenges in attaining constant factual accuracy persist.
On this examine, researchers from the Division of Machine Studying, at Carnegie Mellon College and the Division of Pc Science, at Stanford College discovered that the influence of fine-tuning examples on LLMs relies upon critically on how effectively the details are encoded within the pre-trained mannequin. Nice-tuning on well-encoded details considerably improves factuality, whereas utilizing much less well-encoded details can hurt efficiency. This phenomenon happens as a result of LLMs can both use memorized information or depend on common “shortcuts” to reply questions. The composition of fine-tuning knowledge determines which mechanism is amplified. Effectively-known details reinforce the usage of memorized information, whereas much less acquainted details encourage shortcut utilization. This perception gives a brand new perspective on enhancing LLM factuality via strategic number of fine-tuning knowledge.
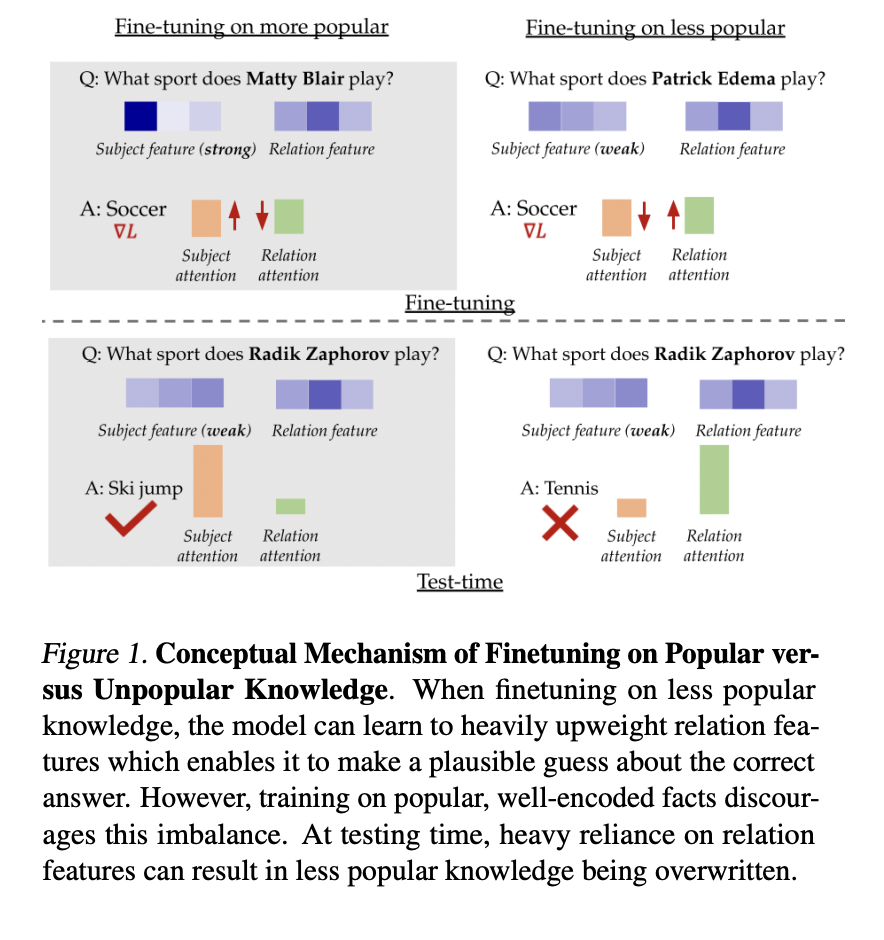
The tactic makes use of an artificial setup to check the influence of fine-tuning knowledge on LLM factuality. This setup simulates a simplified token house for topics, relations, and solutions, with completely different formatting between pretraining and downstream duties. Pretraining samples are drawn from a Zipf distribution for topics and a uniform distribution for relations. Key findings reveal that fine-tuning widespread details considerably improves factuality, with results amplified for much less widespread entities. The examine examines the affect of the Zipf distribution parameter and pretraining steps on this phenomenon. These observations result in the idea of “reality salience,” representing how effectively a mannequin is aware of a reality, which influences fine-tuning habits and downstream efficiency. This artificial strategy permits for a managed investigation of pretraining processes that might be impractical with actual giant language fashions.
Experimental outcomes throughout a number of datasets (PopQA, Entity-Questions, and MMLU) and fashions (Llama-7B and Mistral) persistently present that fine-tuning on much less widespread or much less assured examples underperforms in comparison with utilizing widespread information. This efficiency hole widens for much less widespread take a look at factors, supporting the speculation that much less widespread details are extra delicate to fine-tuning decisions. Surprisingly, even randomly chosen subsets outperform fine-tuning on the least widespread information, suggesting that together with some widespread details can mitigate the destructive influence of much less widespread ones. Additionally, coaching on a smaller subset of the most well-liked details typically performs comparably or higher than utilizing your complete dataset. These findings point out that cautious number of fine-tuning knowledge, specializing in well-known details, can result in improved factual accuracy in LLMs, doubtlessly permitting for extra environment friendly and efficient coaching processes.

The examine gives vital insights into enhancing language mannequin factuality via strategic QA dataset composition. Opposite to intuitive assumptions, finetuning on well-known details persistently enhances general factuality. This discovering, noticed throughout varied settings and supported by a conceptual mannequin, challenges standard approaches to QA dataset design. The analysis opens new avenues for enhancing language mannequin efficiency, suggesting potential advantages in regularization methods to beat consideration imbalance, curriculum studying methods, and the event of artificial knowledge for environment friendly information extraction. These findings present a basis for future work aimed toward enhancing the factual accuracy and reliability of language fashions in various purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]