[ad_1]
Giant language fashions (LLMs) now help very lengthy context home windows, however the quadratic complexity of normal consideration ends in considerably extended Time-to-First-Token (TTFT) latency. Current strategies to sort out this complexity require additional pretraining or finetuning and sometimes compromise mannequin accuracy. The quadratic nature of the vanilla consideration mechanism in these fashions considerably will increase computational time, making real-time interactions difficult. Present options normally compromise mannequin accuracy or require extra pretraining, which is commonly impractical.
Present strategies to mitigate the quadratic complexity of consideration in LLMs embrace sparse consideration, low-rank matrices, unified sparse and low-rank consideration, recurrent states, and exterior reminiscence. These approaches purpose to approximate dense consideration or handle reminiscence extra effectively. Nevertheless, they usually necessitate extra pretraining or finetuning, resulting in accuracy losses and impracticality for pre-trained fashions.
A group of researchers from China proposed SampleAttention, an adaptive structured sparse consideration mechanism. SampleAttention leverages important sparse patterns noticed in consideration mechanisms to seize important info with minimal overhead. It attends to a set share of adjoining tokens to deal with native window patterns. It employs a two-stage query-guided key-value (KV) filtering method to seize column stripe patterns. This methodology presents near-lossless sparse consideration, seamlessly integrating into off-the-shelf LLMs with out compromising accuracy.
SampleAttention addresses the excessive TTFT latency by dynamically capturing head-specific sparse patterns throughout runtime with low overhead. The strategy focuses on two main sparse patterns: native window patterns and column stripe patterns. Native window patterns are dealt with by attending to a set share of adjoining tokens, guaranteeing that vital native dependencies are captured effectively. Column stripe patterns are managed by way of a two-stage query-guided KV filtering method, which adaptively selects a minimal set of key-values to keep up low computational overhead.
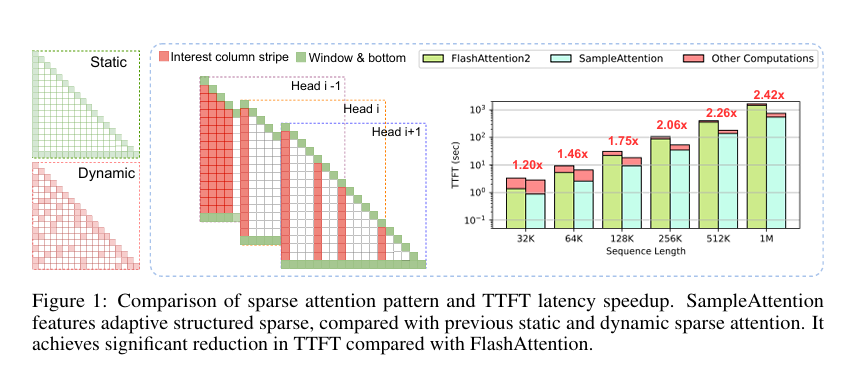
The proposed methodology was evaluated on extensively used LLM variants like ChatGLM2-6B and internLM2-7B, demonstrating its effectiveness in long-context eventualities. SampleAttention confirmed important efficiency enhancements, lowering TTFT by as much as 2.42 occasions in comparison with FlashAttention. The evaluations included duties comparable to LongBench, BABILong, and the “Needle in a Haystack” stress take a look at, the place SampleAttention maintained practically no accuracy loss whereas considerably accelerating consideration operations.
This analysis successfully addresses the issue of excessive TTFT latency in LLMs with lengthy context home windows by introducing SampleAttention. This adaptive structured sparse consideration methodology reduces computational overhead whereas sustaining accuracy, offering a sensible resolution for integrating into pre-trained fashions. The mixture of native window and column stripe patterns ensures environment friendly dealing with of important info, making SampleAttention a promising development for real-time functions of LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 46k+ ML SubReddit
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech on the Indian Institute of Expertise (IIT), Bhubaneswar. An AI fanatic, she enjoys staying up to date on the most recent developments. Shreya is especially within the real-life functions of cutting-edge know-how, particularly within the subject of knowledge science.
[ad_2]