[ad_1]
Pure language processing (NLP) drives researchers to develop algorithms that allow computer systems to grasp, interpret, and generate human languages. These efforts cowl varied purposes, similar to machine translation, sentiment evaluation, and clever conversational brokers. The issue considerations the inefficiencies and limitations of tokenizers utilized in giant language fashions (LLMs). Tokenizers, which break down textual content into subwords, require substantial computational sources and in depth coaching. Moreover, they usually lead to giant, inefficient vocabularies with many near-duplicate tokens. These inefficiencies are notably problematic for underrepresented languages, the place efficiency may very well be improved considerably.
Conventional strategies like Byte Pair Encoding (BPE) and Unigram tokenizers create vocabularies primarily based on statistical frequencies in a reference corpus. BPE merges frequent token pairs, whereas Unigram removes the least influential tokens iteratively. Each strategies are computationally intensive and result in giant vocabularies, which may very well be extra environment friendly and vulnerable to containing many redundant tokens.
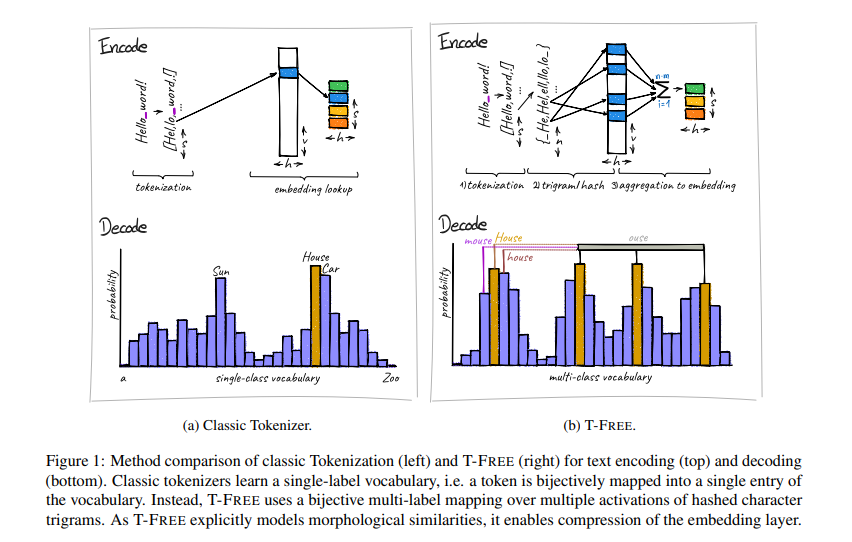
Researchers from Aleph Alpha, the Technical College of Darmstadt, the Hessian Middle for Synthetic Intelligence, and the German Middle for Synthetic Intelligence have launched a novel method referred to as T-FREE. This tokenizer-free technique embeds phrases straight by way of sparse activation patterns over character triplets, eliminating the necessity for conventional subword tokens. This new technique considerably reduces the scale of embedding layers and improves efficiency throughout languages.
T-FREE makes use of hashed character triplets to characterize every phrase within the enter textual content, capturing morphological similarities between phrases and permitting for environment friendly compression of the embedding layers. By modeling character overlaps, T-FREE maintains near-optimal efficiency throughout totally different languages while not having a pre-trained vocabulary. This method addresses the inefficiencies and limitations of conventional tokenizers, providing a extra streamlined and efficient technique for textual content encoding in LLMs.
The experimental analysis of T-FREE demonstrated vital enhancements over conventional tokenizers. Researchers achieved aggressive downstream efficiency with a parameter discount of greater than 85% on textual content encoding layers. T-FREE additionally confirmed substantial enhancements in cross-lingual switch studying. T-FREE outperformed conventional tokenizers in benchmark assessments, highlighting its effectiveness and effectivity in dealing with numerous languages and duties. As an illustration, fashions utilizing T-FREE achieved higher leads to German after solely 20,000 further coaching steps, practically reaching the efficiency ranges of English-trained fashions. As compared, conventional tokenizers confirmed minimal enchancment with the identical quantity of coaching.
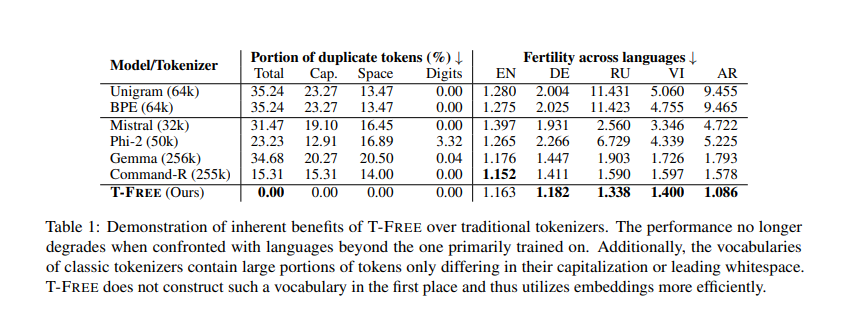
Detailed evaluations included hyperparameter ablations on 1 billion parameter fashions, revealing that T-FREE might obtain aggressive scores with a considerably lowered vocabulary measurement. A vocabulary measurement of 8,000 entries was optimum, offering one of the best efficiency. In distinction, vocabulary sizes smaller than 2,000 resulted in vital efficiency drops. T-FREE’s design inherently eliminates duplicate tokens, additional enhancing effectivity and efficiency. T-FREE lowered the variety of parameters wanted by 20%, utilizing 2.77 billion parameters in comparison with 3.11 billion for conventional strategies.
T-FREE’s strong hashing perform for phrases and its potential to mannequin phrase similarities contribute to extra secure and environment friendly coaching dynamics. This method additionally reduces the computational prices related to pre-processing, coaching, and inference of LLMs. The design permits for specific modeling and steering of the decoding course of at inference time, doubtlessly lowering hallucinations and enabling dynamic changes to the out there dictionary.
In conclusion, T-FREE considerably advances textual content encoding for big language fashions. T-FREE addresses the most important drawbacks of present tokenization approaches by eliminating the necessity for conventional tokenizers and introducing a memory-efficient technique that leverages sparse representations. This new technique affords a promising resolution for extra environment friendly and efficient language modeling, notably benefiting underrepresented languages and lowering the general computational burden of LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]