[ad_1]
Introduction
Within the ever-evolving panorama of knowledge processing, extracting structured data from PDFs stays a formidable problem, even in 2024. Whereas quite a few fashions excel at question-answering duties, the actual complexity lies in remodeling unstructured PDF content material into organized, actionable knowledge. Let’s discover this problem and uncover how Indexify and PaddleOCR will be the instruments we’d like for seamlessly extracting textual content from PDFs.
Spoiler: We truly did remedy it! Hit cmd/ctrl+F and seek for the time period highlight to take a look at how!
PDF extraction is essential throughout varied domains. Let’s have a look at some frequent use instances:
- Invoices and Receipts: These paperwork differ extensively in format, containing complicated layouts, tables, and generally handwritten notes. Correct parsing is crucial for automating accounting processes.
- Tutorial Papers and Theses: These typically embody a mixture of textual content, graphs, tables, and formulation. The problem lies in accurately changing not simply textual content, but additionally mathematical equations and scientific notation.
- Authorized Paperwork: Contracts and courtroom filings are sometimes dense with formatting nuances. Sustaining the integrity of the unique formatting whereas extracting textual content is essential for authorized evaluations and compliance.
- Historic Archives and Manuscripts: These current distinctive challenges because of paper degradation, variations in historic handwriting, and archaic language. OCR know-how should deal with these variations for efficient analysis and archival functions.
- Medical Data and Prescriptions: These typically include crucial handwritten notes and medical terminology. Correct seize of this data is significant for affected person care and medical analysis.
Actually! Right here is the revised textual content in lively voice:
Indexify is an open-source knowledge framework that tackles the complexities of unstructured knowledge extraction from any supply, as proven in Fig 1. Its structure helps:
- Ingestion of tens of millions of unstructured knowledge factors.
- Actual-time extraction and indexing pipelines.
- Horizontal scaling to accommodate rising knowledge volumes.
- Fast extraction instances (inside seconds of ingestion).
- Versatile deployment throughout varied {hardware} platforms (GPUs, TPUs, and CPUs).

In case you are occupied with studying extra about indexify and how one can set it up for extraction, skim by our 2 minute ‘getting-started’ information.

On the coronary heart of Indexify are its Extractors (as proven in Fig 2) – compute features that rework unstructured knowledge or extract data from it. These Extractors will be applied to run on any {hardware}, with a single Indexify deployment supporting tens of 1000’s of Extractors in a cluster.
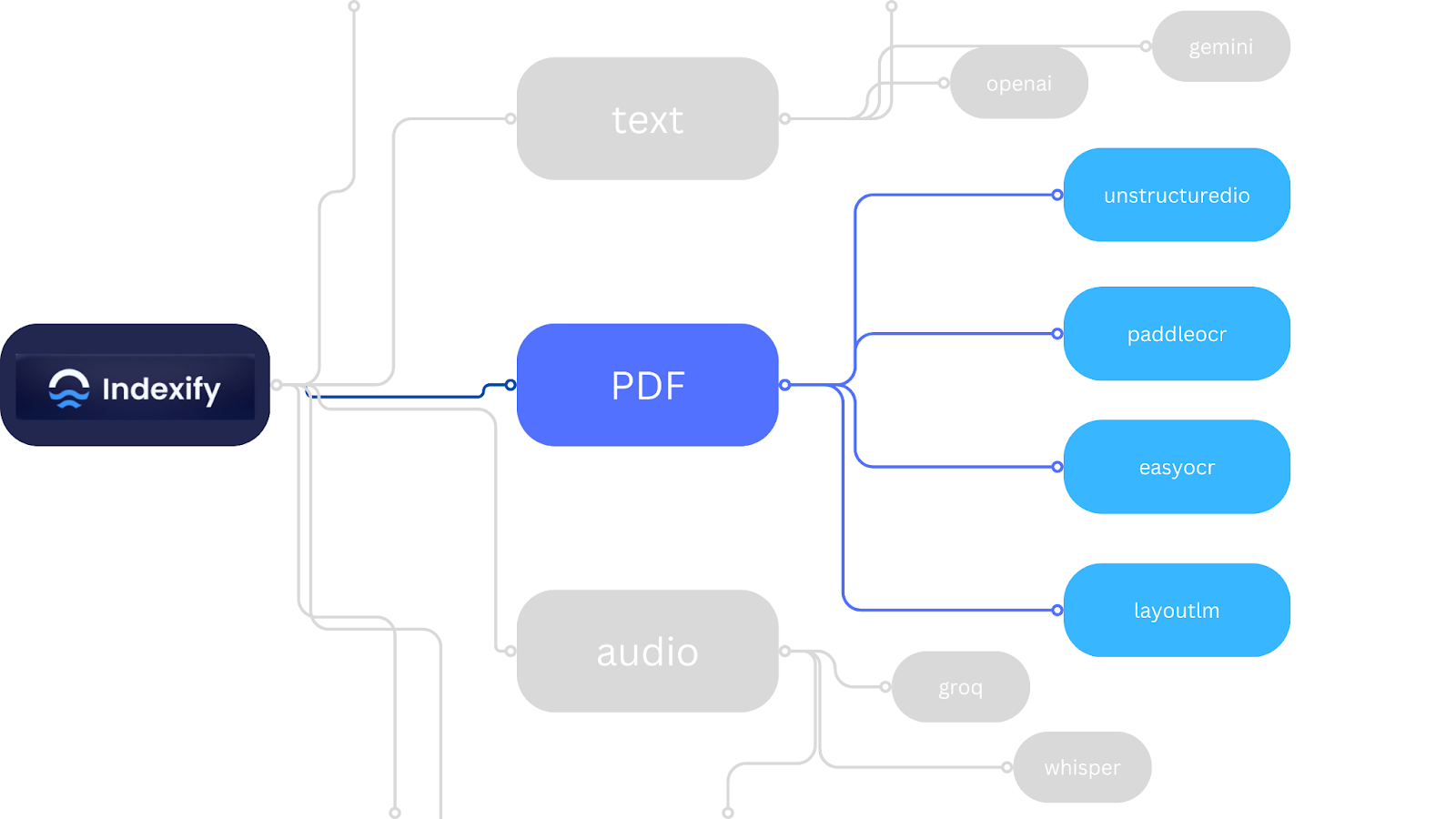
Because it stands indexify helps a number of extractor for a number of modalities (as proven in Fig 3). The total checklist of indexify extractors together with their use instances will be discovered within the documentation.
The PaddleOCR PDF Extractor, primarily based on the PaddleOCR library, is a strong instrument within the Indexify ecosystem. It integrates varied OCR algorithms for textual content detection (DB, EAST, SAST) and recognition (CRNN, RARE, StarNet, Rosetta, SRN).
Let’s stroll by organising and utilizing the PaddleOCR Extractor:
Right here is an instance of making a pipeline that extracts textual content, tables, and pictures from a PDF doc.
You’ll want three completely different terminals open to finish this tutorial:
- Terminal 1 to obtain and run the Indexify Server.
- Terminal 2 to run our Indexify extractors which can deal with structured extraction, chunking and embedding of ingested pages.
- Terminal 3 to run our python scripts to assist load and question knowledge from our Indexify server.
Step 1: Begin the Indexify Server
Let’s first begin by downloading the Indexify server and operating it.
Terminal 1
curl https://getindexify.ai | sh
./indexify server -dLet’s begin by creating a brand new digital setting earlier than putting in the required packages in our digital setting.
Terminal 2
python3 -m venv venv
supply venv/bin/activate
pip3 set up indexify-extractor-sdk indexifyWe are able to then run all obtainable extractors utilizing the command under.
!indexify-extractor obtain tensorlake/paddleocr_extractor
!indexify-extractor join-serverTerminal 3
!python3 -m venv venv
!supply venv/bin/activateCreate a python script defining the extraction graph and run it. Steps 3-5 on this sub-section ought to be a part of the identical python file that ought to be run after activating the venv in Terminal 3.
from indexify import IndexifyClient, ExtractionGraph
consumer = IndexifyClient()
extraction_graph_spec = """
title: 'pdflearner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
title: 'pdf_to_text'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
consumer.create_extraction_graph(extraction_graph)This code units up an extraction graph named ‘pdflearner’ that makes use of the PaddleOCR extractor to transform PDFs to textual content.
Step 4: Add PDFs out of your software
content_id = consumer.upload_file("pdflearner", "/path/to/pdf.file")consumer.wait_for_extraction(content_id)
extracted_content = consumer.get_extracted_content(content_id=content_id, graph_name="pdflearner", policy_name="pdf_to_text")
print(extracted_content)This snippet uploads a PDF, waits for the extraction to finish, after which retrieves and prints the extracted content material.
We didn’t imagine that it could possibly be a easy few-step course of to extract all of the textual data meaningfully. So we examined it out with a real-world tax bill ( as proven in Determine 4).
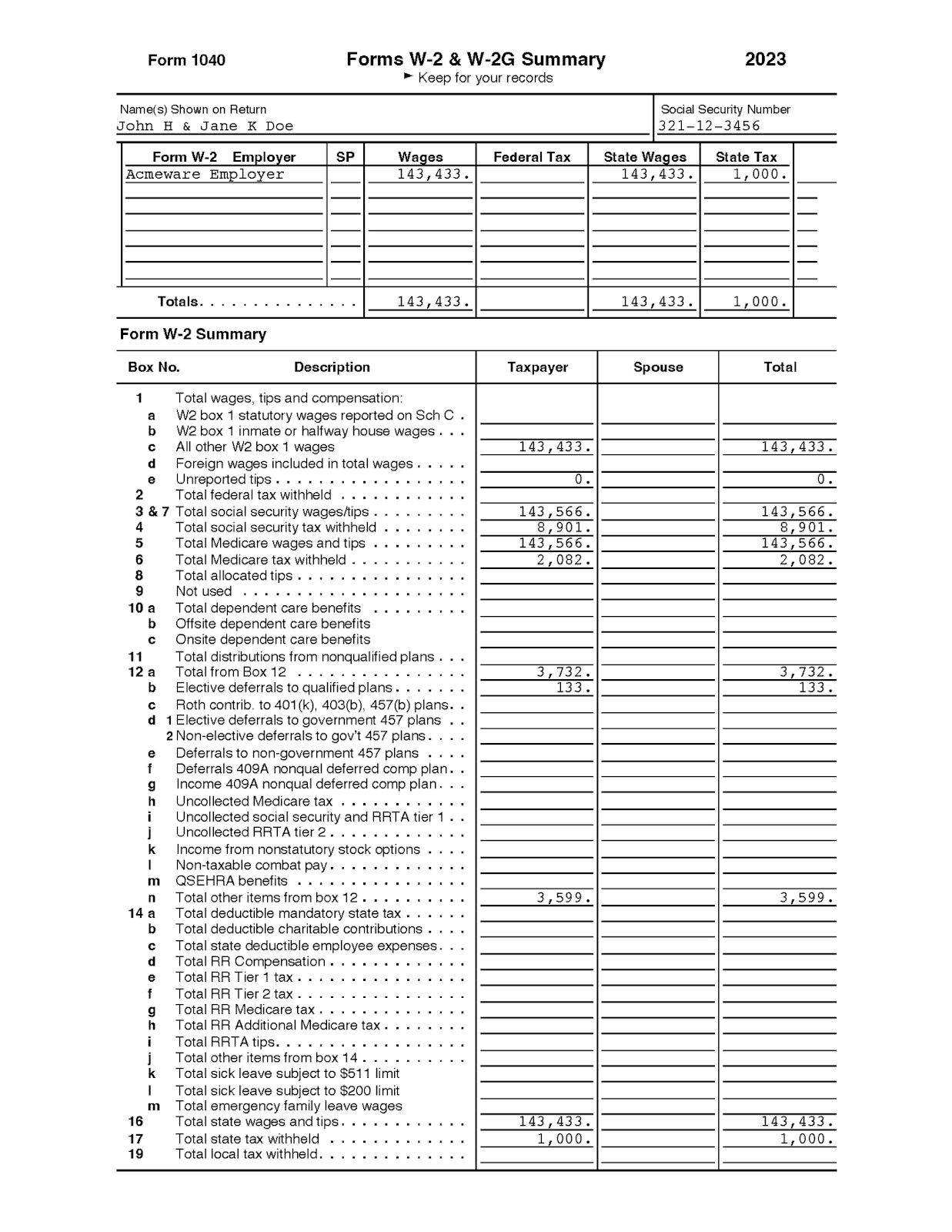
[Content(content_type="text/plain", data=b"Form 1040nForms W-2 & W-2G Summaryn2023nKeep for your recordsn Name(s) Shown on ReturnnSocial Security NumbernJohn H & Jane K Doen321-12-3456nEmployernSPnFederal TaxnState WagesnState TaxnForm W-2nWagesnAcmeware Employern143,433.n143,433.n1,000.nTotals.n143,433.n143,433.n1,000.nForm W-2 SummarynBox No.nDescriptionnTaxpayernSpousenTotalnTotal wages, tips and compensation:n1nanW2 box 1 statutory wages reported on Sch CnW2 box 1 inmate or halfway house wages .n6ncnAll other W2 box 1 wagesn143,433.n143,433.ndnForeign wages included in total wagesnen0.n0.n2nTotal federal tax withheldn 3 & 7 Total social security wages/tips .n143,566.n143,566.n4nTotal social security tax withheldn8,901.n8,901.n5nTotal Medicare wages and tipsn143,566.n143,566.n6nTotal Medicare tax withheld . :n2,082.n2,082.n8nTotal allocated tips .n9nNot usedn10 anTotal dependent care benefitsnbnOffsite dependent care benefitsncnOnsite dependent care benefitsn11n Total distributions from nonqualified plansn12 anTotal from Box 12n3,732.n3,732.nElective deferrals to qualified plansn133.n133.ncnRoth contrib. to 401(k), 403(b), 457(b) plans .n.n1 Elective deferrals to government 457 plansn2 Non-elective deferrals to gov't 457 plans .nenDeferrals to non-government 457 plansnfnDeferrals 409A nonqual deferred comp plan .n6nIncome 409A nonqual deferred comp plan .nhnUncollected Medicare tax :nUncollected social security and RRTA tier 1njnUncollected RRTA tier 2 . . .nknIncome from nonstatutory stock optionsnNon-taxable combat paynmnQSEHRA benefitsnTotal other items from box 12 .nnn3,599.n3,599.n14 an Total deductible mandatory state tax .nbnTotal deductible charitable contributionsncnTotal state deductible employee expenses .ndn Total RR Compensation .nenTotal RR Tier 1 tax .nfnTotal RR Tier 2 tax . -nTotal RR Medicare tax .ngnhnTotal RR Additional Medicare tax .ninTotal RRTA tips. : :njnTotal other items from box 14nknTotal sick leave subject to $511 limitnTotal sick leave subject to $200 limitnmnTotal emergency family leave wagesn16nTotal state wages and tips .n143,433.n143,433.n17nTotal state tax withheldn1,000.n1,000.n19nTotal local tax withheld .", features=[Feature(feature_type="metadata", name="metadata", value={'type': 'text'}, comment=None)], labels={})]
Whereas extracting textual content is beneficial, typically we have to parse this textual content into structured knowledge. Right here’s how you should utilize Indexify to extract particular fields out of your PDFs (the whole workflow is proven in Determine 5).
from indexify import IndexifyClient, ExtractionGraph, SchemaExtractorConfig, Content material, SchemaExtractor
consumer = IndexifyClient()
schema = {
'properties': {
'invoice_number': {'title': 'Bill Quantity', 'kind': 'string'},
'date': {'title': 'Date', 'kind': 'string'},
'account_number': {'title': 'Account Quantity', 'kind': 'string'},
'proprietor': {'title': 'Proprietor', 'kind': 'string'},
'tackle': {'title': 'Deal with', 'kind': 'string'},
'last_month_balance': {'title': 'Final Month Steadiness', 'kind': 'string'},
'current_amount_due': {'title': 'Present Quantity Due', 'kind': 'string'},
'registration_key': {'title': 'Registration Key', 'kind': 'string'},
'due_date': {'title': 'Due Date', 'kind': 'string'}
},
'required': ['invoice_number', 'date', 'account_number', 'owner', 'address', 'last_month_balance', 'current_amount_due', 'registration_key', 'due_date']
'title': 'Person',
'kind': 'object'
}
examples = str([
{
"type": "object",
"properties": {
"employer_name": {"type": "string", "title": "Employer Name"},
"employee_name": {"type": "string", "title": "Employee Name"},
"wages": {"type": "number", "title": "Wages"},
"federal_tax_withheld": {"type": "number", "title": "Federal Tax
Withheld"},
"state_wages": {"type": "number", "title": "State Wages"},
"state_tax": {"type": "number", "title": "State Tax"}
},
"required": ["employer_name", "employee_name", "wages",
"federal_tax_withheld", "state_wages", "state_tax"]
},
{
"kind": "object",
"properties": {
"booking_reference": {"kind": "string", "title": "Reserving Reference"},
"passenger_name": {"kind": "string", "title": "Passenger Title"},
"flight_number": {"kind": "string", "title": "Flight Quantity"},
"departure_airport": {"kind": "string", "title": "Departure Airport"},
"arrival_airport": {"kind": "string", "title": "Arrival Airport"},
"departure_time": {"kind": "string", "title": "Departure Time"},
"arrival_time": {"kind": "string", "title": "Arrival Time"} },
"required": ["booking_reference", "passenger_name", "flight_number","departure_airport", "arrival_airport", "departure_time", "arrival_time"]
}
])
extraction_graph_spec = """
title: 'invoice-learner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
title: 'pdf-extraction'
- extractor: 'schema_extractor'
title: 'text_to_json'
input_params:
service: 'openai'
example_text: {examples}
content_source: 'invoice-learner'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
consumer.create_extraction_graph(extraction_graph)
content_id = consumer.upload_file("invoice-learner", "/path/to/pdf.pdf")
print(content_id)
consumer.wait_for_extraction(content_id)
extracted_content = consumer.get_extracted_content(content_id=content_id, graph_name="invoice-learner", policy_name="text_to_json")
print(extracted_content)This superior instance demonstrates how one can chain a number of extractors. It first makes use of PaddleOCR to extract textual content from the PDF, then applies a schema extractor to parse the textual content into structured JSON knowledge primarily based on the outlined schema.
The schema extractor is fascinating because it lets you use each the schema in addition to infer the schema from the Language Mannequin of selection utilizing few-shot studying.
We do that by passing few examples of how the schema ought to look by the parameter example_text. The cleaner and extra verbose the examples are, the higher the inferred schema.
Allow us to examine the output from this design:
[Content(content_type="text/plain", data=b'{"Form":"1040","Forms W-2 & W-2G Summary":{"Year":2023,"Keep for your records":true,"Name(s) Shown on Return":"John H & Jane K Doe","Social Security Number":"321-12-3456","Employer":{"Name":"Acmeware Employer","Federal Tax":"SP","State Wages":143433,"State Tax":1000},"Totals":{"Wages":143433,"State Wages":143433,"State Tax":1000}},"Form W-2 Summary":{"Box No.":{"Description":{"Taxpayer":"John H Doe","Spouse":"Jane K Doe","Total":"John H & Jane K Doe"}},"Total wages, tips and compensation":{"W2 box 1 statutory wages reported on Sch C":143433,"W2 box 1 inmate or halfway house wages":0,"All other W2 box 1 wages":143433,"Foreign wages included in total wages":0},"Total federal tax withheld":0,"Total social security wages/tips":143566,"Total social security tax withheld":8901,"Total Medicare wages and tips":143566,"Total Medicare tax withheld":2082,"Total allocated tips":0,"Total dependent care benefits":{"Offsite dependent care benefits":0,"Onsite dependent care benefits":0},"Total distributions from nonqualified plans":0,"Total from Box 12":{"Elective deferrals to qualified plans":3732,"Roth contrib. to 401(k), 403(b), 457(b) plans":133,"Elective deferrals to government 457 plans":0,"Non-elective deferrals to gov't 457 plans":0,"Deferrals to non-government 457 plans":0,"Deferrals 409A nonqual deferred comp plan":0,"Income 409A nonqual deferred comp plan":0,"Uncollected Medicare tax":0,"Uncollected social security and RRTA tier 1":0,"Uncollected RRTA tier 2":0,"Income from nonstatutory stock options":0,"Non-taxable combat pay":0,"QSEHRA benefits":0,"Total other items from box 12":3599},"Total deductible mandatory state tax":0,"Total deductible charitable contributions":0,"Total state deductible employee expenses":0,"Total RR Compensation":0,"Total RR Tier 1 tax":0,"Total RR Tier 2 tax":0,"Total RR Medicare tax":0,"Total RR Additional Medicare tax":0,"Total RRTA tips":0,"Total other items from box 14":0,"Total sick leave subject to $511 limit":0,"Total sick leave subject to $200 limit":0,"Total emergency family leave wages":0,"Total state wages and tips":143433,"Total state tax withheld":1000,"Total local tax withheld":0}}, features=[Feature(feature_type="metadata", name="text", value={'model': 'gpt-3.5-turbo-0125', 'completion_tokens': 204, 'prompt_tokens': 692}, comment=None)], labels={})]Sure, that’s tough to learn so allow us to broaden that for you in Determine 6.

Because of this after this step, our textual knowledge is efficiently extracted right into a structured JSON format. The information is likely to be complexly laid out, spaced erratically, horizontally oriented, vertically oriented, diagonally oriented, giant fonts, small fonts, irrespective of the design, it simply works!
Nicely, that every one however solves the issue that we initially got down to do. We are able to lastly scream Mission Achieved, Tom Cruise fashion!
Whereas the PaddleOCR extractor is highly effective for textual content extraction from PDFs, the true power of Indexify lies in its capability to chain a number of extractors collectively, creating refined knowledge processing pipelines. Let’s delve deeper into why you may need to use further extractors and the way Indexify makes this course of seamless and environment friendly.
Indexify’s Extraction Graphs mean you can apply a sequence of extractors on ingested content material in a streaming method. Every step in an Extraction Graph is named an Extraction Coverage. This strategy gives a number of benefits:
- Modular Processing: Break down complicated extraction duties into smaller, manageable steps.
- Flexibility: Simply modify or substitute particular person extractors with out affecting the whole pipeline.
- Effectivity: Course of knowledge in a streaming trend, lowering latency and useful resource utilization.
Lineage Monitoring
Indexify tracks the lineage of remodeled content material and extracted options from the supply. This characteristic is essential for:
- Knowledge Governance: Perceive how your knowledge has been processed and remodeled.
- Debugging: Simply hint points again to their supply.
- Compliance: Meet regulatory necessities by sustaining a transparent audit path of information transformations.
Whereas PaddleOCR excels at textual content extraction, different extractors can add vital worth to your knowledge processing pipeline.
Why Select Indexify?
Indexify shines in eventualities the place:
- You’re coping with a big quantity of paperwork (>1000s).
- Your knowledge quantity grows over time.
- You want dependable and obtainable ingestion pipelines.
- You’re working with multi-modal knowledge or combining a number of fashions in a single pipeline.
- Your software’s consumer expertise is determined by up-to-date knowledge.
Conclusion
Extracting structured knowledge from PDFs doesn’t should be a headache. With Indexify and an array of highly effective extractors like PaddleOCR, you’ll be able to streamline your workflow, deal with giant volumes of paperwork, and extract significant, structured knowledge with ease. Whether or not you’re processing invoices, educational papers, or some other kind of PDF doc, Indexify offers the instruments it’s essential to flip unstructured knowledge into priceless insights.
Able to streamline your PDF extraction course of? Give Indexify a try to expertise the convenience of clever, scalable knowledge extraction!
[ad_2]