[ad_1]
Giant language fashions (LLMs) comparable to GPT-3 and Llama-2 have made important strides in understanding and producing human language. These fashions boast billions of parameters, permitting them to carry out advanced duties precisely. Nevertheless, the substantial computational sources required for coaching and deploying these fashions current important challenges, notably in resource-limited environments. Addressing these challenges is important to creating AI applied sciences extra accessible and broadly relevant.
The first problem with deploying massive language fashions is their immense measurement and the corresponding want for in depth computational energy and reminiscence. This limitation considerably restricts their usability in eventualities the place computational sources are constrained. Historically, a number of variations of the identical mannequin are skilled to steadiness effectivity and accuracy based mostly on the obtainable sources. For instance, the Llama-2 mannequin household consists of variants with 7 billion, 13 billion, and 70 billion parameters. Every variant is designed to function effectively inside totally different ranges of computational energy. Nevertheless, this strategy is resource-intensive, requiring important effort and computational useful resource duplication.
Current strategies to handle this problem embody coaching a number of variations of a mannequin, every tailor-made for various useful resource constraints. Whereas efficient in offering flexibility, this technique includes appreciable redundancy within the coaching course of, consuming time and computational sources. For example, coaching a number of multi-billion parameter fashions, like these within the Llama-2 household, calls for substantial information and computational energy, making the method impractical for a lot of purposes. To streamline this, researchers have been exploring extra environment friendly alternate options.
Researchers from NVIDIA and the College of Texas at Austin launched FLEXTRON, a novel versatile mannequin structure and post-training optimization framework. FLEXTRON is designed to assist adaptable mannequin deployment with out requiring extra fine-tuning, thus addressing the inefficiencies of conventional strategies. This structure employs a nested elastic construction, permitting it to regulate dynamically to particular latency and accuracy targets throughout inference. This adaptability makes utilizing a single pre-trained mannequin throughout numerous deployment eventualities attainable, considerably lowering the necessity for a number of mannequin variants.
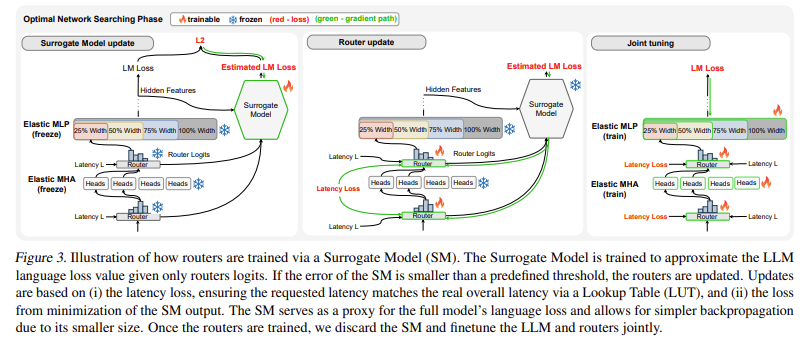
FLEXTRON transforms a pre-trained LLM into an elastic mannequin via a sample-efficient coaching technique and superior routing algorithms. The transformation course of consists of rating and grouping community parts and coaching routers that handle sub-network choice based mostly on user-defined constraints comparable to latency and accuracy. This modern strategy allows the mannequin to robotically choose the optimum sub-network throughout inference, guaranteeing environment friendly and correct efficiency throughout totally different computational environments.
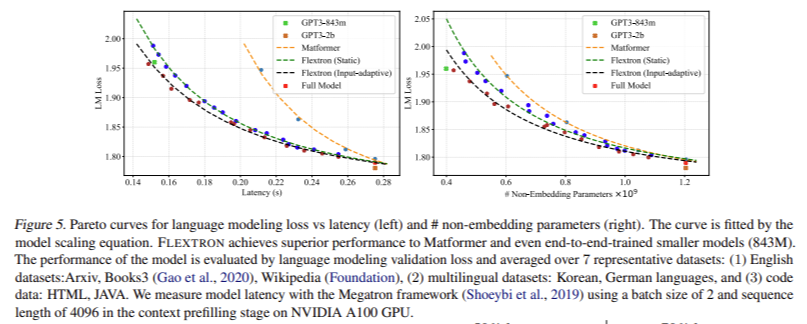
Efficiency evaluations of FLEXTRON demonstrated its superior effectivity and accuracy in comparison with a number of end-to-end skilled fashions and different state-of-the-art elastic networks. For instance, FLEXTRON carried out remarkably on the GPT-3 and Llama-2 mannequin households, requiring solely 7.63% of the coaching tokens used within the unique pre-training. This effectivity interprets into important financial savings in computational sources and time. The analysis included numerous benchmarks, comparable to ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU, and HellaSwag, the place FLEXTRON constantly outperformed different fashions.
The FLEXTRON framework additionally consists of an elastic Multi-Layer Perceptron (MLP) and elastic Multi-Head Consideration (MHA) layers, enhancing its adaptability. Elastic MHA layers, which represent a good portion of LLM runtime and reminiscence utilization, enhance total effectivity by deciding on a subset of consideration heads based mostly on the enter information. This function is especially helpful in eventualities with restricted computational sources, because it permits extra environment friendly use of accessible reminiscence and processing energy.

In conclusion, FLEXTRON, providing a versatile and adaptable structure that optimizes useful resource use and efficiency, addresses the crucial want for environment friendly mannequin deployment in various computational environments. The introduction of this framework by researchers from NVIDIA and the College of Texas at Austin highlights the potential for modern options in overcoming the challenges related to massive language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]