[ad_1]
Reinforcement studying (RL) focuses on how brokers can be taught to make selections by interacting with their setting. These brokers goal to maximise cumulative rewards over time by utilizing trial and error. This discipline is especially difficult because of the want for giant quantities of information and the issue in dealing with sparse or absent rewards in real-world purposes. RL purposes vary from recreation enjoying to robotic management, making it important for researchers to develop environment friendly and scalable studying strategies.
A significant concern in RL is the information shortage in embodied AI, the place brokers should work together with bodily environments. This downside is exacerbated by the necessity for substantial reward-labeled knowledge to coach brokers successfully. Consequently, growing strategies that may improve knowledge effectivity and allow data switch throughout completely different duties is essential. With out environment friendly knowledge utilization, the educational course of turns into gradual and resource-intensive, limiting the sensible deployment of RL in real-world situations.
Present strategies in RL typically need assistance with knowledge assortment and utilization inefficiencies. Strategies reminiscent of Hindsight Expertise Replay try to repurpose collected experiences to enhance studying effectivity. Nevertheless, these strategies nonetheless must be improved in requiring substantial human supervision and the shortcoming to adapt autonomously to new duties. These conventional approaches additionally typically fail to leverage the total potential of previous experiences, resulting in redundant efforts and slower progress in studying new duties.
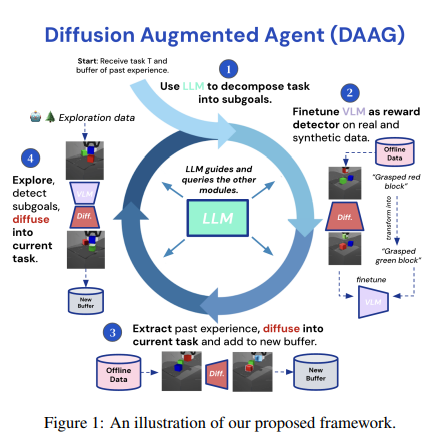
Researchers from Imperial Faculty London and Google DeepMind have launched the Diffusion Augmented Brokers (DAAG) framework to deal with these challenges. This framework integrates giant language fashions, imaginative and prescient language fashions, and diffusion fashions to reinforce pattern effectivity and switch studying. The analysis group developed this framework to function autonomously, minimizing the necessity for human supervision. By combining these superior fashions, DAAG goals to make RL extra sensible and efficient for real-world purposes, significantly in robotics and sophisticated job environments.
The DAAG framework makes use of a big language mannequin to orchestrate the agent’s conduct and interactions with imaginative and prescient and diffusion fashions. The diffusion fashions remodel the agent’s previous experiences by modifying video knowledge to align with new duties. This course of, known as Hindsight Expertise Augmentation, permits the agent to repurpose its experiences successfully, enhancing studying effectivity and enabling the agent to deal with new duties extra quickly. The imaginative and prescient language mannequin, CLIP, is fine-tuned utilizing this augmented knowledge, permitting it to behave as a extra correct reward detector. The massive language mannequin breaks down duties into manageable subgoals, guiding the diffusion mannequin in creating related knowledge modifications.
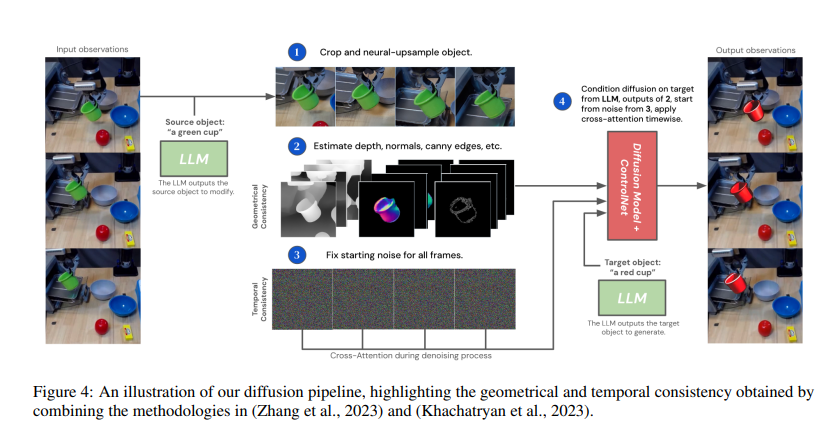
Relating to methodology, the DAAG framework operates by means of a finely tuned interaction between its parts. The massive language mannequin is the central controller, guiding the imaginative and prescient language and diffusion fashions. When the agent receives a brand new job, the massive language mannequin decomposes it into subgoals. The imaginative and prescient language mannequin, fine-tuned with augmented knowledge, detects when these subgoals are achieved within the agent’s experiences. The diffusion mannequin modifies previous experiences to create new, related coaching knowledge, guaranteeing temporal and geometric consistency within the modified video frames. This autonomous course of considerably reduces human intervention, making studying extra environment friendly and scalable.
The DAAG framework confirmed marked enhancements in numerous metrics. In a robotic manipulation setting, job success charges elevated by 40%, lowering the variety of reward-labeled knowledge samples wanted by 50%. DAAG lower the required coaching episodes by 30% for navigation duties whereas sustaining excessive accuracy. Moreover, in duties involving stacking coloured cubes, the framework achieved a 35% increased completion charge than conventional RL strategies. These quantitative outcomes display DAAG’s effectivity in enhancing studying efficiency and transferring data throughout duties, proving its effectiveness in various simulated environments.
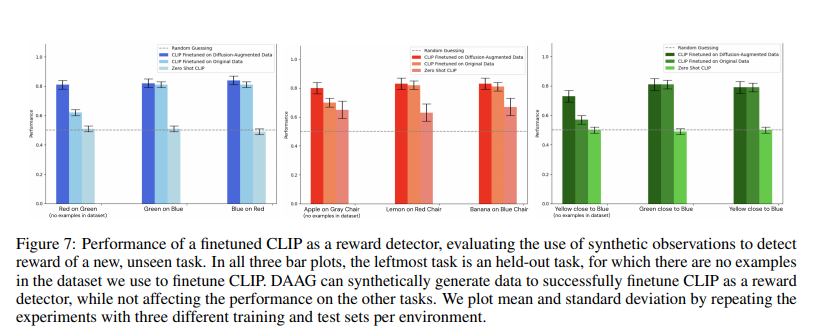
In abstract, the DAAG framework affords a promising answer to knowledge shortage and switch studying challenges in RL. Leveraging superior fashions and autonomous processes considerably enhances studying effectivity in embodied brokers. The analysis performed by Imperial Faculty London and Google DeepMind marks a step ahead in creating extra succesful and adaptable AI methods. Via using Hindsight Expertise Augmentation and complex mannequin orchestration, DAAG represents a brand new course in growing RL applied sciences. This development means that future RL purposes might turn into extra sensible and widespread, in the end resulting in extra clever and versatile AI brokers.
Take a look at the Paper and Mission. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

[ad_2]