[ad_1]
Introduction
In Synthetic Intelligence, Understanding the underlying workings of language fashions has confirmed to be important and tough. Google has made a big step ahead in tackling this challenge by releasing Gemma Scope, a complete package deal of instruments to help researchers in peering contained in the “black field” of AI language fashions. This text will have a look at Gemma Scope, its significance, and the way it intends to remodel the sphere of mechanistic interpretability.

Overview
- Mechanistic interpretability helps researchers perceive how AI fashions be taught from information and make choices with out human intervention.
- Gemma Scope affords a set of instruments, together with sparse autoencoders, to assist researchers analyze and perceive the interior workings of AI language fashions like Gemma 2 9B and Gemma 2 2B.
- Gemma Scope dissects mannequin activations utilizing sparse autoencoders into distinct options, offering insights into how language fashions course of and generate textual content.
- Implementing Gemma Scope entails loading the Gemma 2 mannequin, operating textual content inputs by it, and utilizing sparse autoencoders to investigate activations, as demonstrated within the offered code examples.
- Gemma Scope advances AI analysis by providing instruments for deeper understanding, enhancing mannequin design, addressing security considerations, and scaling interpretability methods to bigger fashions.
- Future analysis in mechanistic interpretability ought to concentrate on automating characteristic interpretation, making certain scalability, generalizing insights throughout fashions, and addressing moral issues in AI growth.
What’s Gemma Scope?
Gemma Scope is a set of a whole lot of publicly out there open sparse autoencoders (SAEs) for Google’s light-weight open mannequin household, Gemma 2 9B and Gemma 2 2B. These applied sciences function a “microscope” for teachers, permitting them to investigate the interior processes of language fashions and acquire insights into how they work and resolve.
The Significance of Mechanistic Interpretability
To appreciate Gemma Scope’s significance, you need to first perceive the idea of mechanical interpretability. When researchers design AI language fashions, they create techniques that may be taught from massive volumes of information with out human intervention. In consequence, the inside workings of those fashions are ceaselessly unknown, even to their authors.
Mechanistic interpretability is a analysis topic dedicated to understanding these elementary workings. By finding out it, researchers can purchase a deeper information of how language fashions operate.
- Create extra resilient techniques.
- Enhance precautions in opposition to mannequin hallucinations.
- Shield in opposition to the hazards of autonomous AI brokers, corresponding to dishonesty or manipulation.
How Does Gemma Scope Work?
Gemma Scope makes use of sparse autoencoders to interpret a mannequin’s activations whereas processing textual content enter. Right here’s a easy rationalization of the method:
- Textual content Enter: If you ask a language mannequin a question, it converts your textual content right into a set of ‘activations’.
- Activation Mapping: These activations signify phrase associations, permitting the mannequin to create connections and supply solutions.
- Characteristic Recognition: Because the mannequin processes textual content, activations at varied layers within the neural community signify more and more advanced notions often known as ‘options’.
- Sparse Autoencoder Evaluation: Gemma Scope’s sparse autoencoders divide every activation into restricted options, which can disclose the language mannequin’s true underlying traits.
Additionally learn: The way to Use Gemma LLM?
Gemma Scope-Technical Particulars and Implementation
Let’s dive into the technical particulars of implementing Gemma Scope, utilizing code examples as an instance key ideas:
Loading the Mannequin
First, we have to load the Gemma 2 mannequin:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
from huggingface_hub import hf_hub_download, notebook_login
import numpy as np
import torchWe load Gemma 2 2B, the smallest mannequin for which Gemma Scope works. We load the bottom mannequin somewhat than the dialog mannequin as a result of that’s the place our SAEs are taught. The SAEs seem to switch to those fashions.
To acquire the mannequin weights, you first must authenticate them with huggingface.
notebook_login()
torch.set_grad_enabled(False) # keep away from blowing up mem
mannequin = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-2b",
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Working the Mannequin

Now we’ve loaded the mannequin, let’s strive operating it! We give it the immediate
“Only a drop within the ocean A change within the climate,I used to be praying that you simply and me may find yourself collectively. Its like wiching for the rain as I stand within the desert.” and print the generated output
from IPython.show import show, Markdown
immediate = "Only a drop within the ocean A change within the climate,I used to be praying that you simply and me may find yourself collectively. Its like wiching for the rain as I stand within the desert."
# Use the tokenizer to transform it to tokens. Observe that this implicitly provides a particular "Starting of Sequence" or <bos> token to the beginning
inputs = tokenizer.encode(immediate, return_tensors="pt", add_special_tokens=True).to("cuda")
show(Markdown(f"**Encoded inputs:**n```n{inputs}n```"))
# Cross it in to the mannequin and generate textual content
outputs = mannequin.generate(input_ids=inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0])
show(Markdown(f"**Generated textual content:**nn{generated_text}"))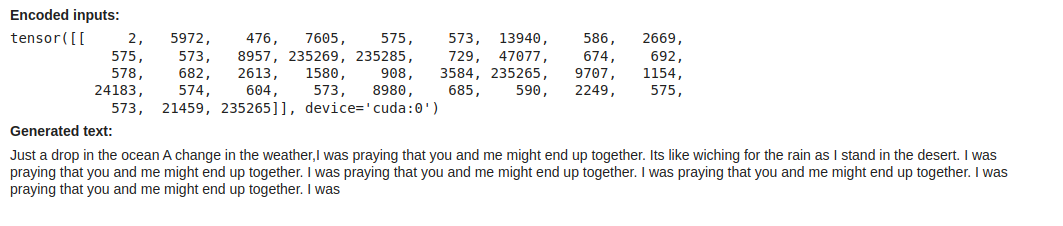
So we now have Gemma 2 loaded and might pattern from it to get smart outcomes.
Now, let’s load one in all our SAE recordsdata.
GemmaScope has almost 4 hundred SAEs, however for now, we’ll merely load one on the residual stream on the finish of layer 20.
Loading the parameters of the mannequin and transferring them to GPU:
params = np.load(path_to_params)
pt_params = {okay: torch.from_numpy(v).cuda() for okay, v in params.objects()}Implementing the Sparse-Auto-Encoder(SAE):
We now outline the SAE’s ahead go for academic causes.
Gemma Scope is a set of JumpReLU SAEs, much like a typical two-layer (one hidden layer) neural community however with a JumpReLU activation operate: a ReLU with a discontinuous bounce.
import torch.nn as nn
class JumpReLUSAE(nn.Module):
def __init__(self, d_model, d_sae):
# Observe that we initialise these to zeros as a result of we're loading in pre-trained weights.
# If you wish to practice your personal SAEs then we suggest utilizing blah
tremendous().__init__()
self.W_enc = nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = nn.Parameter(torch.zeros(d_sae))
self.b_enc = nn.Parameter(torch.zeros(d_sae))
self.b_dec = nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
masks = (pre_acts > self.threshold)
acts = masks * torch.nn.purposeful.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
def ahead(self, acts):
acts = self.encode(acts)
recon = self.decode(acts)
return recon
sae = JumpReLUSAE(params['W_enc'].form[0], params['W_enc'].form[1])
sae.load_state_dict(pt_params)First, let’s run some mannequin activations on the SAE goal web site. We’ll begin by demonstrating how to do that ‘ manually’ utilizing Pytorch hooks. It ought to be famous that this isn’t particularly good apply, and it’s most likely extra sensible to make the most of a library like TransformerLens to deal with plugging the SAE right into a mannequin’s ahead go. Nonetheless, seeing the way it’s accomplished may be helpful for illustration.
We are able to acquire activations at a spot by registering a hook. To maintain this native, we might wrap it in a operate that registers a hook, runs the mannequin whereas recording the intermediate activation, after which removes the hook.
def gather_residual_activations(mannequin, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act # make certain we will modify the target_act from the outer scope
target_act = outputs[0]
return outputs
deal with = mannequin.mannequin.layers[target_layer].register_forward_hook(gather_target_act_hook)
_ = mannequin.ahead(inputs)
deal with.take away()
return target_act
target_act = gather_residual_activations(mannequin, 20, inputs)
sae.cuda()
sae_acts = sae.encode(target_act.to(torch.float32))
recon = sae.decode(sae_acts)Let’s simply double-check that the mannequin seems to be smart by checking that we clarify an honest chunk of the variance:
1 - torch.imply((recon[:, 1:] - target_act[:, 1:].to(torch.float32)) **2) / (target_act[:, 1:].to(torch.float32).var())
This most likely seems high-quality. This SAE reportedly has an L0 of roughly 70, so let’s additionally examine that.
(sae_acts > 1).sum(-1)
There may be one catch: our SAEs should not educated on the BOS token as a result of we found that it tended to be an enormous outlier and trigger coaching to fail. In consequence, once we ask them to do one thing, they have an inclination to say gibberish, and we should be cautious not to do that accidentally! As proven above, the BOS token is a big outlier when it comes to L0!
Let’s check out probably the most activating facets on this enter textual content at every token place.
values, inds = sae_acts.max(-1)
inds
So we discover that one of many max activation examples on this matter is which fires on notions linked to time journey!
Let’s visualize the options in a extra interactive method by using the Neuropedia dashboard.
from IPython.show import IFrame
html_template = "https://neuronpedia.org/{}/{}/{}?embed=true&embedexplanation=true&embedplots=true&embedtest=true&top=300"
def get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=0):
return html_template.format(sae_release, sae_id, feature_idx)
html = get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=10004)
IFrame(html, width=1200, top=600)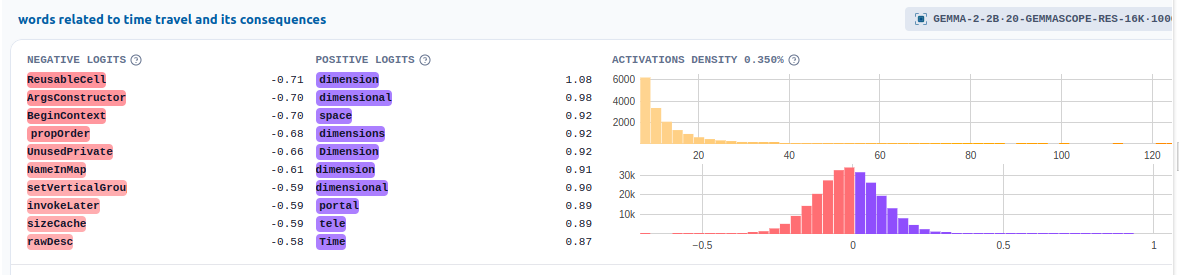
Additionally Learn: Google Gemma, the Open-Supply LLM Powerhouse
A Actual-world Case Situation
Think about analyzing and evaluating current objects to indicate Gemma Scope’s sensible use. This instance reveals Gemma 2’s elementary strategies for dealing with varied information content material.
Setup and Implementation
First, we’ll put together the environment by importing the mandatory libraries and loading the Gemma 2 2B mannequin and its tokenizer.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import hf_hub_download
import numpy as np
# Load Gemma 2 2B mannequin and tokenizer
mannequin = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b", device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Subsequent, we’ll implement the JumpReLU Sparse Autoencoder (SAE) and cargo pre-trained parameters:
# Outline JumpReLU SAE
class JumpReLUSAE(torch.nn.Module):
def __init__(self, d_model, d_sae):
tremendous().__init__()
self.W_enc = torch.nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = torch.nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = torch.nn.Parameter(torch.zeros(d_sae))
self.b_enc = torch.nn.Parameter(torch.zeros(d_sae))
self.b_dec = torch.nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
masks = (pre_acts > self.threshold)
acts = masks * torch.nn.purposeful.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
# Load pre-trained SAE parameters
path_to_params = hf_hub_download(
repo_id="google/gemma-scope-2b-pt-res",
filename="layer_20/width_16k/average_l0_71/params.npz",
)
params = np.load(path_to_params)
pt_params = {okay: torch.from_numpy(v).cuda() for okay, v in params.objects()}
# Initialize and cargo SAE
sae = JumpReLUSAE(params['W_enc'].form[0], params['W_enc'].form[1])
sae.load_state_dict(pt_params)
sae.cuda()
# Operate to assemble activations
def gather_residual_activations(mannequin, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act
target_act = outputs[0]
deal with = mannequin.mannequin.layers[target_layer].register_forward_hook(gather_target_act_hook)
_ = mannequin(inputs)
deal with.take away()
return target_actEvaluation Operate
We’ll create a operate to investigate headlines utilizing Gemma Scope:
# Analyze headline with Gemma Scope
def analyze_headline(headline, top_k=5):
inputs = tokenizer.encode(headline, return_tensors="pt", add_special_tokens=True).to("cuda")
# Collect activations
target_act = gather_residual_activations(mannequin, 20, inputs)
# Apply SAE
sae_acts = sae.encode(target_act.to(torch.float32))
# Get prime activated options
values, indices = torch.topk(sae_acts.sum(dim=1), okay=top_k)
return indices[0].tolist()Pattern Headlines
For our evaluation, we’ll use a various set of stories headlines:
# Pattern information headlines
headlines = [
"Global temperatures reach record high in 2024",
"Tech giant unveils revolutionary quantum computer",
"Historic peace treaty signed in Middle East",
"Breakthrough in renewable energy storage announced",
"Major cybersecurity attack affects millions worldwide"
]Characteristic Categorization
To make our evaluation extra interpretable, we’ll categorize the activated options into broad subjects:
# Predefined characteristic classes (for demonstration functions)
feature_categories = {
1000: "Local weather and Setting",
2000: "Expertise and Innovation",
3000: "International Politics",
4000: "Power and Sustainability",
5000: "Cybersecurity and Digital Threats"
}
def categorize_feature(feature_id):
category_id = (feature_id // 1000) * 1000
return feature_categories.get(category_id, "Uncategorized")Outcomes and Interpretation
Now, let’s analyze every headline and interpret the outcomes:
# Analyze headlines
for headline in headlines:
print(f"nHeadline: {headline}")
top_features = analyze_headline(headline)
print("Prime activated characteristic classes:")
for characteristic in top_features:
class = categorize_feature(characteristic)
print(f"- Characteristic {characteristic}: {class}")
print(f"For detailed characteristic interpretation, go to: https://neuronpedia.org/gemma-2-2b/20-gemmascope-res-16k/{top_features[0]}")
# Generate a abstract report
print("n--- Abstract Report ---")
print("This evaluation demonstrates how Gemma Scope can be utilized to know the underlying ideas")
print("that the mannequin prompts when processing various kinds of information headlines.")
print("By analyzing the activated options, we will acquire insights into the mannequin's interpretation")
print("of assorted information subjects and doubtlessly determine biases or focus areas in its coaching information.")
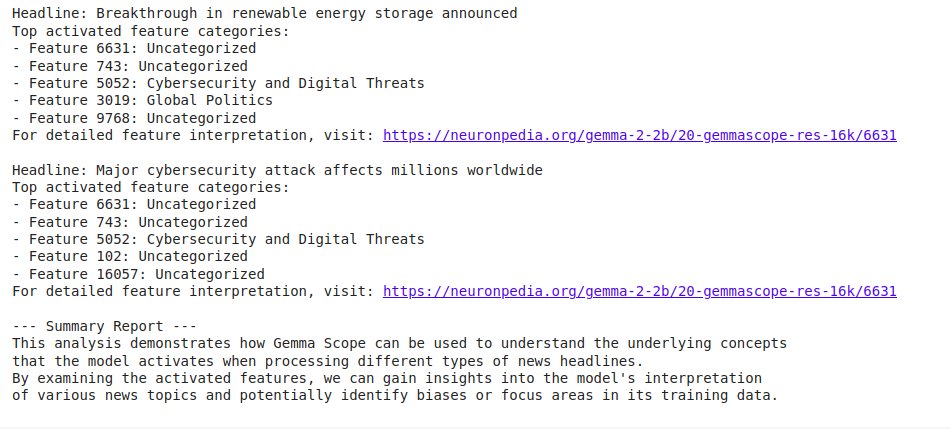
This investigation sheds mild on how the Gemma 2 mannequin reads completely different information topics. For instance, we might even see that headlines concerning local weather change ceaselessly activate options within the “Local weather and Setting” class, whereas tech information prompts options in “Expertise and Innovation”.
Additionally learn: Gemma 2: Successor to Google Gemma Household of Massive Language Fashions.
Gemma Scope: Affect on AI Analysis and Growth
Gemma Scope is a crucial achievement within the realm of mechanistic interpretability. Its potential influence on AI analysis and growth is intensive:
- Elevated understanding of mannequin habits: Gemma Scope provides researchers an intensive perspective of a mannequin’s inner processes, permitting them to know higher how language fashions make choices and reply.
- Improved mannequin design: Researchers who higher perceive mannequin internals can create extra environment friendly and efficient language fashions, maybe resulting in breakthroughs in AI capabilities.
- Responding to AI Security Issues: Gemma Scope’s capability to indicate the inside workings of language fashions might help determine and mitigate potential AI system hazards corresponding to biases, hallucinations, or surprising actions.
- Advancing Interpretability Analysis: Google hopes to expedite progress on this essential subject by establishing Gemma 2 because the most interesting mannequin household for open mechanistic interpretability analysis.
- Scaling Strategies to Trendy Fashions: With Gemma Scope, researchers can apply interpretability methods developed for less complicated fashions to bigger, extra difficult techniques corresponding to Gemma 2 9B.
- Understanding Advanced Capabilities: Researchers can now use Gemma Scope’s intensive toolbox to research extra superior language mannequin capabilities, corresponding to chain-of-thought reasoning.
- Actual-World Functions: Gemma Scope’s discoveries have the flexibility to handle actual AI deployment difficulties, corresponding to minimizing hallucinations and stopping jailbreaks in bigger fashions.
Challenges and Future Instructions
Whereas Gemma Scope affords an enormous step ahead in language mannequin interpretability, there are nonetheless varied obstacles and subjects for future analysis.
- Characteristic interpretation: Though Gemma Scope might acknowledge options, evaluating their which means and relevance requires human intervention. Growing automated strategies for characteristic interpretation is a essential topic for future analysis.
- Scalability: As language fashions develop in measurement and complexity, making certain that interpretability instruments like Gemma Scope can sustain will likely be essential.
- Generalizing Insights: The insights gained through Gemma Scope will likely be translated to different language fashions and AI techniques in order that they’re extra broadly relevant.
- Moral issues: As we get better insights into AI techniques, addressing moral considerations about privateness, bias, and accountable AI growth turns into more and more necessary.
Conclusion
Gemma Scope is an enormous step ahead within the subject of mechanical interpretability for language fashions. Google has opened up new paths for finding out, enhancing, and defending these more and more important applied sciences by providing teachers highly effective instruments to look at the inside workings of AI techniques.
Steadily Requested Questions
Ans. Gemma Scope is a set of open sparse autoencoders (SAEs) for Google’s light-weight open mannequin household, Gemma 2 9B and Gemma 2 2B, which permits researchers to investigate the interior processes of language fashions and acquire insights into their workings.
Ans. Mechanistic interpretability helps researchers perceive the elemental workings of AI fashions, enabling the creation of extra resilient techniques, enhancing mannequin safeguards in opposition to hallucinations, and defending in opposition to dangers like dishonesty or manipulation by autonomous AI brokers.
Ans. SAEs are a kind of neural community utilized in Gemma Scope to decompose activations into restricted options, revealing the underlying traits of the language mannequin.
Ans. Sure, the implementation entails loading the Gemma 2 mannequin, operating it with particular textual content enter, and analyzing activations utilizing sparse autoencoders. The article supplies pattern code for detailed steps.
[ad_2]