[ad_1]
Giant-scale multimodal basis fashions have achieved notable success in understanding advanced visible patterns and pure language, producing curiosity of their software to medical vision-language duties. Progress has been made by creating medical datasets with image-text pairs and fine-tuning basic area fashions on these datasets. Nonetheless, these datasets have limitations. They lack multi-granular annotations that hyperlink native and world data inside medical photos, which is essential for figuring out particular lesions from regional particulars. Moreover, present strategies for developing these datasets rely closely on pairing medical photos with reviews or captions, limiting their scalability.
Researchers from UC Santa Cruz, Harvard College, and Stanford College have launched MedTrinity-25M, a large-scale multimodal medical dataset containing over 25 million photos throughout ten modalities. This dataset contains detailed multi-granular annotations for greater than 65 illnesses, encompassing world data like illness sort and modality and native annotations reminiscent of bounding containers and segmentation masks for areas of curiosity (ROIs). Utilizing an automatic pipeline, the researchers generated these complete annotations with out counting on paired textual content descriptions, enabling superior multimodal duties and supporting large-scale pretraining of medical AI fashions.
Medical multimodal basis fashions have seen rising curiosity as a result of their potential to grasp advanced visible and textual options, resulting in developments in medical vision-language duties. Fashions like Med-Flamingo and Med-PaLM have been fine-tuned on medical datasets to reinforce their efficiency. Nonetheless, the size of obtainable coaching knowledge usually limits these fashions. To deal with this, researchers have targeted on developing massive medical datasets. Nonetheless, datasets like MIMIC-CXR and RadGenome-Chest CT are constrained by the labor-intensive strategy of pairing photos with detailed textual descriptions. In distinction, the MedTrinity-25M dataset makes use of an automatic pipeline to generate complete multi-granular annotations for unpaired pictures, providing a considerably bigger and extra detailed dataset.
The MedTrinity-25M dataset options over 25 million photos organized into triplets of {picture, ROI, description}. Photos span ten modalities and canopy 65 illnesses, sourced from repositories like TCIA and Kaggle. ROIs are highlighted with masks or bounding containers, pinpointing abnormalities or key anatomical options. Multigranular textual descriptions element the picture modality, illness, and ROI specifics. The dataset building includes producing coarse captions, figuring out ROIs with fashions like SAT and BA-Transformer, and leveraging medical information for correct descriptions. MedTrinity-25M stands out for its scale, variety, and detailed annotations in comparison with different datasets.
The research evaluated LLaVA-Med++ on biomedical Visible Query Answering (VQA) duties utilizing VQA-RAD, SLAKE, and PathVQA datasets to evaluate the influence of pretraining on the MedTrinity-25M dataset. Preliminary pretraining adopted LLaVA-Med’s methodology, with extra fine-tuning on VQA datasets for 3 epochs. Outcomes present that LLaVA-Med++ with MedTrinity-25M pretraining outperforms the baseline mannequin by roughly 10.75% on VQA-RAD, 6.1% on SLAKE, and 13.25% on PathVQA. It achieves state-of-the-art ends in two benchmarks and ranks third within the third, demonstrating vital efficiency enhancements with MedTrinity-25M pretraining.
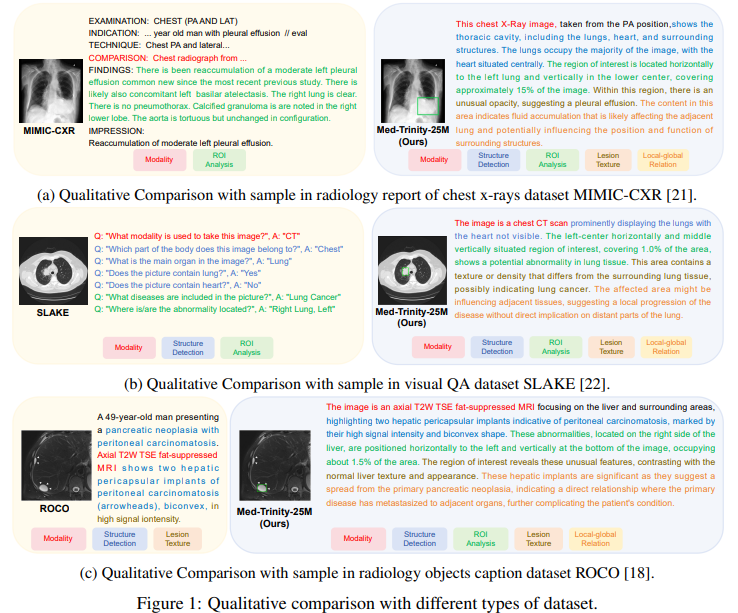
The research presents MedTrinity-25M, an unlimited multi-modal medical dataset with over 25 million image-ROI-description triplets from 90 sources, spanning ten modalities and protecting over 65 illnesses. Not like earlier strategies reliant on paired image-text knowledge, MedTrinity-25M is created utilizing an automatic pipeline that generates detailed annotations from unpaired photos, leveraging knowledgeable fashions and superior MLLMs. The dataset’s wealthy multi-granular annotations help quite a lot of duties, together with captioning, report era, and classification. The mannequin, pretrained on MedTrinity-25M, achieved state-of-the-art ends in VQA duties, highlighting its effectiveness for coaching multimodal medical AI fashions.
Take a look at the Paper and Undertaking. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

[ad_2]