[ad_1]
Latest AI developments have notably impacted numerous sectors, notably in picture recognition and photorealistic picture era, with important medical imaging and autonomous driving purposes. Nevertheless, the video understanding and era area, particularly Video-LLMs, nonetheless wants assist. These fashions wrestle with processing temporal dynamics and integrating audio-visual information, limiting their effectiveness in predicting future occasions and performing complete multimodal analyses. Addressing these complexities is essential for enhancing Video-LLM efficiency.
Researchers at DAMO Academy, Alibaba Group, have launched VideoLLaMA 2, a set of superior Video-LLMs designed to enhance spatial-temporal modeling and audio understanding in video-related duties. Based mostly on earlier fashions, VideoLLaMA 2 encompasses a customized Spatial-Temporal Convolution (STC) connector to raised deal with video dynamics and an built-in Audio Department for enhanced multimodal understanding. Evaluations point out that VideoLLaMA 2 excels in duties like video query answering and captioning, outperforming many open-source fashions and rivaling some proprietary ones. These developments place VideoLLaMA 2 as a brand new customary in clever video evaluation.
Present Video-LLMs usually use a pre-trained visible encoder, a vision-language adapter, and an instruction-tuned language decoder to course of video content material. Nevertheless, present fashions typically overlook temporal dynamics, counting on language decoders for this process, which could possibly be extra environment friendly. To deal with this, VideoLLaMA 2 introduces an STC Connector that higher captures spatial-temporal options whereas sustaining visible token effectivity. Moreover, latest developments have targeted on integrating audio streams into Video-LLMs, enhancing multimodal understanding and enabling extra complete video scene evaluation by fashions like PandaGPT, XBLIP, and CREMA.
VideoLLaMA 2 retains the dual-branch structure of its predecessor, with separate Imaginative and prescient-Language and Audio-Language branches that join pre-trained visible and audio encoders to a big language mannequin. The Imaginative and prescient-Language department makes use of an image-level encoder (CLIP) and introduces an STC Connector for improved spatial-temporal illustration. The Audio-Language department preprocesses audio into spectrograms and makes use of the BEATs audio encoder for temporal dynamics. This modular design ensures efficient visible and auditory information integration, enhancing VideoLLaMA 2’s multimodal capabilities and permitting simple adaptation for future expansions.
VideoLLaMA 2 excels in video and audio understanding duties, persistently outperforming open-source fashions and competing carefully with high proprietary programs. It demonstrates sturdy efficiency in video query answering, video captioning, and audio-based duties, notably excelling in multi-choice video query answering (MC-VQA) and open-ended audio-video query answering (OE-AVQA). The mannequin’s skill to combine complicated multimodal information, reminiscent of video and audio, reveals important developments over different fashions. General, VideoLLaMA 2 stands out as a number one video and audio understanding mannequin, with strong and aggressive outcomes throughout benchmarks.
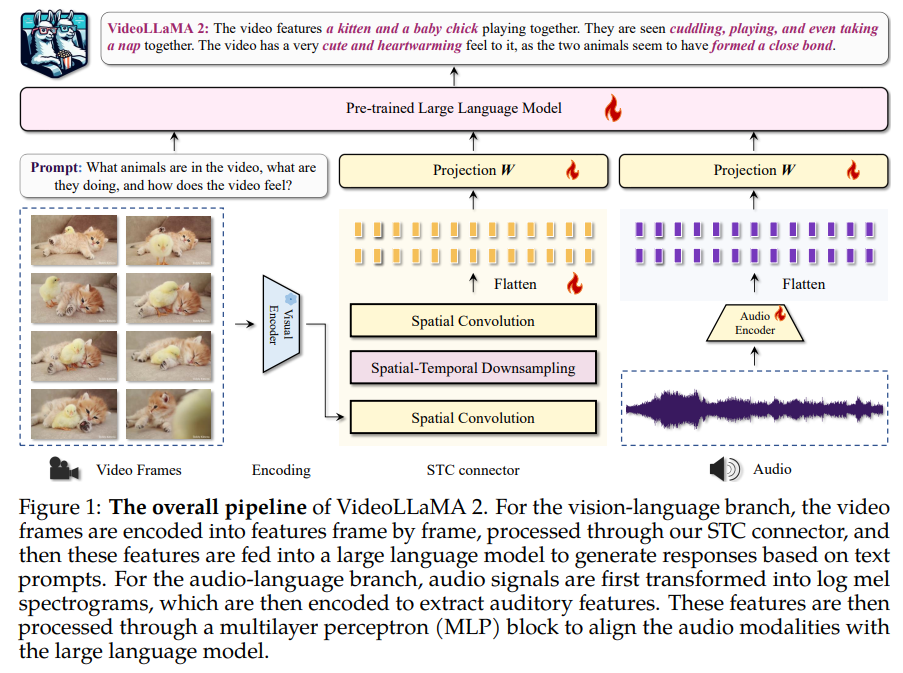
The VideoLLaMA 2 sequence introduces superior Video-LLMs to boost multimodal comprehension in video and audio duties. By integrating an STC connector and a collectively educated Audio Department, the mannequin captures spatial-temporal dynamics and incorporates audio cues. VideoLLaMA 2 persistently outperforms related open-source fashions and competes carefully with proprietary fashions throughout a number of benchmarks. Its sturdy efficiency in video query answering, video captioning, and audio-based duties highlights its potential for tackling complicated video evaluation and multimodal analysis challenges. The fashions are publicly obtainable for additional improvement.
Try the Paper, Mannequin Card on HF and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.

[ad_2]