[ad_1]
Introduction
Retrieval-augmented era (RAG) programs are remodeling AI by enabling giant language fashions (LLMs) to entry and combine data from exterior vector databases with no need fine-tuning. This strategy permits LLMs to ship correct, up-to-date responses by dynamically retrieving the most recent knowledge, decreasing computational prices, and bettering real-time decision-making.
For instance, corporations like JPMorgan Chase use RAG programs to automate the evaluation of economic paperwork, extracting key insights essential for funding selections. These programs have allowed monetary giants to course of 1000’s of economic statements, contracts, and experiences, extracting key monetary metrics and insights which might be important for funding selections. Nevertheless, a problem arises when coping with non-machine-readable codecs like scanned PDFs, which require Optical Character Recognition (OCR) for correct knowledge extraction. With out OCR expertise, important monetary knowledge from paperwork like S-1 filings and Okay-1 varieties can’t be precisely extracted and built-in, limiting the effectiveness of the RAG system in retrieving related data.
On this article, we’ll stroll you thru a step-by-step information to constructing a monetary RAG system. We’ll additionally discover efficient options by Nanonets for dealing with monetary paperwork which might be machine-unreadable, making certain that your system can course of all related knowledge effectively.
Understanding RAG Techniques
Constructing a Retrieval-Augmented Era (RAG) system entails a number of key parts that work collectively to reinforce the system’s potential to generate related and contextually correct responses by retrieving and using exterior data. To higher perceive how RAG programs function, let’s shortly overview the 4 fundamental steps, ranging from when the person enters their question to when the mannequin returns its reply.
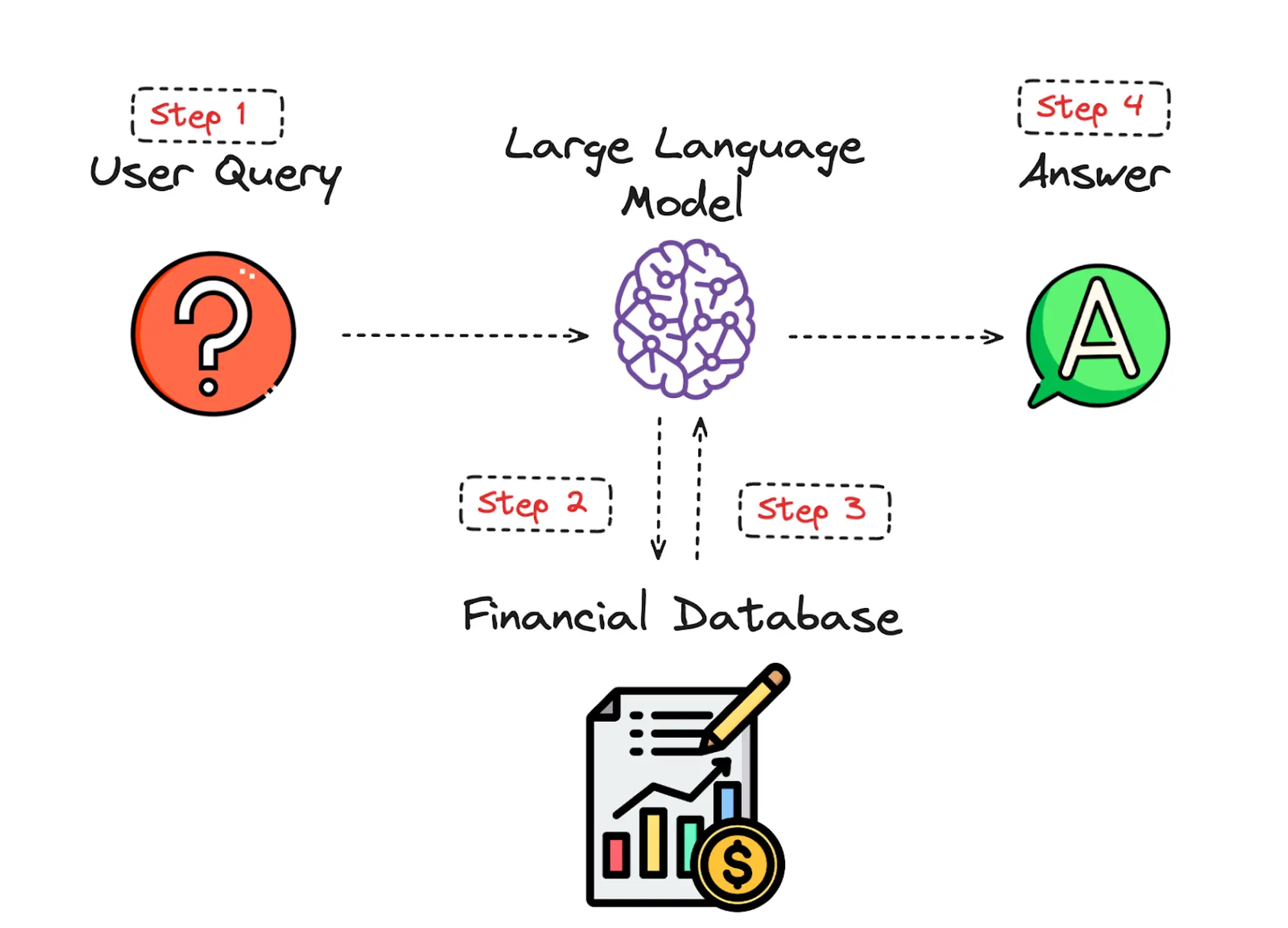
1. Consumer Enters Question
The person inputs a question by means of a person interface, akin to an internet kind, chat window, or voice command. The system processes this enter, making certain it’s in an acceptable format for additional evaluation. This may contain fundamental textual content preprocessing like normalization or tokenization.
The question is handed to the Massive Language Mannequin (LLM), akin to Llama 3, which interprets the question and identifies key ideas and phrases. The LLM assesses the context and necessities of the question to formulate what data must be retrieved from the database.
2. LLM Retrieves Information from the Vector Database
The LLM constructs a search question based mostly on its understanding and sends it to a vector database akin to FAISS, which is a library developed by Fb AI that gives environment friendly similarity search and clustering of dense vectors, and is extensively used for duties like nearest neighbor search in giant datasets.
The embeddings which is the numerical representations of the textual knowledge that’s used to be able to seize the semantic that means of every phrase within the monetary dataset, are saved in a vector database, a system that indexes these embeddings right into a high-dimensional area. Shifting on, a similarity search is carried out which is the method of discovering probably the most related objects based mostly on their vector representations, permitting us to extract knowledge from probably the most related paperwork.
The database returns a listing of the highest paperwork or knowledge snippets which might be semantically much like the question.
3. Up-to-date RAG Information is Returned to the LLM
The LLM receives the retrieved paperwork or knowledge snippets from the database. This data serves because the context or background information that the LLM makes use of to generate a complete response.
The LLM integrates this retrieved knowledge into its response-generation course of, making certain that probably the most present and related data is taken into account.
4. LLM Replies Utilizing the New Recognized Information and Sends it to the Consumer
Utilizing each the unique question and the retrieved knowledge, the LLM generates an in depth and coherent response. This response is crafted to handle the person’s question precisely, leveraging the up-to-date data supplied by the retrieval course of.
The system delivers the response again to the person by means of the identical interface they used to enter their question.
Step-by-Step Tutorial: Constructing the RAG App
The best way to Construct Your Personal Rag Workflows?
As we acknowledged earlier, RAG programs are extremely helpful within the monetary sector for superior knowledge retrieval and evaluation. On this instance, we’re going to analyze an organization often called Allbirds. We’re going to rework the Allbirds S-1 doc into phrase embeddings—numerical values that machine studying fashions can course of—we allow the RAG system to interpret and extract related data from the doc successfully.
This setup permits us to ask Llama LLM fashions questions that they have not been particularly skilled on, with the solutions being sourced from the vector database. This methodology leverages the semantic understanding of the embedded S-1 content material, offering correct and contextually related responses, thus enhancing monetary knowledge evaluation and decision-making capabilities.
For our instance, we’re going to make the most of S-1 monetary paperwork which include important knowledge about an organization’s monetary well being and operations. These paperwork are wealthy in each structured knowledge, akin to monetary tables, and unstructured knowledge, akin to narrative descriptions of enterprise operations, danger elements, and administration’s dialogue and evaluation. This combine of information varieties makes S-1 filings ideally suited candidates for integrating them into RAG programs. Having stated that, let’s begin with our code.
Step 1: Putting in the Mandatory Packages
To begin with, we’re going to be certain that all needed libraries and packages are put in. These libraries embody instruments for knowledge manipulation (numpy, pandas), machine studying (sci-kit-learn), textual content processing (langchain, tiktoken), vector databases (faiss-cpu), transformers (transformers, torch), and embeddings (sentence-transformers).
!pip set up numpy pandas scikit-learn
!pip set up langchain tiktoken faiss-cpu transformers pandas torch openai
!pip set up sentence-transformers
!pip set up -U langchain-community
!pip set up beautifulsoup4
!pip set up -U langchain-huggingface
Step 2: Importing Libraries and Initialize Fashions
On this part, we will probably be importing the required libraries for knowledge dealing with, machine studying, and pure language processing.
As an example, the Hugging Face Transformers library supplies us with highly effective instruments for working with LLMs like Llama 3. It permits us to simply load pre-trained fashions and tokenizers, and to create pipelines for numerous duties like textual content era. Hugging Face’s flexibility and vast assist for various fashions make it a go-to alternative for NLP duties. The utilization of such library is dependent upon the mannequin at hand,you’ll be able to make the most of any library that provides a functioning LLM.
One other vital library is FAISS. Which is a extremely environment friendly library for similarity search and clustering of dense vectors. It permits the RAG system to carry out fast searches over giant datasets, which is important for real-time data retrieval. Related libraries that may carry out the identical process do embody Pinecone.
Different libraries which might be used all through the code embody such pandas and numpy which permit for environment friendly knowledge manipulation and numerical operations, that are important in processing and analyzing giant datasets.
Be aware: RAG programs supply an excessive amount of flexibility, permitting you to tailor them to your particular wants. Whether or not you are working with a specific LLM, dealing with numerous knowledge codecs, or selecting a selected vector database, you’ll be able to choose and customise libraries to greatest fit your targets. This adaptability ensures that your RAG system might be optimized for the duty at hand, delivering extra correct and environment friendly outcomes.
import os
import pandas as pd
import numpy as np
import faiss
from bs4 import BeautifulSoup
from langchain.vectorstores import FAISS
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, pipeline
import torch
from langchain.llms import HuggingFacePipeline
from sentence_transformers import SentenceTransformer
from transformers import AutoModelForCausalLM, AutoTokenizer
Step 3: Defining Our Llama Mannequin
Outline the mannequin checkpoint path to your Llama 3 mannequin.
model_checkpoint="/kaggle/enter/llama-3/transformers/8b-hf/1"
Load the unique configuration instantly from the checkpoint.
model_config = AutoConfig.from_pretrained(model_checkpoint, trust_remote_code=True)
Allow gradient checkpointing to avoid wasting reminiscence.
model_config.gradient_checkpointing = True
Load the mannequin with the adjusted configuration.
mannequin = AutoModelForCausalLM.from_pretrained(
model_checkpoint,
config=model_config,
trust_remote_code=True,
device_map='auto'
)
Load the tokenizer.
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
The above part initializes the Llama 3 mannequin and its tokenizer. It masses the mannequin configuration, adjusts the rope_scaling parameters to make sure they’re accurately formatted, after which masses the mannequin and tokenizer.
Shifting on, we are going to create a textual content era pipeline with blended precision (fp16).
text_generation_pipeline = pipeline(
"text-generation",
mannequin=mannequin,
tokenizer=tokenizer,
torch_dtype=torch.float16,
max_length=256, # Additional cut back the max size to avoid wasting reminiscence
device_map="auto",
truncation=True # Guarantee sequences are truncated to max_length
)
Initialize Hugging Face LLM pipeline.
llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
Confirm the setup with a immediate.
immediate = """
person
Good day it's good to fulfill you!
assistant
"""
output = llm(immediate)
print(output)
This creates a textual content era pipeline utilizing the Llama 3 mannequin and verifies its performance by producing a easy response to a greeting immediate.
Step 4: Defining the Helper Capabilities
load_and_process_html(file_path) Perform
The load_and_process_html perform is accountable for loading the HTML content material of economic paperwork and extracting the related textual content from them. Since monetary paperwork might include a mixture of structured and unstructured knowledge, this perform tries to extract textual content from numerous HTML tags like <p>, <div>, and <span>. By doing so, it ensures that each one the vital data embedded inside completely different components of the doc is captured.
With out this perform, it could be difficult to effectively parse and extract significant content material from HTML paperwork, particularly given their complexity. The perform additionally incorporates debugging steps to confirm that the right content material is being extracted, making it simpler to troubleshoot points with knowledge extraction.
def load_and_process_html(file_path):
with open(file_path, 'r', encoding='latin-1') as file:
raw_html = file.learn()
# Debugging: Print the start of the uncooked HTML content material
print(f"Uncooked HTML content material (first 500 characters): {raw_html[:500]}")
soup = BeautifulSoup(raw_html, 'html.parser')
# Strive completely different tags if <p> would not exist
texts = [p.get_text() for p in soup.find_all('p')]
# If no <p> tags discovered, strive different tags like <div>
if not texts:
texts = [div.get_text() for div in soup.find_all('div')]
# If nonetheless no texts discovered, strive <span> or print extra of the HTML content material
if not texts:
texts = [span.get_text() for span in soup.find_all('span')]
# Closing debugging print to make sure texts are populated
print(f"Pattern texts after parsing: {texts[:5]}")
return texts
create_and_store_embeddings(texts) Perform
The create_and_store_embeddings perform converts the extracted texts into embeddings, that are numerical representations of the textual content. These embeddings are important as a result of they permit the RAG system to grasp and course of the textual content material semantically. The embeddings are then saved in a vector database utilizing FAISS, enabling environment friendly similarity search.
def create_and_store_embeddings(texts):
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
if not texts:
increase ValueError("The texts checklist is empty. Make sure the HTML file is accurately parsed and incorporates textual content tags.")
vectors = mannequin.encode(texts, convert_to_tensor=True)
vectors = vectors.cpu().detach().numpy() # Convert tensor to numpy array
# Debugging: Print shapes to make sure they're right
print(f"Vectors form: {vectors.form}")
# Guarantee that there's no less than one vector and it has the right dimensions
if vectors.form[0] == 0 or len(vectors.form) != 2:
increase ValueError("The vectors array is empty or has incorrect dimensions.")
index = faiss.IndexFlatL2(vectors.form[1]) # Initialize FAISS index
index.add(vectors) # Add vectors to the index
return index, vectors, texts
retrieve_and_generate(question, index, texts, vectors, ok=1) Perform
The retrieve perform handles the core retrieval strategy of the RAG system. It takes a person’s question, converts it into an embedding, after which performs a similarity search throughout the vector database to search out probably the most related texts. The perform returns the highest ok most related paperwork, which the LLM will use to generate a response. As an example, in our instance we will probably be returning the highest 5 related paperwork.
def retrieve_and_generate(question, index, texts, vectors, ok=1):
torch.cuda.empty_cache() # Clear the cache
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
query_vector = mannequin.encode([query], convert_to_tensor=True)
query_vector = query_vector.cpu().detach().numpy()
# Debugging: Print shapes to make sure they're right
print(f"Question vector form: {query_vector.form}")
if query_vector.form[1] != vectors.form[1]:
increase ValueError("Question vector dimension doesn't match the index vectors dimension.")
D, I = index.search(query_vector, ok)
retrieved_texts = [texts[i] for i in I[0]] # Guarantee that is right
# Restrict the variety of retrieved texts to keep away from overwhelming the mannequin
context = " ".be part of(retrieved_texts[:2]) # Use solely the primary 2 retrieved texts
# Create a immediate utilizing the context and the unique question
immediate = f"Primarily based on the next context:n{context}nnAnswer the query: {question}nnAnswer:. If you do not know the reply, return that you simply can't know."
# Generate the reply utilizing the LLM
generated_response = llm(immediate)
# Return the generated response
return generated_response.strip()
Step 5: Loading and Processing the Information
In terms of loading and processing knowledge, there are numerous strategies relying on the information sort and format. On this tutorial, we deal with processing HTML information containing monetary paperwork. We use the load_and_process_html perform that we outlined above to learn the HTML content material and extract the textual content, which is then remodeled into embeddings for environment friendly search and retrieval. You’ll find the hyperlink to the information we’re utilizing right here.
# Load and course of the HTML file
file_path = "/kaggle/enter/s1-allbirds-document/S-1-allbirds-documents.htm"
texts = load_and_process_html(file_path)
# Create and retailer embeddings within the vector retailer
vector_store, vectors, texts = create_and_store_embeddings(texts)
Step 6: Testing Our Mannequin
On this part, we’re going to take a look at our RAG system by utilizing the next instance queries:


As proven above, the llama 3 mannequin takes within the context retrieved by our retrieval system and utilizing it generates an updated and a extra educated reply to our question.


Above is one other question that the mode was able to replying to utilizing extra context from our vector database.


Lastly, once we requested our mannequin the above given question, the mannequin replied that no particular particulars the place given that may help in it answering the given question. You’ll find the hyperlink to the pocket book to your reference right here.
What’s OCR?
Monetary paperwork like S-1 filings, Okay-1 varieties, and financial institution statements include important knowledge about an organization’s monetary well being and operations. Information extraction from such paperwork is complicated as a result of mixture of structured and unstructured content material, akin to tables and narrative textual content. In circumstances the place S-1 and Okay-1 paperwork are in picture or non-readable PDF file codecs, OCR is important. It permits the conversion of those codecs into textual content that machines can course of, making it attainable to combine them into RAG programs. This ensures that each one related data, whether or not structured or unstructured, might be precisely extracted by using these AI and Machine studying algorithms.
How Nanonets Can Be Used to Improve RAG Techniques
Nanonets is a robust AI-driven platform that not solely gives superior OCR options but in addition permits the creation of customized knowledge extraction fashions and RAG (Retrieval-Augmented Era) use circumstances tailor-made to your particular wants. Whether or not coping with complicated monetary paperwork, authorized contracts, or some other intricate datasets, Nanonets excels at processing diversified layouts with excessive accuracy.
By integrating Nanonets into your RAG system, you’ll be able to harness its superior knowledge extraction capabilities to transform giant volumes of information into machine-readable codecs like Excel and CSV. This ensures your RAG system has entry to probably the most correct and up-to-date data, considerably enhancing its potential to generate exact, contextually related responses.
Past simply knowledge extraction, Nanonets may also construct full RAG-based options to your group. With the power to develop tailor-made purposes, Nanonets empowers you to enter queries and obtain exact outputs derived from the particular knowledge you’ve fed into the system. This personalized strategy streamlines workflows, automates knowledge processing, and permits your RAG system to ship extremely related insights and solutions, all backed by the in depth capabilities of Nanonets’ AI expertise.

The Takeaways
By now, you must have a stable understanding of find out how to construct a Retrieval-Augmented Era (RAG) system for monetary paperwork utilizing the Llama 3 mannequin. This tutorial demonstrated find out how to rework an S-1 monetary doc into phrase embeddings and use them to generate correct and contextually related responses to complicated queries.
Now that you’ve got realized the fundamentals of constructing a RAG system for monetary paperwork, it is time to put your information into apply. Begin by constructing your individual RAG programs and think about using OCR software program options just like the Nanonets API to your doc processing wants. By leveraging these highly effective instruments, you’ll be able to extract knowledge related to your use circumstances and improve your evaluation capabilities, supporting higher decision-making and detailed monetary evaluation within the monetary sector.
[ad_2]