[ad_1]
The sector of pure language processing has made substantial strides with the arrival of Massive Language Fashions (LLMs), which have proven exceptional proficiency in duties akin to query answering. These fashions, skilled on in depth datasets, can generate extremely believable and contextually acceptable responses. Nonetheless, regardless of their success, LLMs need assistance coping with knowledge-intensive queries. Particularly, these queries usually require up-to-date info or contain obscure details that the mannequin may need but to come across throughout coaching. This limitation can result in factual inaccuracies or the era of hallucinated content material, significantly when the mannequin is pressed for particulars exterior its saved data. The issue turns into much more pronounced when precision and reliability are paramount, akin to in medical or scientific inquiries.
A central problem in growing and making use of LLMs is attaining an optimum steadiness between accuracy and processing effectivity. When LLMs are tasked with answering advanced queries that require integrating info from varied sources, they usually need assistance managing lengthy contexts. Because the variety of related paperwork will increase, so does the complexity of reasoning, which may overwhelm the mannequin’s capability to course of info effectively. This inefficiency slows the response era and will increase the chance of errors, significantly in situations the place the mannequin should sift by way of in depth contextual info to seek out probably the most related particulars. The necessity for programs that may effectively incorporate exterior data, lowering each latency and the danger of inaccuracies, is thus a essential space of analysis in pure language processing.
Researchers have developed strategies like Retrieval Augmented Era (RAG), which integrates exterior data sources straight into the generative technique of LLMs. Conventional RAG programs retrieve a number of paperwork associated to the question and incorporate them into the mannequin’s enter to make sure a radical understanding of the subject. Whereas this strategy has confirmed efficient in lowering factual errors, it introduces new challenges. Together with a number of paperwork considerably will increase the enter size, which, in flip, can decelerate the inference course of and complicate the reasoning required to generate correct responses. Some superior RAG programs try to refine the standard of the retrieved paperwork to enhance the contextual info offered to the LLM. Nonetheless, these strategies usually deal with enhancing accuracy solely after adequately addressing the related latency points, which stay a major bottleneck within the sensible software of those fashions.
Researchers from the College of California San Diego, Google Cloud AI Analysis, Google DeepMind, and Google Cloud AI launched a novel strategy known as Speculative Retrieval Augmented Era (Speculative RAG). This framework innovatively combines the strengths of each specialist and generalist language fashions to enhance effectivity and accuracy in response era. The core concept behind Speculative RAG is to leverage a smaller, specialist LM that may generate a number of drafts of potential solutions in parallel. Every draft is created from a definite subset of paperwork retrieved based mostly on the question to seize various views and scale back redundancy. As soon as these drafts are generated, a bigger, generalist LM steps in to confirm them. The generalist LM evaluates the coherence and relevance of every draft, finally deciding on probably the most correct one for the ultimate response. This technique successfully reduces the enter token rely per draft, enhancing the response era course of’s effectivity with out compromising the solutions’ accuracy.
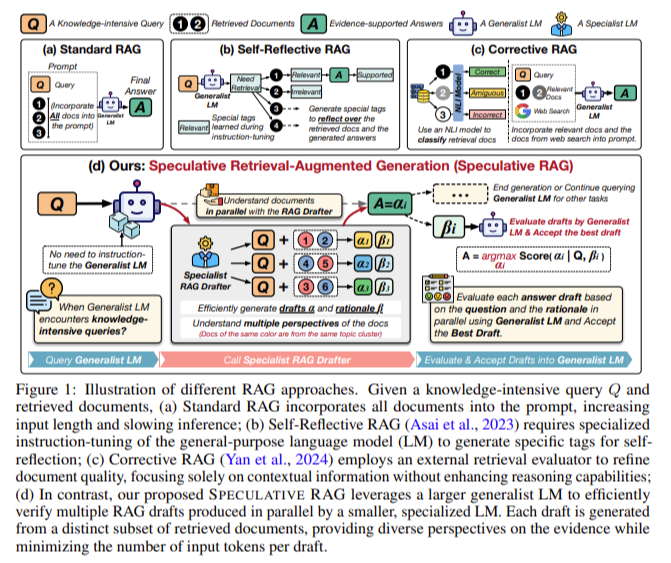
Speculative RAG employs a divide-and-conquer technique that partitions retrieved paperwork into subsets based mostly on content material similarity. The paperwork are grouped utilizing clustering strategies, and one doc from every cluster is sampled to kind a various subset. These subsets are then processed by the specialist LM, which generates reply drafts together with corresponding rationales. The generalist LM then evaluates these drafts by calculating a confidence rating based mostly on the coherence of the draft and its reasoning. This strategy minimizes redundancy within the retrieved paperwork and ensures that the ultimate reply is knowledgeable by a number of views, thereby enhancing the general high quality and reliability of the response.
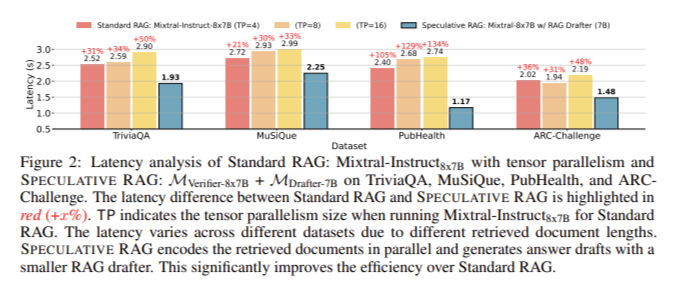
The efficiency of Speculative RAG has been rigorously examined towards conventional RAG strategies throughout varied benchmarks, together with TriviaQA, PubHealth, and ARC-Problem. The outcomes are compelling: Speculative RAG enhances accuracy by as much as 12.97% on the PubHealth benchmark whereas lowering latency by 51%. Within the TriviaQA benchmark, the tactic achieved an accuracy enchancment of two.15% and a latency discount of 23.41%. On the ARC-Problem benchmark, the accuracy elevated by 2.14%, with a corresponding latency discount of 26.73%. These figures underscore the effectiveness of the Speculative RAG framework in delivering high-quality responses extra effectively than standard RAG programs.

In conclusion, Speculative RAG successfully addresses the restrictions of conventional RAG programs by strategically combining the strengths of smaller, specialist language fashions with bigger, generalist ones. The strategy’s means to generate a number of drafts in parallel, scale back redundancy, and leverage various views ensures that the ultimate output is correct and effectively produced. Speculative RAG’s substantial enhancements in accuracy and latency throughout a number of benchmarks spotlight its potential to set new requirements in making use of LLMs for advanced, knowledge-intensive queries. As pure language processing continues to evolve, approaches like Speculative RAG will doubtless play an important position in enhancing language fashions’ capabilities and sensible functions in varied domains.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.
[ad_2]