[ad_1]
Mannequin distillation is a technique for creating interpretable machine studying fashions by utilizing an easier “scholar” mannequin to copy the predictions of a posh “instructor” mannequin. Nevertheless, if the scholar mannequin’s efficiency varies considerably with totally different coaching datasets, its explanations might should be extra dependable. Present strategies for stabilizing distillation contain producing ample pseudo-data, however these strategies are sometimes tailor-made to particular varieties of scholar fashions. Methods like assessing the steadiness of choice standards in tree fashions or characteristic choice in linear fashions are employed to deal with variability. These approaches, whereas helpful, are restricted by their dependence on the actual construction of the scholar mannequin.
Researchers from UC Berkeley and the College of Pennsylvania suggest a generic methodology to stabilize mannequin distillation utilizing a central restrict theorem strategy. Their framework begins with a number of candidate scholar fashions, evaluating how nicely they align with the instructor mannequin. They make use of quite a few testing frameworks to find out the required pattern measurement for constant outcomes throughout totally different pseudo-samples. This methodology is demonstrated on choice timber, falling rule lists, and symbolic regression fashions, with purposes examined on Mammographic Mass and Breast Most cancers datasets. The research additionally contains theoretical evaluation utilizing a Markov course of and sensitivity evaluation on components equivalent to mannequin complexity and pattern measurement.
The research presents a sturdy strategy to secure mannequin distillation by deriving asymptotic properties for common loss based mostly on the central restrict theorem. It makes use of this framework to find out the chance {that a} fastened mannequin construction might be chosen based mostly on totally different pseudo samples and calculate the required pattern measurement to manage this chance. Moreover, researchers implement a number of testing procedures to account for competing fashions and guarantee stability in mannequin choice. The strategy includes producing artificial information, choosing the right scholar mannequin from candidate constructions, and adjusting pattern sizes iteratively till a major mannequin is recognized.
The researchers particularly deal with three intelligible scholar fashions—choice timber, falling rule lists, and symbolic regression—demonstrating their applicability in offering interpretable and secure mannequin explanations. Utilizing Monte Carlo simulations, Bayesian sampling, and genetic programming, we generate numerous candidate fashions and classify them into equivalence lessons based mostly on their constructions. The strategy contrasts with ensemble strategies by specializing in stability and reproducibility in mannequin choice, making certain constant explanations for the instructor mannequin throughout varied information samples.
The experiments on two datasets utilizing a generic mannequin distillation algorithm, specializing in sensitivity evaluation of key components. The setup contains binary classification with cross-entropy loss, a set random forest instructor mannequin, and artificial information era. Experiments contain 100 runs with various seeds. Hyperparameters embrace a significance stage (alpha) of 0.05, an preliminary pattern measurement of 1000, and a most size of 100,000. Analysis metrics cowl interpretation stability and scholar mannequin constancy. Outcomes present stabilization improves mannequin construction consistency, particularly in characteristic choice. Sensitivity evaluation reveals that rising candidate fashions and pattern measurement enhances stability, whereas complicated fashions require bigger samples.
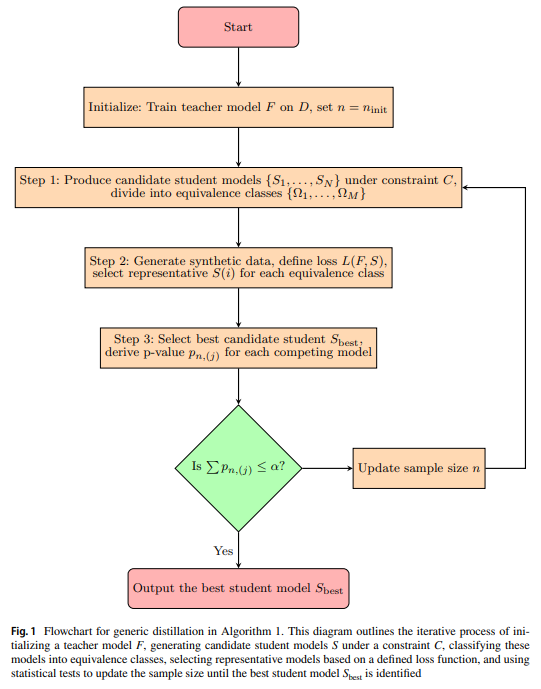
The research introduces a secure mannequin distillation methodology utilizing speculation testing and central restrict theorem-based check statistics. The strategy ensures that sufficient pseudo-data is generated to pick out a constant scholar mannequin construction from candidates reliably. Theoretical evaluation frames the issue as a Markov course of, offering bounds on stabilization problem with complicated fashions. Empirical outcomes validate the strategy’s effectiveness and spotlight the problem of distinguishing complicated fashions with out in depth pseudo-data. Future work contains refining theoretical evaluation with Berry-Esseen bounds and Donsker lessons, addressing instructor mannequin uncertainty, and exploring various multiple-testing procedures.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]