[ad_1]
The principle problem in creating superior visible language fashions (VLMs) lies in enabling these fashions to successfully course of and perceive lengthy video sequences that comprise intensive contextual info. Lengthy-context understanding is essential for functions resembling detailed video evaluation, autonomous techniques, and real-world AI implementations the place duties require the comprehension of advanced, multi-modal inputs over prolonged durations. Nonetheless, present fashions are restricted of their skill to deal with lengthy sequences, which restricts their efficiency and usefulness in duties requiring deep contextual evaluation. This problem is critical as a result of overcoming it will unlock the potential for AI techniques to carry out extra subtle duties in actual time and throughout varied domains.
Current strategies designed to deal with long-context vision-language duties typically encounter scalability and effectivity points. Approaches resembling Ring-Fashion Sequence Parallelism and Megatron-LM have prolonged context size in language fashions however battle when utilized to multi-modal duties that contain each visible and textual information. These strategies are hindered by their computational calls for, making them impractical for real-time functions or duties requiring the processing of very lengthy sequences. Moreover, most visible language fashions are optimized for brief contexts, limiting their effectiveness for longer video sequences. These constraints forestall AI fashions from attaining the required efficiency ranges in duties that demand prolonged context understanding, resembling video summarization and long-form video captioning.
A staff of researchers from NVIDIA, MIT, UC Berkeley, and UT Austin proposes LongVILA, an modern strategy that gives a full-stack resolution for long-context visible language fashions. LongVILA introduces the Multi-Modal Sequence Parallelism (MM-SP) system, which considerably enhances the effectivity of long-context coaching and inference by enabling fashions to course of sequences as much as 2 million tokens in size utilizing 256 GPUs. This method is extra environment friendly than current strategies, attaining a 2.1× – 5.7× speedup in comparison with Ring-Fashion Sequence Parallelism and a 1.1× – 1.4× enchancment over Megatron-LM. The novelty of LongVILA lies in its skill to scale context size whereas seamlessly integrating with frameworks like Hugging Face Transformers. The five-stage coaching pipeline additional enhances the mannequin’s capabilities, specializing in multi-modal alignment, large-scale pre-training, context extension, and supervised fine-tuning, resulting in substantial efficiency enhancements on lengthy video duties.
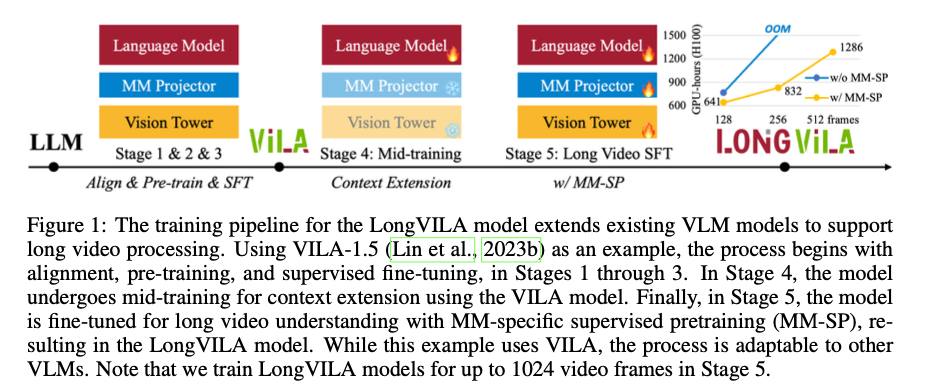
The muse of LongVILA is the MM-SP system, designed to deal with the coaching and inference of long-context VLMs by distributing computational hundreds throughout a number of GPUs. The system employs a two-stage sharding technique that ensures balanced processing of each the picture encoder and the language modeling phases. This technique is essential for effectively dealing with the varied information sorts concerned in multi-modal duties, notably when processing extraordinarily lengthy video sequences. The coaching pipeline consists of 5 phases: multi-modal alignment, large-scale pre-training, short-supervised fine-tuning, context extension, and long-supervised fine-tuning. Every stage incrementally extends the mannequin’s functionality from dealing with brief contexts to processing lengthy video sequences with as much as 1024 frames. A brand new dataset was additionally developed for lengthy video instruction-following, comprising 15,292 movies, every round 10 minutes lengthy, to help the ultimate supervised fine-tuning stage.
The LongVILA strategy achieves substantial enhancements in dealing with lengthy video duties, notably in its skill to course of prolonged sequences with excessive accuracy. The mannequin demonstrated a major 99.5% accuracy when processing movies with a context size of 274,000 tokens, far exceeding the capabilities of earlier fashions that had been restricted to shorter sequences. Moreover, LongVILA-8B constantly outperforms current state-of-the-art fashions on benchmarks for video duties of various lengths, showcasing its superior skill to handle and analyze lengthy video content material successfully. The efficiency beneficial properties achieved by LongVILA spotlight its effectivity and scalability, making it a number one resolution for duties that require deep contextual understanding over prolonged sequences.

In conclusion, LongVILA represents a major development within the discipline of AI, notably for duties requiring long-context understanding in multi-modal settings. By providing a complete resolution that features a novel sequence parallelism system, a multi-stage coaching pipeline, and specialised datasets, LongVILA successfully addresses the important problem of processing lengthy video sequences. This technique not solely improves the scalability and effectivity of visible language fashions but in addition units a brand new commonplace for efficiency in lengthy video duties, marking a considerable contribution to the development of AI analysis.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]