[ad_1]
Introduction
Within the second a part of our sequence on constructing a RAG utility on a Raspberry Pi, we’ll increase on the muse we laid within the first half, the place we created and examined the core pipeline. Within the first half, we created the core pipeline and examined it to make sure every little thing labored as anticipated. Now, we’re going to take issues a step additional by constructing a FastAPI utility to serve our RAG pipeline and making a Reflex app to present customers a easy and interactive approach to entry it. This half will information you thru establishing the FastAPI back-end, designing the front-end with Reflex, and getting every little thing up and working in your Raspberry Pi. By the top, you’ll have an entire, working utility that’s prepared for real-world use.
Studying Goals
- Arrange a FastAPI back-end to combine with the present RAG pipeline and course of queries effectively.
- Design a user-friendly interface utilizing Reflex to work together with the FastAPI back-end and the RAG pipeline.
- Create and take a look at API endpoints for querying and doc ingestion, making certain clean operation with FastAPI.
- Deploy and take a look at the entire utility on a Raspberry Pi, making certain each back-end and front-end parts operate seamlessly.
- Perceive the mixing between FastAPI and Reflex for a cohesive RAG utility expertise.
- Implement and troubleshoot FastAPI and Reflex parts to supply a totally operational RAG utility on a Raspberry Pi.
In the event you missed the earlier version, you’ll want to test it out right here: Self-Internet hosting RAG Purposes on Edge Gadgets with Langchain and Ollama – Half I.
This text was revealed as part of the Knowledge Science Blogathon.
Creating Python Surroundings
Earlier than we begin with creating the appliance we have to setup the atmosphere. Create an atmosphere and set up the beneath dependencies:
deeplake
boto3==1.34.144
botocore==1.34.144
fastapi==0.110.3
gunicorn==22.0.0
httpx==0.27.0
huggingface-hub==0.23.4
langchain==0.2.6
langchain-community==0.2.6
langchain-core==0.2.11
langchain-experimental==0.0.62
langchain-text-splitters==0.2.2
langsmith==0.1.83
marshmallow==3.21.3
numpy==1.26.4
pandas==2.2.2
pydantic==2.8.2
pydantic_core==2.20.1
PyMuPDF==1.24.7
PyMuPDFb==1.24.6
python-dotenv==1.0.1
pytz==2024.1
PyYAML==6.0.1
reflex==0.5.6
requests==2.32.3
reflex==0.5.6
reflex-hosting-cli==0.1.13As soon as the required packages are put in, we have to have the required fashions current within the machine. We’ll do that utilizing Ollama. Observe the steps from Half-1 of this text to obtain each the language and embedding fashions. Lastly, create two directories for the back-end and front-end functions.
As soon as the fashions are pulled utilizing Ollama, we’re able to construct the ultimate utility.
Creating the Again-Finish with FastAPI
Within the Half-1 of this text, now we have constructed the RAG pipeline having each the Ingestion and QnA modules. We’ve examined each the pipelines utilizing some paperwork and so they had been completely working. Now we have to wrap the pipeline with FastAPI to create consumable API. It will assist us combine it with any front-end utility like Streamlit, Chainlit, Gradio, Reflex, React, Angular and so on. Let’s begin by constructing a construction for the appliance. Following the construction is totally non-compulsory, however be certain that to verify the dependency imports if you happen to observe a special construction to create the app.
Under is the tree construction we are going to observe:
backend
├── app.py
├── necessities.txt
└── src
├── config.py
├── doc_loader
│ ├── base_loader.py
│ ├── __init__.py
│ └── pdf_loader.py
├── ingestion.py
├── __init__.py
└── qna.pyLet’s begin with the config.py. This file will include all of the configurable choices for the appliance, just like the Ollama URL, LLM identify and the embeddings mannequin identify. Under is an instance:
LANGUAGE_MODEL_NAME = "phi3"
EMBEDDINGS_MODEL_NAME = "nomic-embed-text"
OLLAMA_URL = "http://localhost:11434"The base_loader.py file accommodates the mum or dad doc loader class that can be inherited by youngsters doc loader. On this utility we’re solely working with PDF information, so a Youngster PDFLoader class can be
created that can inherit the BaseLoader class.
Under are the contents of base_loader.py and pdf_loader.py:
# base_loader.py
from abc import ABC, abstractmethod
class BaseLoader(ABC):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
@abstractmethod
async def load_document(self):
move
# pdf_loader.py
import os
from .base_loader import BaseLoader
from langchain.schema import Doc
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
class PDFLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
tremendous().__init__(file_path)
async def load_document(self):
self.file_name = os.path.basename(self.file_path)
loader = PyMuPDFLoader(file_path=self.file_path)
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=1000,
chunk_overlap=200,
)
pages = await loader.aload()
total_pages = len(pages)
chunks = []
for idx, web page in enumerate(pages):
chunks.append(
Doc(
page_content=web page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(total_pages),
}
),
)
)
final_chunks = text_splitter.split_documents(chunks)
return final_chunksWe’ve mentioned the working of pdf_loader within the Half-1 of the article.
Subsequent, let’s construct the Ingestion class. That is similar because the one we constructed within the Half-1 of this text.
Code for Ingestion Class
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from .doc_loader import PDFLoader
class Ingestion:
"""Doc Ingestion pipeline."""
def __init__(self):
strive:
self.embeddings = OllamaEmbeddings(
mannequin=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.vector_store = DeepLake(
dataset_path="knowledge/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
besides Exception as e:
elevate RuntimeError(f"Did not initialize Ingestion system. ERROR: {e}")
async def create_and_add_embeddings(
self,
file: str,
):
strive:
loader = PDFLoader(
file_path=file,
)
chunks = await loader.load_document()
dimension = await self.vector_store.aadd_documents(paperwork=chunks)
return len(dimension)
besides (ValueError, RuntimeError, KeyError, TypeError) as e:
elevate Exception(f"ERROR: {e}")Now that now we have setup the Ingestion class, we’ll go ahead with creating the QnA class. This too is similar because the one we created within the Half-1 of this text.
Code for QnA Class
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain_community.llms.ollama import Ollama
from .doc_loader import PDFLoader
class QnA:
"""Doc Ingestion pipeline."""
def __init__(self):
strive:
self.embeddings = OllamaEmbeddings(
mannequin=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.mannequin = Ollama(
mannequin=cfg.LANGUAGE_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
verbose=True,
temperature=0.2,
)
self.vector_store = DeepLake(
dataset_path="knowledge/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
self.retriever = self.vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"okay": 10,
},
)
besides Exception as e:
elevate RuntimeError(f"Did not initialize Ingestion system. ERROR: {e}")
def create_rag_chain(self):
strive:
system_prompt = """<Directions>nnContext: {context}"
"""
immediate = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(self.mannequin, immediate)
rag_chain = create_retrieval_chain(self.retriever, question_answer_chain)
return rag_chain
besides Exception as e:
elevate RuntimeError(f"Did not create retrieval chain. ERROR: {e}")With this now we have completed creating the code functionalities of the RAG app. Now let’s wrap the app with FastAPI.
Code for the FastAPI Utility
import sys
import os
import uvicorn
from src import QnA, Ingestion
from fastapi import FastAPI, Request, File, UploadFile
from fastapi.responses import StreamingResponse
app = FastAPI()
ingestion = Ingestion()
chatbot = QnA()
rag_chain = chatbot.create_rag_chain()
@app.get("https://www.analyticsvidhya.com/")
def hey():
return {"message": "API Operating in server 8089"}
@app.put up("/question")
async def ask_query(request: Request):
knowledge = await request.json()
query = knowledge.get("query")
async def event_generator():
for chunk in rag_chain.decide("reply").stream({"enter": query}):
yield chunk
return StreamingResponse(event_generator(), media_type="textual content/plain")
@app.put up("/ingest")
async def ingest_document(file: UploadFile = File(...)):
strive:
os.makedirs("information", exist_ok=True)
file_location = f"information/{file.filename}"
with open(file_location, "wb+") as file_object:
file_object.write(file.file.learn())
dimension = await ingestion.create_and_add_embeddings(file=file_location)
return {"message": f"File ingested! Doc depend: {dimension}"}
besides Exception as e:
return {"message": f"An error occured: {e}"}
if __name__ == "__main__":
strive:
uvicorn.run(app, host="0.0.0.0", port=8089)
besides KeyboardInterrupt as e:
print("App stopped!")Let’s breakdown the app by every endpoints:
- First we initialize the FastAPI app, the Ingestion and the QnA objects. We then create a RAG chain utilizing the create_rag_chain methodology of QnA class.
- Our first endpoint is an easy GET methodology. It will assist us know whether or not the app is wholesome or not. Consider it like a ‘Hiya World’ endpoint.
- The second is the question endpoint. This can be a POST methodology and can be used to run the chain. It takes in a request parameter, from which we extract the person’s question. Then we create a asynchronous methodology that acts as an asynchronous wrapper across the chain.stream operate name. We have to do that to permit FastAPI to deal with the LLM’s stream operate name, to get a ChatGPT-like expertise within the chat interface. We then wrap the asynchronous methodology with StreamingResponse class and return it.
- The third endpoint is the ingestion endpoint. It is also a POST methodology that takes in your entire file as bytes as enter. We retailer this file within the native listing after which ingest it utilizing the create_and_add_embeddings methodology of Ingestion class.
Lastly, we run the app utilizing uvicorn bundle, utilizing host and port. To check the app, merely run the appliance utilizing the next command:
python app.py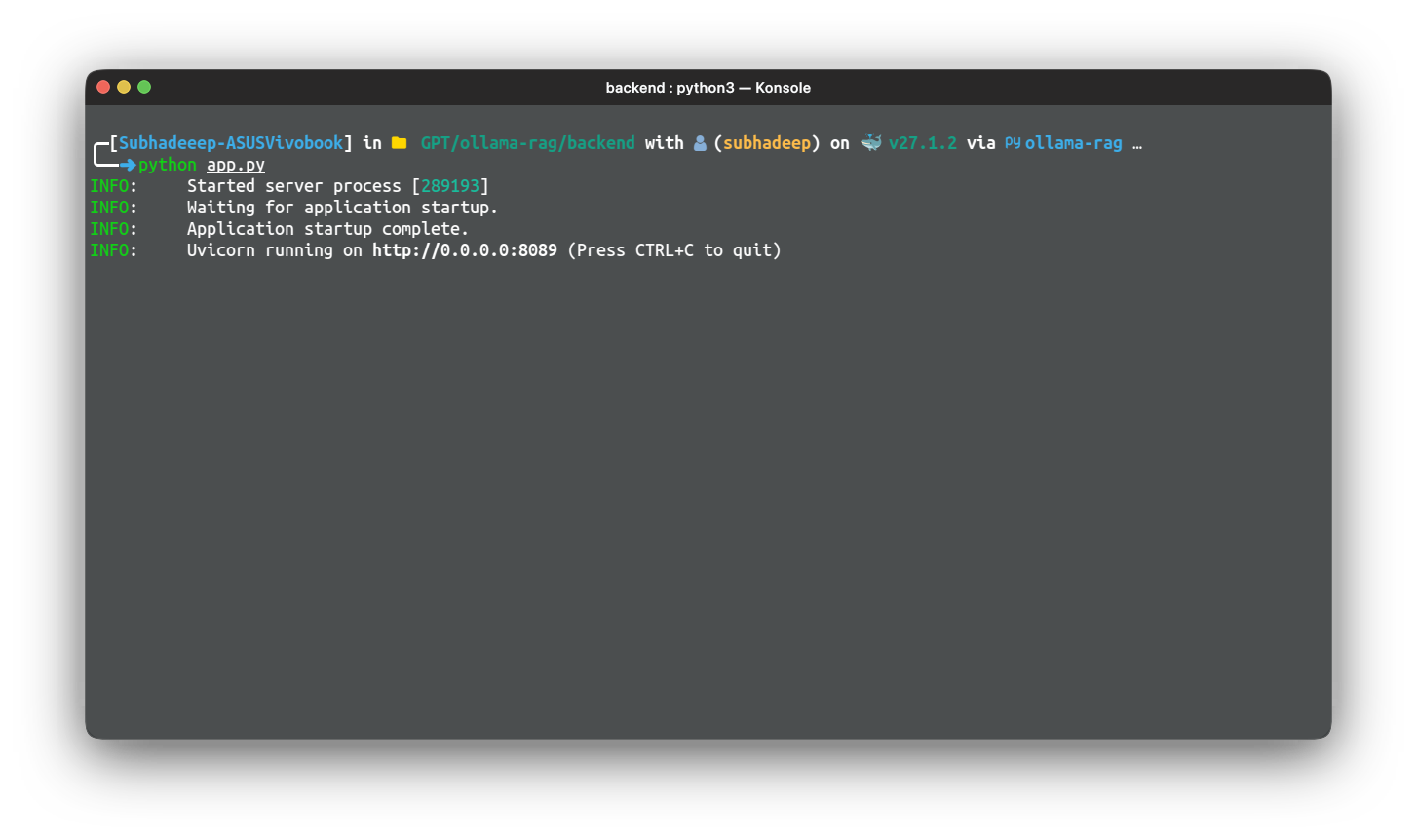
Use a API testing IDE like Postman, Insomnia or Bruno for testing the appliance. You can too use Thunder Shopper extension to do the identical.
Testing the Ingestion endpoint:
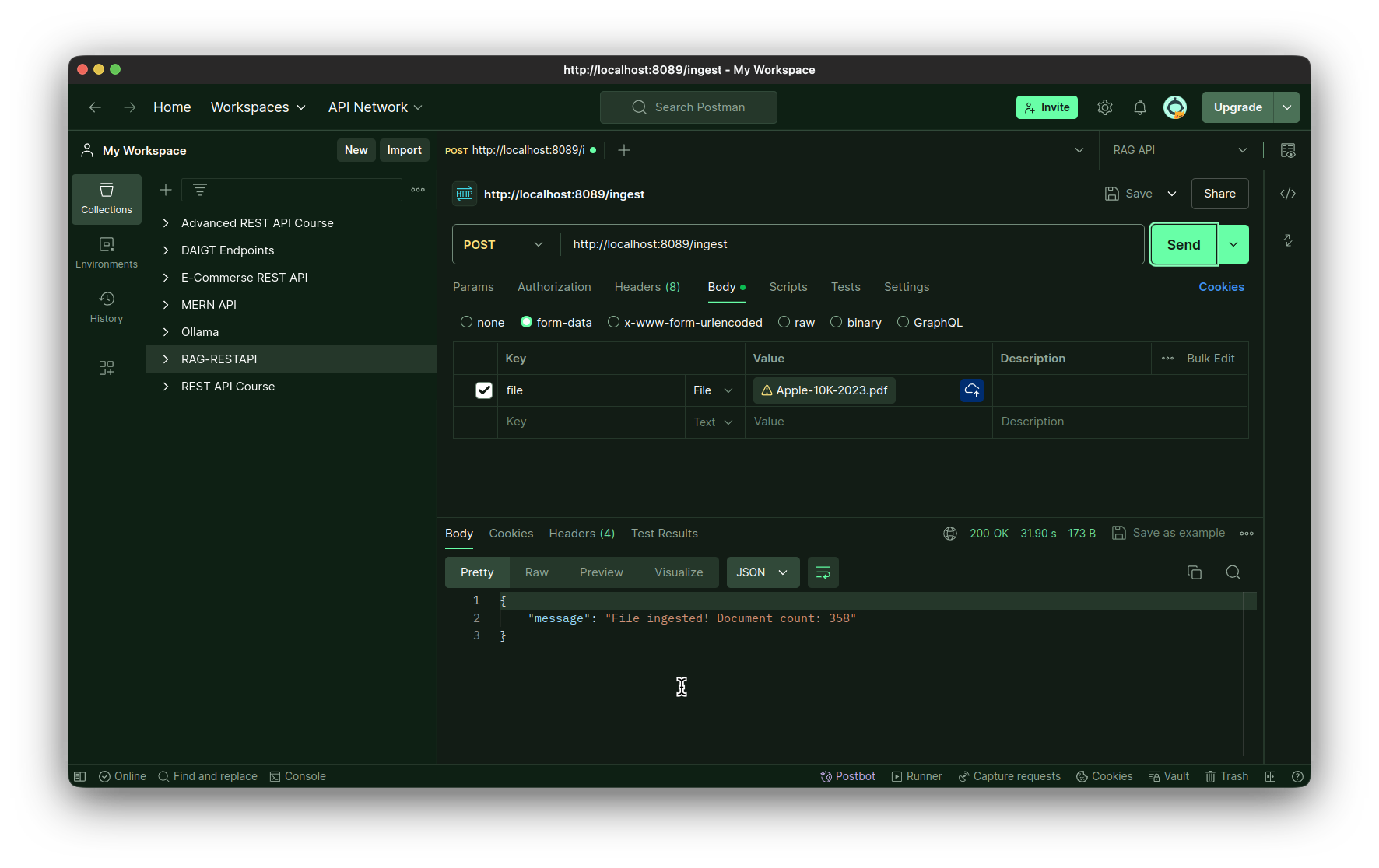
Testing the question endpoint:
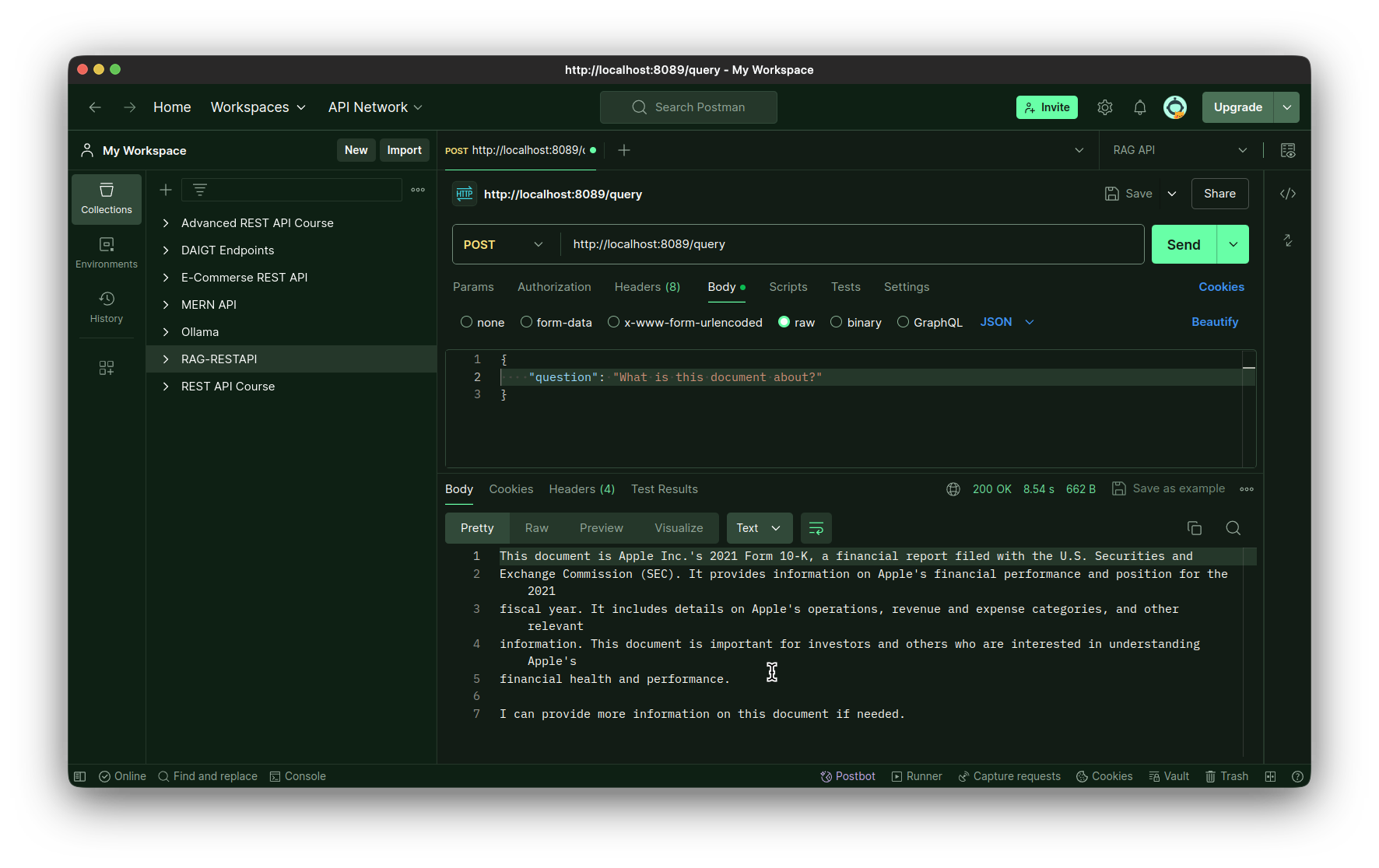
Designing the Entrance-Finish with Reflex
We’ve efficiently created a FastAPI app for the backend of our RAG utility. It’s time to construct our front-end. You may selected any front-end library for this, however for this specific article we are going to construct the front-end utilizing Reflex. Reflex is a python-only front-end library, created to construct net functions, purely utilizing python. It proves us with templates for frequent functions like calculator, picture technology and chatbot. We’ll use the chatbot utility template as a begin for our person interface. Our closing app may have the next construction, so let’s have it right here for reference.
Frontend Listing
We may have a frontend listing for this:
frontend
├── belongings
│ └── favicon.ico
├── docs
│ └── demo.gif
├── chat
│ ├── parts
│ │ ├── chat.py
│ │ ├── file_upload.py
│ │ ├── __init__.py
│ │ ├── loading_icon.py
│ │ ├── modal.py
│ │ └── navbar.py
│ ├── __init__.py
│ ├── chat.py
│ └── state.py
├── necessities.txt
├── rxconfig.py
└── uploaded_filesSteps for Ultimate App
Observe the steps to organize the grounding for the ultimate app.
Step1: Clone the chat template repository within the frontend listing
git clone https://github.com/reflex-dev/reflex-chat.git .Step2: Run the next command to initialize the listing as a reflex app
reflex init
It will setup the reflex app and can be able to run and develop.
Step3: Check the app, use the next command from contained in the frontend listing
reflex run
Let’s begin modifying the parts. First let’s modify the chat.py file.
Under is the code for a similar:
import reflex as rx
from reflex_demo.parts import loading_icon
from reflex_demo.state import QA, State
message_style = dict(
show="inline-block",
padding="0 10px",
border_radius="8px",
max_width=["30em", "30em", "50em", "50em", "50em", "50em"],
)
def message(qa: QA) -> rx.Element:
"""A single query/reply message.
Args:
qa: The query/reply pair.
Returns:
A part displaying the query/reply pair.
"""
return rx.field(
rx.field(
rx.markdown(
qa.query,
background_color=rx.colour("mauve", 4),
colour=rx.colour("mauve", 12),
**message_style,
),
text_align="proper",
margin_top="1em",
),
rx.field(
rx.markdown(
qa.reply,
background_color=rx.colour("accent", 4),
colour=rx.colour("accent", 12),
**message_style,
),
text_align="left",
padding_top="1em",
),
width="100%",
)
def chat() -> rx.Element:
"""Checklist all of the messages in a single dialog."""
return rx.vstack(
rx.field(rx.foreach(State.chats[State.current_chat], message), width="100%"),
py="8",
flex="1",
width="100%",
max_width="50em",
padding_x="4px",
align_self="heart",
overflow="hidden",
padding_bottom="5em",
)
def action_bar() -> rx.Element:
"""The motion bar to ship a brand new message."""
return rx.heart(
rx.vstack(
rx.chakra.kind(
rx.chakra.form_control(
rx.hstack(
rx.enter(
rx.enter.slot(
rx.tooltip(
rx.icon("information", dimension=18),
content material="Enter a query to get a response.",
)
),
placeholder="Kind one thing...",
id="query",
width=["15em", "20em", "45em", "50em", "50em", "50em"],
),
rx.button(
rx.cond(
State.processing,
loading_icon(peak="1em"),
rx.textual content("Ship", font_family="Ubuntu"),
),
kind="submit",
),
align_items="heart",
),
is_disabled=State.processing,
),
on_submit=State.process_question,
reset_on_submit=True,
),
rx.textual content(
"ReflexGPT might return factually incorrect or deceptive responses. Use discretion.",
text_align="heart",
font_size=".75em",
colour=rx.colour("mauve", 10),
font_family="Ubuntu",
),
rx.emblem(margin_top="-1em", margin_bottom="-1em"),
align_items="heart",
),
place="sticky",
backside="0",
left="0",
padding_y="16px",
backdrop_filter="auto",
backdrop_blur="lg",
border_top=f"1px stable {rx.colour('mauve', 3)}",
background_color=rx.colour("mauve", 2),
align_items="stretch",
width="100%",
)The adjustments are minimal from the one current natively within the template.
Subsequent, we are going to edit the chat.py app. That is the primary chat part.
Code for Predominant Chat Element
Under is the code for it:
import reflex as rx
from reflex_demo.parts import chat, navbar, upload_form
from reflex_demo.state import State
@rx.web page(route="/chat", title="RAG Chatbot")
def chat_interface() -> rx.Element:
return rx.chakra.vstack(
navbar(),
chat.chat(),
chat.action_bar(),
background_color=rx.colour("mauve", 1),
colour=rx.colour("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
@rx.web page(route="https://www.analyticsvidhya.com/", title="RAG Chatbot")
def index() -> rx.Element:
return rx.chakra.vstack(
navbar(),
upload_form(),
background_color=rx.colour("mauve", 1),
colour=rx.colour("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
# Add state and web page to the app.
app = rx.App(
theme=rx.theme(
look="darkish",
accent_color="jade",
),
stylesheets=["https://fonts.googleapis.com/css2?family=Ubuntu&display=swap"],
type={
"font_family": "Ubuntu",
},
)
app.add_page(index)
app.add_page(chat_interface)That is the code for the chat interface. We’ve solely added the Font household to the app config, the remainder of the code is identical.
Subsequent let’s edit the state.py file. That is the place the frontend will make name to the API endpoints for response.
Enhancing state.py File
import requests
import reflex as rx
class QA(rx.Base):
query: str
reply: str
DEFAULT_CHATS = {
"Intros": [],
}
class State(rx.State):
chats: dict[str, list[QA]] = DEFAULT_CHATS
current_chat = "Intros"
url: str = "http://localhost:8089/question"
query: str
processing: bool = False
new_chat_name: str = ""
def create_chat(self):
"""Create a brand new chat."""
# Add the brand new chat to the listing of chats.
self.current_chat = self.new_chat_name
self.chats[self.new_chat_name] = []
def delete_chat(self):
"""Delete the present chat."""
del self.chats[self.current_chat]
if len(self.chats) == 0:
self.chats = DEFAULT_CHATS
self.current_chat = listing(self.chats.keys())[0]
def set_chat(self, chat_name: str):
"""Set the identify of the present chat.
Args:
chat_name: The identify of the chat.
"""
self.current_chat = chat_name
@rx.var
def chat_titles(self) -> listing[str]:
"""Get the listing of chat titles.
Returns:
The listing of chat names.
"""
return listing(self.chats.keys())
async def process_question(self, form_data: dict[str, str]):
# Get the query from the shape
query = form_data["question"]
# Verify if the query is empty
if query == "":
return
mannequin = self.openai_process_question
async for worth in mannequin(query):
yield worth
async def openai_process_question(self, query: str):
"""Get the response from the API.
Args:
form_data: A dict with the present query.
"""
# Add the query to the listing of questions.
qa = QA(query=query, reply="")
self.chats[self.current_chat].append(qa)
payload = {"query": query}
# Clear the enter and begin the processing.
self.processing = True
yield
response = requests.put up(self.url, json=payload, stream=True)
# Stream the outcomes, yielding after each phrase.
for answer_text in response.iter_content(chunk_size=512):
# Guarantee answer_text shouldn't be None earlier than concatenation
answer_text = answer_text.decode()
if answer_text shouldn't be None:
self.chats[self.current_chat][-1].reply += answer_text
else:
answer_text = ""
self.chats[self.current_chat][-1].reply += answer_text
self.chats = self.chats
yield
# Toggle the processing flag.
self.processing = FalseOn this file, now we have outlined the URL for the question endpoint. We’ve additionally modified the openai_process_question methodology to ship a POST request to the question endpoint and get the streaming
response, which can be displayed within the chat interface.
Writing Contents of the file_upload.py File
Lastly, let’s write the contents of the file_upload.py file. This part can be displayed at first which is able to permit us to add the file for ingestion.
import reflex as rx
import os
import time
import requests
class UploadExample(rx.State):
importing: bool = False
ingesting: bool = False
progress: int = 0
total_bytes: int = 0
ingestion_url = "http://127.0.0.1:8089/ingest"
async def handle_upload(self, information: listing[rx.UploadFile]):
self.ingesting = True
yield
for file in information:
file_bytes = await file.learn()
file_name = file.filename
information = {
"file": (os.path.basename(file_name), file_bytes, "multipart/form-data")
}
response = requests.put up(self.ingestion_url, information=information)
self.ingesting = False
yield
if response.status_code == 200:
# yield rx.redirect("/chat")
self.show_redirect_popup()
def handle_upload_progress(self, progress: dict):
self.importing = True
self.progress = spherical(progress["progress"] * 100)
if self.progress >= 100:
self.importing = False
def cancel_upload(self):
self.importing = False
return rx.cancel_upload("upload3")
def upload_form():
return rx.vstack(
rx.add(
rx.flex(
rx.textual content(
"Drag and drop file right here or click on to pick file",
font_family="Ubuntu",
),
rx.icon("add", dimension=30),
course="column",
align="heart",
),
id="upload3",
border="1px stable rgb(233, 233,233, 0.4)",
margin="5em 0 10px 0",
background_color="rgb(107,99,246)",
border_radius="8px",
padding="1em",
),
rx.vstack(rx.foreach(rx.selected_files("upload3"), rx.textual content)),
rx.cond(
~UploadExample.ingesting,
rx.button(
"Add",
on_click=UploadExample.handle_upload(
rx.upload_files(
upload_id="upload3",
on_upload_progress=UploadExample.handle_upload_progress,
),
),
),
rx.flex(
rx.spinner(dimension="3", loading=UploadExample.ingesting),
rx.button(
"Cancel",
on_click=UploadExample.cancel_upload,
),
align="heart",
spacing="3",
),
),
rx.alert_dialog.root(
rx.alert_dialog.set off(
rx.button("Proceed to Chat", color_scheme="inexperienced"),
),
rx.alert_dialog.content material(
rx.alert_dialog.title("Redirect to Chat Interface?"),
rx.alert_dialog.description(
"You'll be redirected to the Chat Interface.",
dimension="2",
),
rx.flex(
rx.alert_dialog.cancel(
rx.button(
"Cancel",
variant="gentle",
color_scheme="grey",
),
),
rx.alert_dialog.motion(
rx.button(
"Proceed",
color_scheme="inexperienced",
variant="stable",
on_click=rx.redirect("/chat"),
),
),
spacing="3",
margin_top="16px",
justify="finish",
),
type={"max_width": 450},
),
),
align="heart",
)This part will permit us to add a file and ingest it into the vector retailer. It makes use of the ingest endpoint of our FastAPI app to add and ingest the file. After ingestion, the person can merely transfer
to the chat interface for asking queries.
With this now we have accomplished constructing the front-end for our utility. Now we might want to take a look at the appliance utilizing some doc.
Testing and Deployment
Now let’s take a look at the appliance on some manuals or paperwork. To make use of the appliance, we have to run each the back-end app and the reflex app individually. Run the back-end app from it’s listing utilizing the
following command:
python app.pyAnticipate the FastAPI to start out working. Then in one other terminal occasion run the front-end app utilizing the next command:
reflex runOne the apps are up and working, obtained to the following URL to entry the reflex app. Initially we’d be within the File Add web page. Add a file and press the add button.
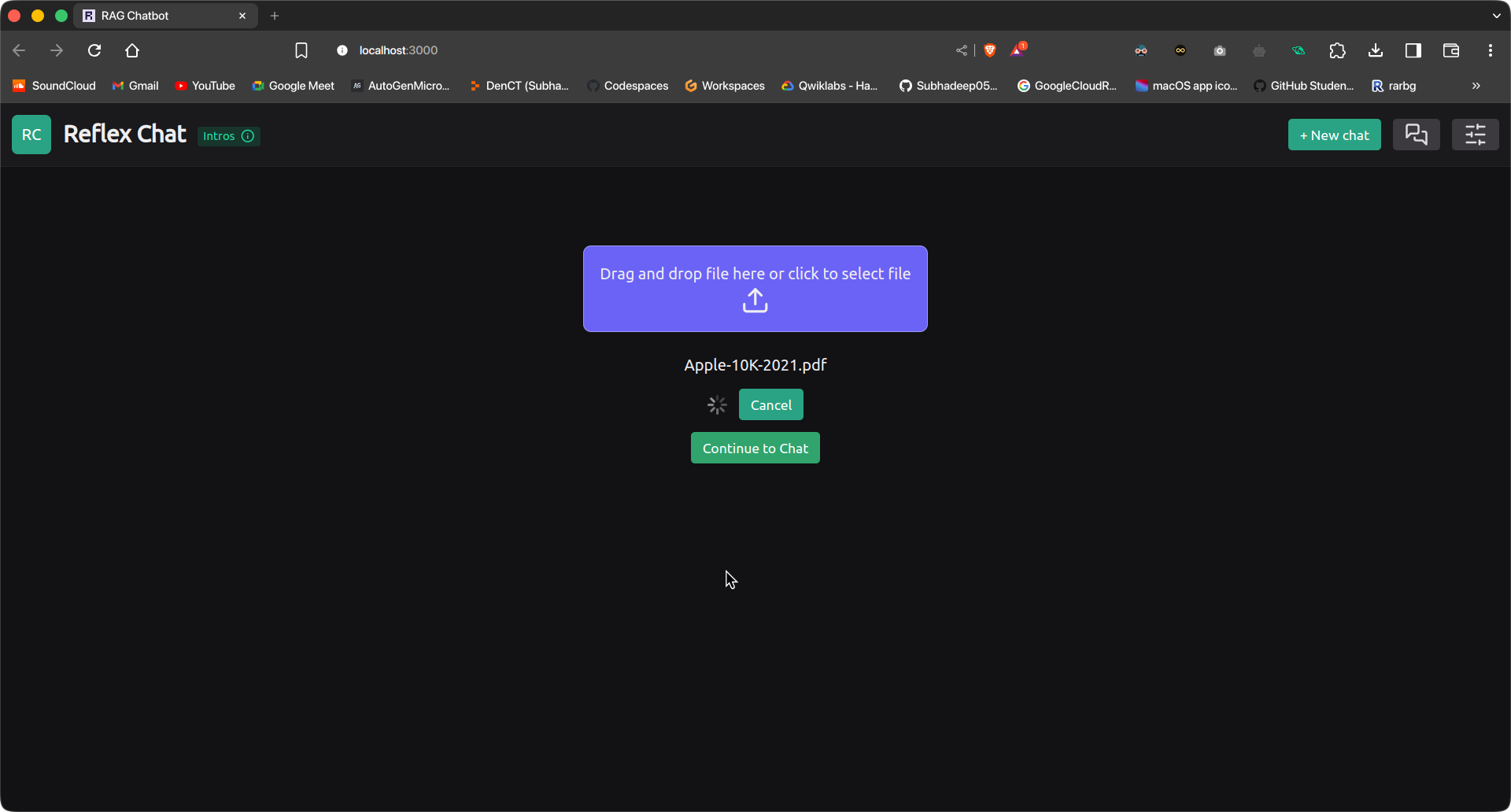
The file can be uploaded and ingested. It will take some time relying on the doc dimension and
the machine specs. As soon as it’s executed, click on on the ‘Proceed to Chat’ button to maneuver to the chat interface. Write your question and press Ship.
Conclusion
On this two half sequence, you’ve now constructed an entire and purposeful RAG utility on a Raspberry Pi, from creating the core pipeline to wrapping it with a FastAPI back-end and growing a Reflex-based front-end. With these instruments, your RAG pipeline is accessible and interactive, offering real-time question processing via a user-friendly net interface. By mastering these steps, you’ve gained precious expertise in constructing and deploying end-to-end functions on a compact, environment friendly platform. This setup opens the door to numerous potentialities for deploying AI-driven functions on resource-constrained gadgets just like the Raspberry Pi, making cutting-edge expertise extra accessible and sensible for on a regular basis use.
Key Takeaways
- An in depth information is supplied on establishing the event atmosphere, together with putting in crucial dependencies and fashions utilizing Ollama, making certain the appliance is prepared for the ultimate construct.
- The article explains learn how to wrap the RAG pipeline in a FastAPI utility, together with establishing endpoints for querying the mannequin and ingesting paperwork, making the pipeline accessible through an internet API.
- The front-end of the RAG utility is constructed utilizing Reflex, a Python-only front-end library. The article demonstrates learn how to modify the chat utility template to create a user-friendly interface for interacting with the RAG pipeline.
- The article guides on integrating the FastAPI backend with the Reflex front-end and deploying the entire utility on a Raspberry Pi, making certain seamless operation and person accessibility.
- Sensible steps are supplied for testing each the ingestion and question endpoints utilizing instruments like Postman or Thunder Shopper, together with working and testing the Reflex front-end to make sure your entire utility capabilities as anticipated.
Often Requested Query
A. There’s a platform named Tailscale that enables your gadgets to be related to a personal safe community, accessible solely to you. You may add your Raspberry Pi and different gadgets to Tailscale gadgets and connect with the VPN to entry your apps, from anyplace throughout the world.
A. That’s the constraint as a consequence of low {hardware} specs of Raspberry Pi. The article is only a head up tutorial on learn how to begin constructing RAG app utilizing Raspberry Pi and Ollama.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Creator’s discretion.
[ad_2]