[ad_1]
Giant language fashions (LLMs) based mostly on autoregressive Transformer Decoder architectures have superior pure language processing with excellent efficiency and scalability. Not too long ago, diffusion fashions have gained consideration for visible era duties, overshadowing autoregressive fashions (AMs). Nevertheless, AMs present higher scalability for large-scale functions and work extra effectively with language fashions, making them extra appropriate for unifying language and imaginative and prescient duties. Latest developments in autoregressive visible era (AVG) have proven promising outcomes, matching or outperforming diffusion fashions in high quality. Regardless of this, there are nonetheless main challenges, particularly in computational effectivity because of the excessive complexity of visible knowledge and the quadratic computational calls for of Transformers.
Current strategies embrace Vector Quantization (VQ) based mostly fashions and State Area Fashions (SSMs) to resolve the challenges in AVG. VQ-based approaches, similar to VQ-VAE, DALL-E, and VQGAN, compress pictures into discrete codes and use AMs to foretell these codes. SSMs, particularly the Mamba household, have proven potential in managing lengthy sequences with linear computational complexity. Latest variations of Mamba for visible duties, like ViM, VMamba, Zigma, and DiM, have explored multi-directional scan methods to seize 2D spatial info. Nevertheless, these strategies add further parameters and computational prices, lowering the pace benefit of Mamba and growing GPU reminiscence necessities.
Researchers from Beijing College of Posts and Telecommunications, College of Chinese language Academy of Sciences, The Hong Kong Polytechnic College, and Institute of Automation, Chinese language Academy of Sciences have proposed AiM, a brand new Autoregressive image era mannequin based mostly on the Mamba framework. It’s developed for high-quality and environment friendly class-conditional picture era, making it the primary mannequin of its type. Goal makes use of positional encoding, offering a brand new and extra generalized adaptive layer normalization technique referred to as adaLN-Group, which optimizes the steadiness between efficiency and parameter rely. Furthermore, AiM has proven state-of-the-art efficiency amongst AMs on the ImageNet 256×256 benchmark whereas attaining quick inference speeds.
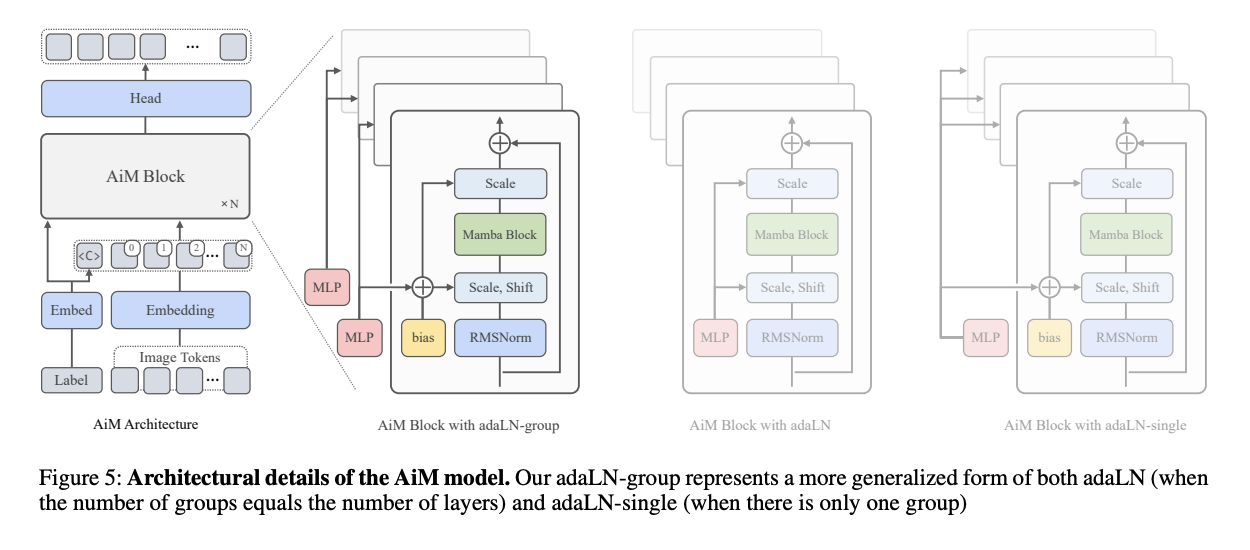
AiM was developed in 4 scales and evaluated on the ImageNet1K benchmark to guage its architectural design, efficiency, scalability, and inference effectivity. It makes use of a picture tokenizer with a 16 downsampling issue, initialized with pre-trained weights from LlamaGen. Every 256×256 picture is tokenized into 256 tokens. The coaching was performed on 80GB A100 GPUs utilizing the AdamW optimizer with particular hyperparameters. The coaching epochs differ between 300 and 350 relying on the mannequin scale, and a dropout fee of 0.1 was utilized to class embeddings for classifier-free steering. Analysis metrics used Frechet Inception Distance (FID) as the first metric to guage the mannequin’s efficiency in picture era duties.
AiM confirmed vital efficiency features because the mannequin measurement and coaching period elevated, with a robust correlation coefficient of -0.9838 between FID scores and mannequin parameters. This proves the AiM’s scalability and the effectiveness of bigger fashions in enhancing picture era high quality. It achieved state-of-the-art efficiency amongst AMs similar to GANs, diffusion fashions, masked generative fashions, and Transformer-based AMs. Furthermore, AiM has a transparent benefit in inference pace in comparison with different fashions, with Transformer-based fashions benefiting from Flash-Consideration and KV Cache optimizations.

In conclusion, researchers have launched Goal, a novel Autoregressive picture era mannequin based mostly on the Mamba framework. This paper explores the potential of Mamba in visible duties, efficiently adapting it to visible era with none requirement for added multi-directional scans. The effectiveness and effectivity of AiM spotlight its scalability and vast applicability in autoregressive visible modeling. Nevertheless, it focuses solely on class-conditional era, with out exploring text-to-image era, offering instructions for future analysis for additional developments within the visible era subject utilizing state area fashions like Mamba.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Here’s a extremely really helpful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.
[ad_2]