[ad_1]
Machine translation, a vital space inside pure language processing (NLP), focuses on creating algorithms to robotically translate textual content from one language to a different. This know-how is crucial for breaking down language obstacles and facilitating international communication. Latest developments in neural machine translation (NMT) have considerably improved translation accuracy and fluency, leveraging deep studying strategies to push the boundaries of what’s attainable on this subject.
The principle problem is the numerous disparity in translation high quality between high-resource and low-resource languages. Excessive-resource languages profit from plentiful coaching information, resulting in superior translation efficiency. In distinction, low-resource languages want extra coaching information and higher translation high quality. This imbalance hinders efficient communication and entry to info for audio system of low-resource languages, an issue that this analysis goals to resolve.
Present analysis consists of information augmentation strategies like back-translation and self-supervised studying on monolingual information to reinforce translation high quality for low-resource languages. Current frameworks contain dense transformer fashions that use feed-forward community layers for the encoder and decoder. Regularization methods reminiscent of Gating Dropout are employed to mitigate overfitting. These strategies, though useful, typically need assistance with the distinctive challenges posed by restricted and poor-quality information obtainable for a lot of low-resource languages.
Researchers from Meta’s Foundational AI Analysis (FAIR) group launched a novel method utilizing Sparsely Gated Combination of Specialists (MoE) fashions to deal with this situation. This progressive methodology incorporates a number of consultants inside the mannequin to deal with completely different features of the interpretation course of extra successfully. The gating mechanism intelligently routes enter tokens to probably the most related consultants, optimizing translation accuracy and lowering interference between unrelated language instructions.
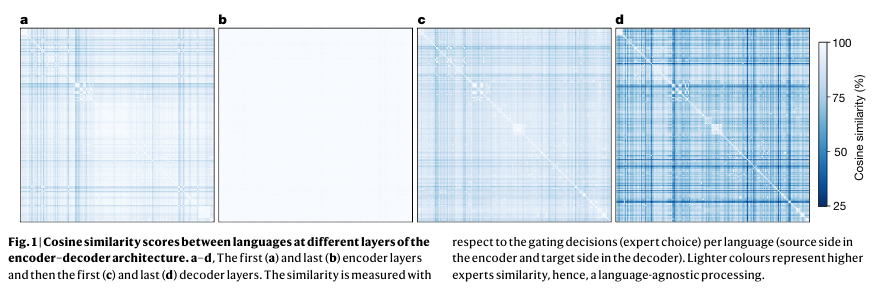
The MoE transformer fashions differ considerably from conventional dense transformers. Within the MoE fashions, some feed-forward community layers within the encoder and decoder are changed with MoE layers. Every MoE layer consists of a number of consultants, every being a feed-forward community and a gating community that decides tips on how to route the enter tokens to those consultants. This construction helps the mannequin higher generalize throughout completely different languages by minimizing interference and optimizing obtainable information.
The researchers employed a technique involving conditional computational fashions. Particularly, they used MoE layers inside the transformer encoder-decoder mannequin, supplemented with gating networks. The MoE mannequin learns to route enter tokens to the corresponding prime two consultants by optimizing a mixture of label-smoothed cross-entropy and an auxiliary load-balancing loss. To additional enhance the mannequin, the researchers designed a regularization technique known as Skilled Output Masking (EOM), which proved simpler than current methods like Gating Dropout.
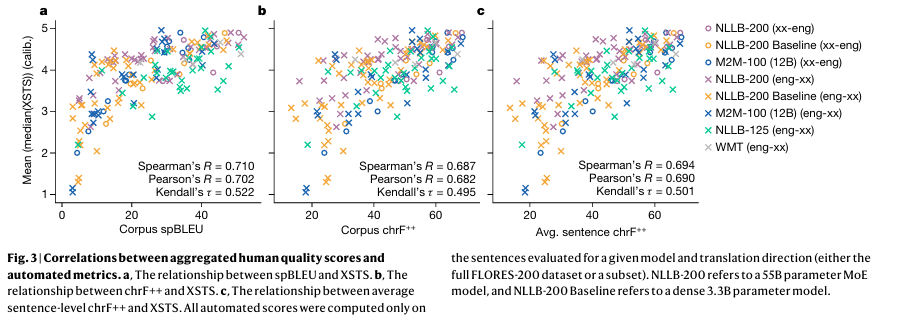
The efficiency and outcomes of this method had been substantial. The researchers noticed a major enchancment in translation high quality for very low-resource languages. Particularly, the MoE fashions achieved a 12.5% enhance in chrF++ scores for translating these languages into English. Moreover, the experimental outcomes on the FLORES-200 growth set for ten translation instructions (together with languages reminiscent of Somali, Southern Sotho, Twi, Umbundu, and Venetian) confirmed that after filtering a median of 30% of parallel sentences, the interpretation high quality improved by 5%, and the added toxicity was decreased by the identical quantity.
To acquire these outcomes, the researchers additionally carried out a complete analysis course of. They used a mixture of automated metrics and human high quality assessments to make sure the accuracy and reliability of their translations. Utilizing calibrated human analysis scores supplied a strong measure of translation high quality, correlating strongly with automated scores and demonstrating the effectiveness of the MoE fashions.
In conclusion, the analysis group from Meta addressed the vital situation of translation high quality disparity between high- and low-resource languages by introducing the MoE fashions. This progressive method considerably enhances translation efficiency for low-resource languages, offering a strong and scalable answer. Their work represents a serious development in machine translation, transferring nearer to the aim of creating a common translation system that serves all languages equally properly.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 44k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]