[ad_1]
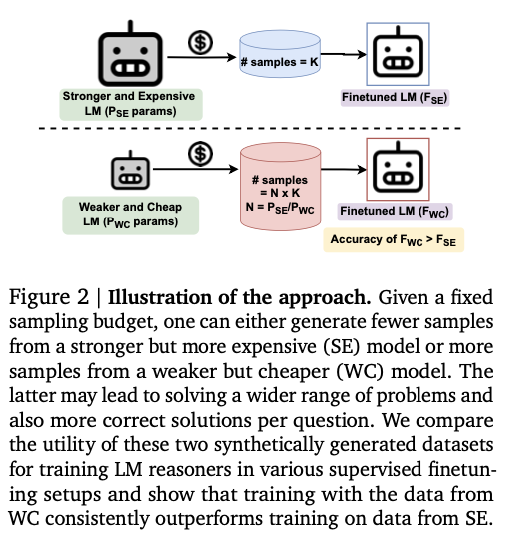
A crucial problem in coaching giant language fashions (LLMs) for reasoning duties is figuring out essentially the most compute-efficient technique for producing artificial information that enhances mannequin efficiency. Historically, stronger and costlier language fashions (SE fashions) have been relied upon to provide high-quality artificial information for fine-tuning. Nevertheless, this method is resource-intensive and restricts the quantity of information that may be generated inside a set computing price range. The primary problem lies in exploring whether or not weaker however cheaper fashions (WC fashions) can generate information that, regardless of being of decrease high quality, may lead to higher or comparable coaching outcomes below the identical computational constraints.
Present strategies for bettering LLM reasoning capabilities embody methods equivalent to information distillation, the place a smaller mannequin learns from a bigger mannequin, and self-improvement, the place fashions are skilled on information they generate themselves. These strategies have confirmed efficient however include vital drawbacks, equivalent to excessive computational prices that restrict the amount and variety of information produced, probably affecting the protection and effectiveness of coaching. This prompts a reassessment of whether or not WC fashions may provide a extra compute-efficient resolution for producing artificial information to coach LLMs successfully.

The researchers from Google DeepMind introduce a novel method that challenges the reliance on SE fashions for artificial information era. They advocate for utilizing WC fashions, which, regardless of their decrease high quality, are less expensive and allow the era of bigger information volumes inside the similar computing price range. This technique is evaluated throughout key metrics: protection, range, and false constructive charge (FPR). The findings present that WC-generated information, regardless of a better FPR, presents better protection and variety in comparison with SE-generated information. The research additionally introduces a weak-to-strong enchancment paradigm, the place a stronger mannequin is enhanced utilizing information generated by a weaker one. Examined throughout varied fine-tuning setups equivalent to information distillation and self-improvement, this technique constantly outperforms conventional approaches. This shift in methodology means that WC fashions can present a extra compute-efficient technique for creating superior LLM reasoners.

The technical particulars contain a comparative evaluation between SE and WC fashions below a set compute price range. Experiments had been carried out utilizing the Gemma2 household of fashions on datasets like MATH and GSM-8K, with Gemma2-9B and Gemma2-27B representing WC and SE fashions, respectively. Artificial information was generated below two totally different sampling budgets (high and low), with the WC mannequin producing thrice extra samples than the SE mannequin inside the similar compute constraints. This information was evaluated primarily based on protection, range, and FPR. Notably, WC-generated information confirmed 11% greater protection and 86% greater range than SE-generated information on the MATH dataset, regardless of a 7% enhance in FPR. These outcomes spotlight the potential of WC fashions to generate extra various and complete coaching information, even with their inherent limitations.
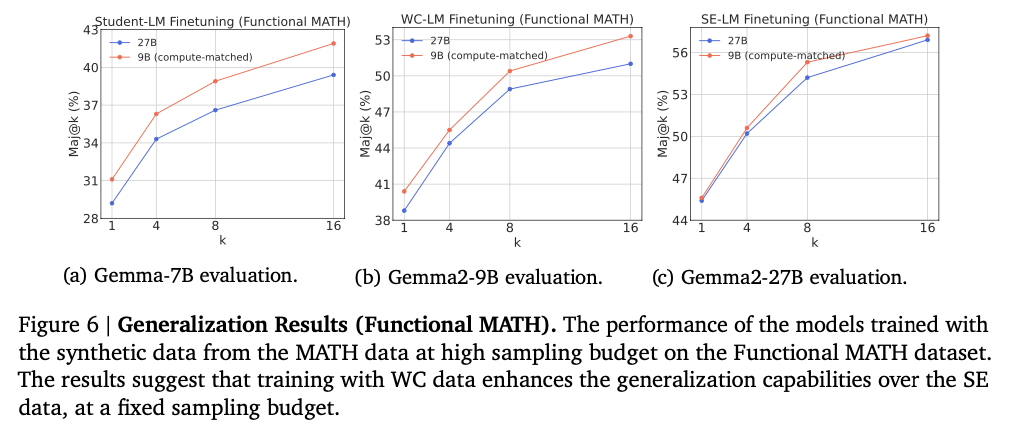
Important enhancements in LLM efficiency had been noticed throughout varied benchmarks. Effective-tuning fashions on information generated by WC fashions constantly yielded higher outcomes than these skilled on information from SE fashions. For instance, utilizing WC-generated information led to a 6% enchancment in accuracy throughout information distillation and a 5.8% enchancment within the weak-to-strong enchancment setup on the MATH dataset. These enhancements had been additionally seen throughout different datasets and coaching paradigms, indicating that WC fashions are efficient in producing various and complete coaching information. Regardless of the upper false constructive charge, the broader vary of appropriate options and elevated downside protection provided by WC fashions resulted in superior efficiency for the fine-tuned fashions. This discovering means that using WC fashions below a set computing price range can result in extra environment friendly coaching, difficult the standard desire for SE fashions.

Utilizing WC fashions for artificial information era proves to be extra compute-efficient than counting on SE fashions. By producing extra various and complete coaching information inside a set compute price range, WC fashions allow the coaching of stronger LLM reasoners. These findings problem the standard knowledge in AI analysis, demonstrating that smaller, weaker fashions, when used optimally, can outperform stronger fashions in sure contexts. This method has vital implications for the way forward for AI analysis, suggesting new pathways for coaching LLMs extra effectively because the efficiency hole between small and huge fashions continues to slim.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Here’s a extremely really useful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]