[ad_1]
Massive Language Fashions (LLMs) have turn into more and more distinguished in pure language processing as a result of they will carry out a variety of duties with excessive accuracy. These fashions require fine-tuning to adapt to particular duties, which usually includes adjusting many parameters, thereby consuming substantial computational assets and reminiscence.
The fine-tuning technique of LLMs presents a big problem because it turns into extremely resource-intensive, significantly when coping with advanced, knowledge-intensive duties. The necessity to replace many parameters throughout fine-tuning can exceed the capability of ordinary computational setups.
Present work contains strategies like Parameter Environment friendly Fantastic-Tuning (PEFT), corresponding to LoRA and Parallel Adapter, which regulate a small fraction of mannequin parameters to cut back reminiscence utilization. Different approaches contain adapter-based tuning, immediate, sparse, and reparametrization-based tuning. Strategies like Swap Transformers and StableMoE make the most of a Combination of Specialists for environment friendly computation. Moreover, fashions like QLoRA and strategies like CPU-offload and LST give attention to reminiscence effectivity, whereas SparseGPT explores sparsity to reinforce efficiency.
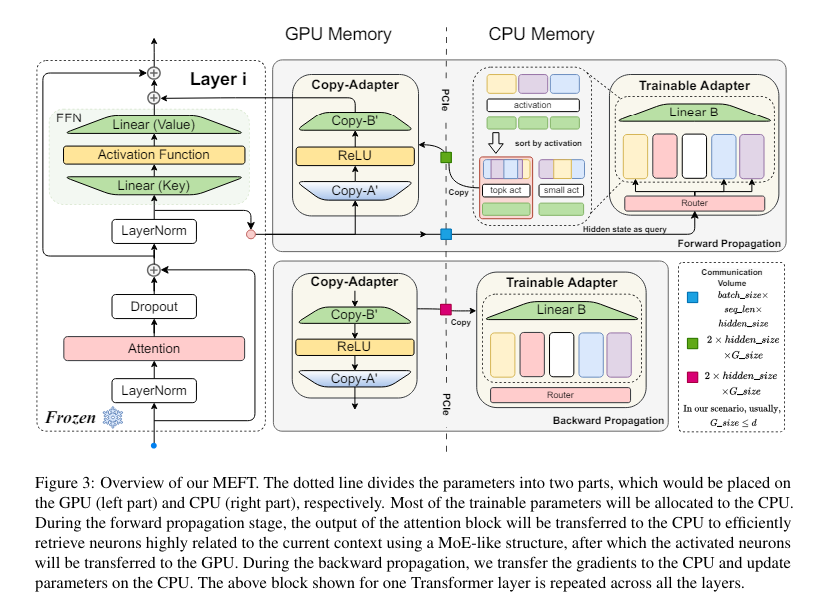
Researchers from Shandong College, Carnegie Mellon College, Academy of Arithmetic and Methods Science, and Leiden College have launched MEFT, a novel fine-tuning technique designed to be memory-efficient. This technique leverages the inherent activation sparsity within the Feed-Ahead Networks (FFNs) of LLMs and the bigger capability of CPU reminiscence in comparison with GPU reminiscence. MEFT shops and updates bigger adapter parameters on the CPU, utilizing a Combination of Specialists (MoE)-like structure to optimize computations and scale back GPU-CPU communication.
MEFT dynamically masses parameters from CPU reminiscence to GPU for coaching, activating solely a subset of related neurons to the enter. This selective activation minimizes GPU reminiscence utilization and computational overhead. The tactic includes sparse activation, the place solely extremely related neurons based mostly on enter similarity are activated, and a Key-Specialists mechanism that makes use of a routing mechanism to activate a subset of the community, decreasing computational complexity and reminiscence switch between CPU and GPU. Particularly, throughout the ahead computation, the tactic retrieves the highest Ok keys with the very best similarity to the enter, forming a smaller matrix of related parameters, which is then moved to the GPU for additional processing. This method ensures that the majority parameters stay on the CPU, decreasing the communication quantity and reminiscence utilization on the GPU.

MEFT was examined on two fashions, LLaMA-7B and Mistral-7B, and 4 datasets: Pure Questions (NQ), SQuAD, ToolBench, and GSM8K. The researchers discovered that MEFT considerably reduces GPU reminiscence utilization by 50%, from 48GB to 24GB, whereas reaching efficiency corresponding to full fine-tuning strategies. As an illustration, MEFT achieved 0.413 and 0.427 precise match (EM) scores on the NQ dataset utilizing LLaMA-7B and Mistral-7B, respectively. These scores are notably increased than baseline strategies like Parallel Adapter and LoRA. The researchers from Shandong College, Carnegie Mellon College, the Academy of Arithmetic and Methods Science, and Leiden College discovered that MEFT’s effectivity in useful resource utilization permits it to suit the next proportion of trainable parameters inside the restricted 24GB GPU capability.
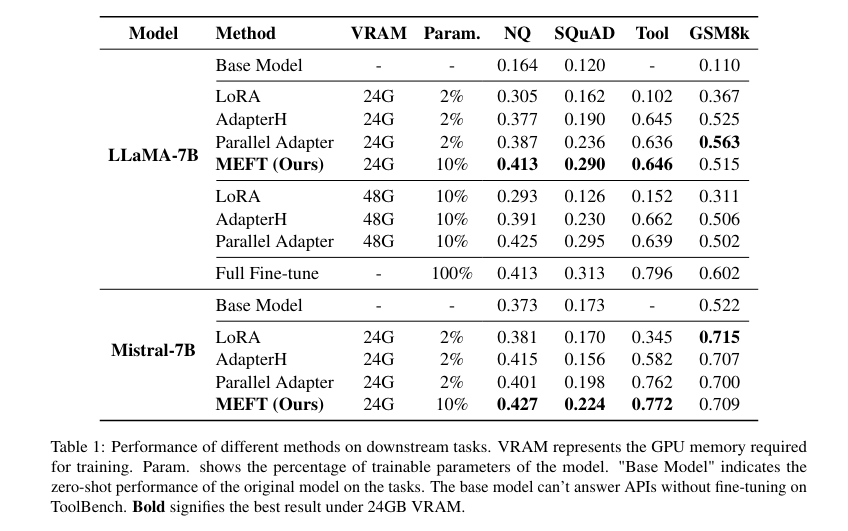
MEFT’s efficiency on the SQuAD dataset additional demonstrated its effectiveness, reaching EM scores of 0.377 and 0.415 with LLaMA-7B and Mistral-7B, respectively. Moreover, on the ToolBench dataset, MEFT, with its adaptability, outperformed different strategies with an intersection-over-union (IoU) rating of 0.645 utilizing LLaMA-7B. For GSM8K, a dataset with a powerful logical part, MEFT achieved a big rating of 0.525, indicating that sparse coaching doesn’t compromise efficiency on logical duties. The researchers concluded that MEFT’s capacity to cut back reminiscence utilization with out sacrificing efficiency makes it a helpful device for fine-tuning LLMs underneath resource-constrained situations.
In conclusion, MEFT gives a viable answer to the resource-intensive problem of fine-tuning giant language fashions. Leveraging sparsity and MoE reduces reminiscence utilization and computational calls for, making it an efficient technique for fine-tuning LLMs with restricted assets. This innovation addresses the vital scalability downside in mannequin fine-tuning, offering a extra environment friendly and scalable method. The researchers’ findings counsel that MEFT can obtain outcomes corresponding to full-model fine-tuning, making it a big development in pure language processing.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 44k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]