[ad_1]
Textual content-to-video technology is quickly advancing, pushed by important developments in transformer architectures and diffusion fashions. These applied sciences have unlocked the potential to rework textual content prompts into coherent, dynamic video content material, creating new potentialities in multimedia technology. Precisely translating textual descriptions into visible sequences requires subtle algorithms to handle the intricate stability between textual content and video modalities. This space focuses on bettering the semantic alignment between textual content and generated video, guaranteeing that the outputs are visually interesting and true to the enter prompts.
A major problem on this discipline is reaching temporal consistency in long-duration movies. This entails creating video sequences that keep coherence over prolonged intervals, particularly when depicting complicated, large-scale motions. Video knowledge inherently carries huge spatial and temporal info, making environment friendly modeling a big hurdle. One other crucial challenge is guaranteeing that the generated movies precisely align with the textual prompts, a activity that turns into more and more troublesome because the size and complexity of the video enhance. Efficient options to those challenges are important for advancing the sphere and creating sensible purposes for text-to-video technology.
Traditionally, strategies to deal with these challenges have used variational autoencoders (VAEs) for video compression and transformers for enhancing text-video alignment. Whereas these strategies have improved video technology high quality, they usually want to take care of temporal coherence over longer sequences and align video content material with textual content descriptions when dealing with intricate motions or massive datasets. The limitation of those fashions in producing high-quality, long-duration movies has pushed the seek for extra superior options.
Zhipu AI and Tsinghua College researchers have launched CogVideoX, a novel method that leverages cutting-edge strategies to boost text-to-video technology. CogVideoX employs a 3D causal VAE, compressing video knowledge alongside spatial and temporal dimensions, considerably decreasing the computational load whereas sustaining video high quality. The mannequin additionally integrates an skilled transformer with adaptive LayerNorm, which improves the alignment between textual content and video, facilitating a extra seamless integration of those two modalities. This superior structure allows the technology of high-quality, semantically correct movies that may lengthen over longer durations than beforehand potential.
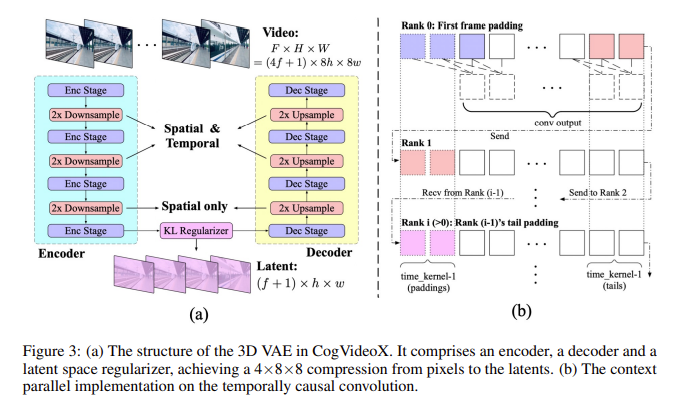
CogVideoX incorporates a number of revolutionary strategies that set it aside from earlier fashions. The 3D causal VAE permits for a 4×8×8 compression from pixels to latents, a considerable discount that preserves the continuity and high quality of the video. The skilled transformer makes use of a 3D full consideration mechanism, comprehensively modeling video knowledge to make sure that large-scale motions are precisely represented. The mannequin features a subtle video captioning pipeline, which generates new textual descriptions for video knowledge, enhancing the semantic alignment of the movies with the enter textual content. This pipeline contains video filtering to take away low-quality clips and a dense video captioning technique that improves the mannequin’s understanding of video content material.
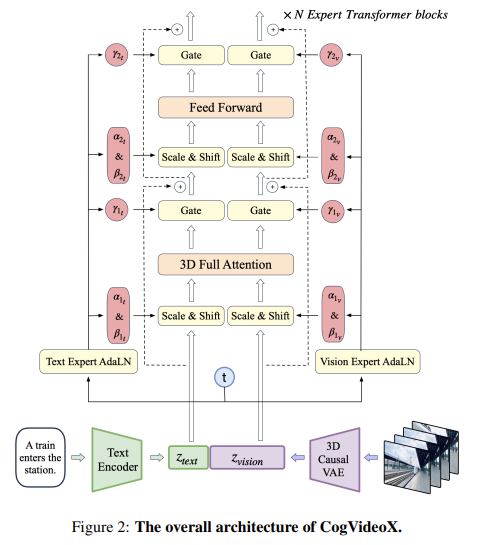
CogVideoX is out there in two variants: CogVideoX-2B and CogVideoX-5B, every providing totally different capabilities. The 2B variant is designed for eventualities the place computational assets are restricted, providing a balanced method to text-to-video technology with a smaller mannequin dimension. Then again, the 5B variant represents the high-end providing, that includes a bigger mannequin that delivers superior efficiency in additional complicated eventualities. The 5B variant, particularly, excels in dealing with intricate video dynamics and producing movies with the next degree of element, making it appropriate for extra demanding purposes. Each variants are publicly accessible and symbolize important developments within the discipline.
The efficiency of CogVideoX has been rigorously evaluated, with outcomes displaying that it outperforms present fashions throughout numerous metrics. Particularly, it demonstrates superior efficiency in human motion recognition, scene illustration, and dynamic high quality, scoring 95.2, 54.65, and a pair of.74, respectively, in these classes. The mannequin’s capacity to generate coherent and detailed movies from textual content prompts marks a big development within the discipline. The radar chart comparability clearly illustrates CogVideoX’s dominance, significantly in its capacity to deal with complicated dynamic scenes, the place it outshines earlier fashions.

In conclusion, CogVideoX addresses the important thing challenges in text-to-video technology by introducing a sturdy framework that mixes environment friendly video knowledge modeling with enhanced text-video alignment. Utilizing a 3D causal VAE and skilled transformers, together with progressive coaching strategies like mixed-duration and backbone progressive coaching, permits CogVideoX to supply long-duration, semantically correct movies with important movement. Introducing two variants, CogVideoX-2B and CogVideoX-5B, affords flexibility for various use circumstances, guaranteeing that the mannequin may be utilized throughout numerous eventualities.
Try the Paper, Mannequin Card, GitHub, and Demo. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Here’s a extremely beneficial webinar from our sponsor: ‘Constructing Performant AI Functions with NVIDIA NIMs and Haystack’
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

[ad_2]