[ad_1]
Doc retrieval, a subfield of data retrieval, focuses on matching consumer queries with related paperwork inside a corpus. It’s essential in varied industrial functions, equivalent to search engines like google and data extraction techniques. Efficient doc retrieval techniques should deal with textual content material and visible parts like photos, tables, and figures to convey data to customers effectively.
Trendy doc retrieval techniques usually want assist in effectively exploiting visible cues, which limits their efficiency. These techniques primarily concentrate on text-based matching, which hampers their capacity to deal with visually wealthy paperwork successfully. The important thing challenge is integrating visible data with textual content to boost retrieval accuracy and effectivity. That is significantly difficult as a result of visible parts usually convey essential data that textual content alone can not seize.
Conventional strategies equivalent to TF-IDF and BM25 depend on phrase frequency and statistical measures for textual content retrieval. Neural embedding fashions have improved retrieval efficiency by encoding paperwork into dense vector areas. Nonetheless, these strategies usually have to pay extra consideration to visible parts, resulting in suboptimal outcomes for paperwork wealthy in visible content material. Latest developments in late interplay mechanisms and vision-language fashions have proven potential, however their effectiveness in sensible functions nonetheless must be improved.
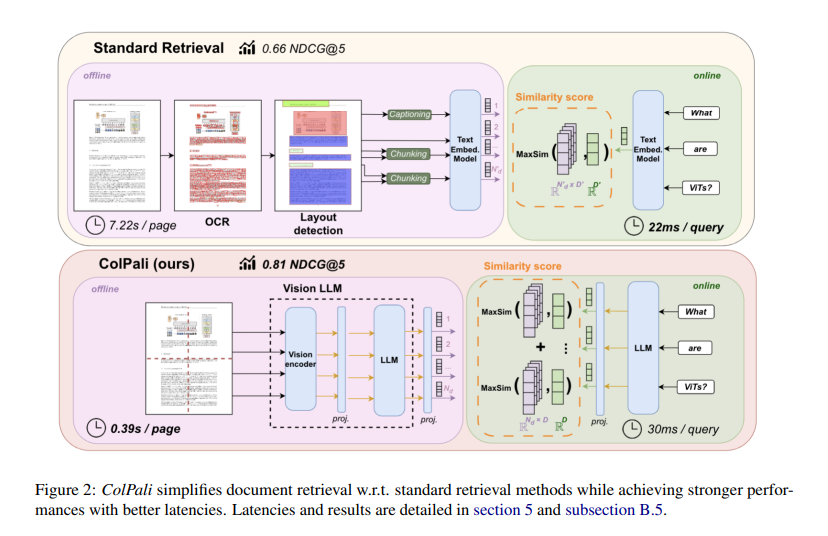
Researchers from Illuin Expertise, Equall.ai, CentraleSupélec, Paris-Saclay, and ETH Zürich have launched a novel mannequin structure known as ColPali. This mannequin leverages current Imaginative and prescient Language Fashions (VLMs) to create high-quality contextualized embeddings from doc photos. ColPali goals to outperform current doc retrieval techniques by successfully integrating visible and textual options. The mannequin processes photos of doc pages to generate embeddings, enabling quick and correct question matching. This method addresses the inherent limitations of conventional text-centric retrieval strategies.
ColPali makes use of the ViDoRe benchmark, together with datasets equivalent to DocVQA, InfoVQA, and TabFQuAD. The mannequin makes use of a late interplay matching mechanism, combining visible understanding with environment friendly retrieval. ColPali processes photos to generate embeddings, integrating visible and textual options. The framework contains creating embeddings from doc pages and performing quick question matching, guaranteeing environment friendly integration of visible cues into the retrieval course of. This methodology permits for detailed matching between question and doc photos, enhancing retrieval accuracy.
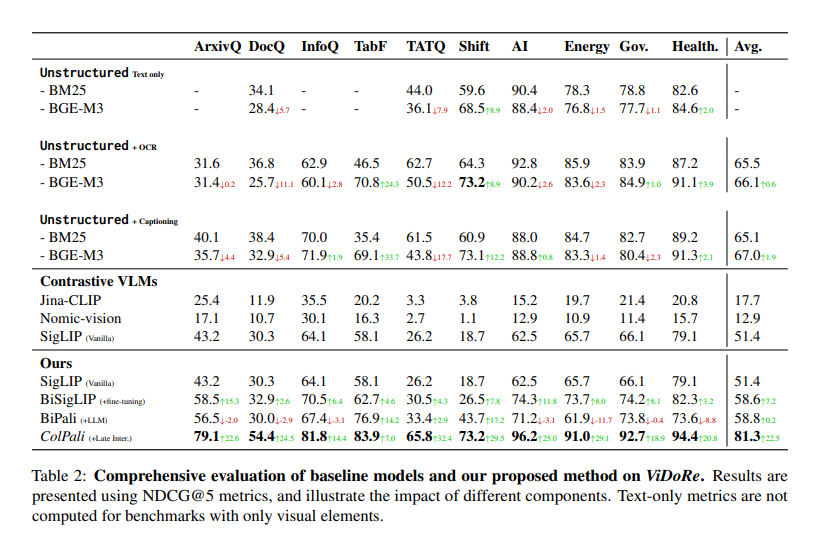
The efficiency of ColPali considerably surpasses current retrieval pipelines. The researchers carried out intensive experiments to benchmark ColPali in opposition to present techniques, highlighting its superior efficiency. ColPali demonstrated a retrieval accuracy of 90.4% on the DocVQA dataset, considerably outperforming different fashions. Moreover, it achieved excessive scores on varied different benchmarks, together with 78.8% on TabFQuAD and 82.6% on InfoVQA. These outcomes underscore ColPali‘s functionality to deal with visually complicated paperwork and numerous languages successfully. The mannequin additionally exhibited low latency, making it appropriate for real-time functions.
In conclusion, the researchers successfully addressed the essential drawback of integrating visible and textual options in doc retrieval. ColPali affords a sturdy resolution by leveraging superior vision-language fashions, considerably enhancing retrieval accuracy and effectivity. This improvement marks a major step ahead in doc retrieval, offering a strong device for dealing with visually wealthy paperwork. The success of ColPali underscores the significance of incorporating visible parts into retrieval techniques, paving the best way for future developments on this area.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]