[ad_1]
Within the ever-evolving panorama of synthetic intelligence (AI), the problem of making techniques that may successfully collaborate in dynamic environments is a major one. Multi-agent reinforcement studying (MARL) has been a key focus, aiming to show brokers to work together and adapt in such settings. Nevertheless, these strategies typically grapple with complexity and flexibility points, significantly when confronted with new conditions or different brokers. In response to those challenges, this paper from Stanford introduces a novel approach-the ‘Hypothetical Minds’ mannequin. This progressive mannequin leverages giant language fashions (LLMs) to reinforce efficiency in multi-agent environments by simulating how people perceive and predict others’ behaviors.
Conventional MARL strategies typically discover it laborious to cope with ever-changing environments as a result of the actions of 1 agent can unpredictably have an effect on others. This instability makes studying and adaptation difficult. Current options, like utilizing LLMs to information brokers, have proven some promise in understanding targets and planning however nonetheless want the nuanced capacity to work together successfully with a number of brokers.
The Hypothetical Minds mannequin provides a promising answer to those points. It integrates a Concept of Thoughts (ToM) module into an LLM-based framework. This ToM module empowers the agent to create and replace hypotheses about different brokers’ methods, targets, and behaviors utilizing pure language. By frequently refining these hypotheses primarily based on new observations, the mannequin adapts its methods in actual time. This real-time adaptability is a key characteristic that results in improved efficiency in cooperative, aggressive, and mixed-motive eventualities, offering reassurance concerning the mannequin’s practicality and effectiveness.
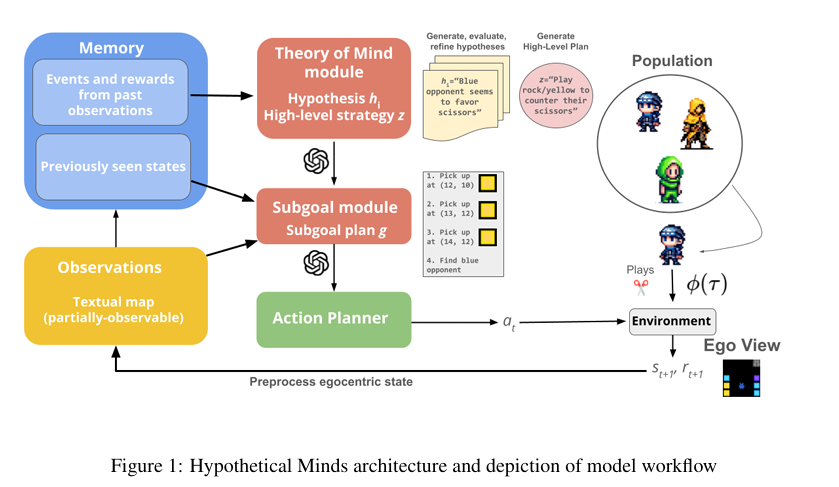
The Hypothetical Minds mannequin is structured round a number of key elements, together with notion, reminiscence, and hierarchical planning modules. Central to its operate is the ToM module, which maintains a set of pure language hypotheses about different brokers. The LLM generates these hypotheses primarily based on the agent’s reminiscence of previous observations and the top-valued beforehand generated hypotheses. This course of permits the mannequin to refine its understanding of different brokers’ methods iteratively.
The method works as follows: the agent observes the actions of different brokers and types preliminary hypotheses about their methods. These hypotheses are evaluated primarily based on how properly they predict future behaviors. A scoring system identifies probably the most correct hypotheses, that are strengthened and refined over time. This ensures the mannequin constantly adapts and improves its understanding of different brokers.
Excessive-level plans are then conditioned on these refined hypotheses. The mannequin’s hierarchical planning method breaks down these plans into smaller, actionable subgoals, guiding the agent’s general technique. This construction permits the Hypothetical Minds mannequin to navigate complicated environments extra successfully than conventional MARL strategies.
To judge the effectiveness of Hypothetical Minds, researchers used the Melting Pot MARL benchmark, a complete suite of assessments designed to evaluate agent efficiency in numerous interactive eventualities. These ranged from easy coordination duties to complicated strategic video games requiring cooperation, competitors, and adaptation. Hypothetical Minds outperformed conventional MARL strategies and different LLM-based brokers in adaptability, generalization, and strategic depth. In aggressive eventualities, the mannequin dynamically up to date its hypotheses about opponents’ methods, predicting their strikes a number of steps forward, permitting it to outmaneuver opponents with superior strategic foresight.
The mannequin additionally excelled in generalizing to new brokers and environments, a problem for conventional MARL approaches. When encountering unfamiliar brokers, Hypothetical Minds shortly fashioned correct hypotheses and adjusted their habits with out in depth retraining. The strong Concept of Thoughts module enabled hierarchical planning, permitting the mannequin to successfully anticipate companions’ wants and actions.
Hypothetical Minds represents a serious step ahead in multi-agent reinforcement studying. By integrating the strengths of enormous language fashions with a classy Concept of Thoughts module, the researchers have developed a system that excels in various environments and dynamically adapts to new challenges. This method opens up thrilling prospects for future AI functions in complicated, interactive settings.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech on the Indian Institute of Know-how (IIT), Bhubaneswar. An AI fanatic, she enjoys staying up to date on the newest developments. Shreya is especially within the real-life functions of cutting-edge expertise, particularly within the subject of knowledge science.

[ad_2]