[ad_1]
We lately launched DBRX: an open, state-of-the-art, general-purpose LLM. DBRX was skilled, fine-tuned, and evaluated utilizing Mosaic AI Coaching, scaling coaching to 3072 NVIDIA H100s and processing greater than 12 trillion tokens within the course of.
Coaching LLMs, and particularly MoE fashions reminiscent of DBRX, is tough. It requires overcoming many infrastructure, efficiency, and scientific challenges. Mosaic AI Coaching was purposely constructed to handle these challenges and was battle-tested by the coaching of DBRX, the MPT sequence of fashions, and plenty of different LLMs reminiscent of Ola’s Krutrim, AI2’s OLMo, Dynamo AI’s Dynamo 8B, Refuel’s LLM-2, and others.
Mosaic AI Coaching is on the market in the present day for Databricks prospects to construct customized fashions on their very own enterprise information which can be tailor-made to a particular enterprise context, language and area, and might effectively energy key enterprise use instances.
These customized fashions are particularly helpful when utilized to explicit domains (e.g., authorized, finance, and so forth.) and when skilled to deal with low-resource languages. We have seen our prospects both pretrain customized fashions or extensively proceed coaching on open supply fashions to energy their distinctive enterprise use instances, and we’re wanting ahead to serving to many extra prospects prepare and personal their very own LLMs.
This weblog put up particulars Mosaic AI Coaching’s core capabilities and the way they had been important to the profitable coaching of DBRX. To get began constructing your personal DBRX-grade customized LLM that leverages your enterprise information, take a look at the Mosaic AI Coaching product web page or contact us in the present day.
“Mosaic AI Coaching infrastructure has been important in our coaching of OLMo and different actually open giant language fashions.” – Dirk Groenveld, Principal Software program Engineer, Allen Institute for Synthetic Intelligence.
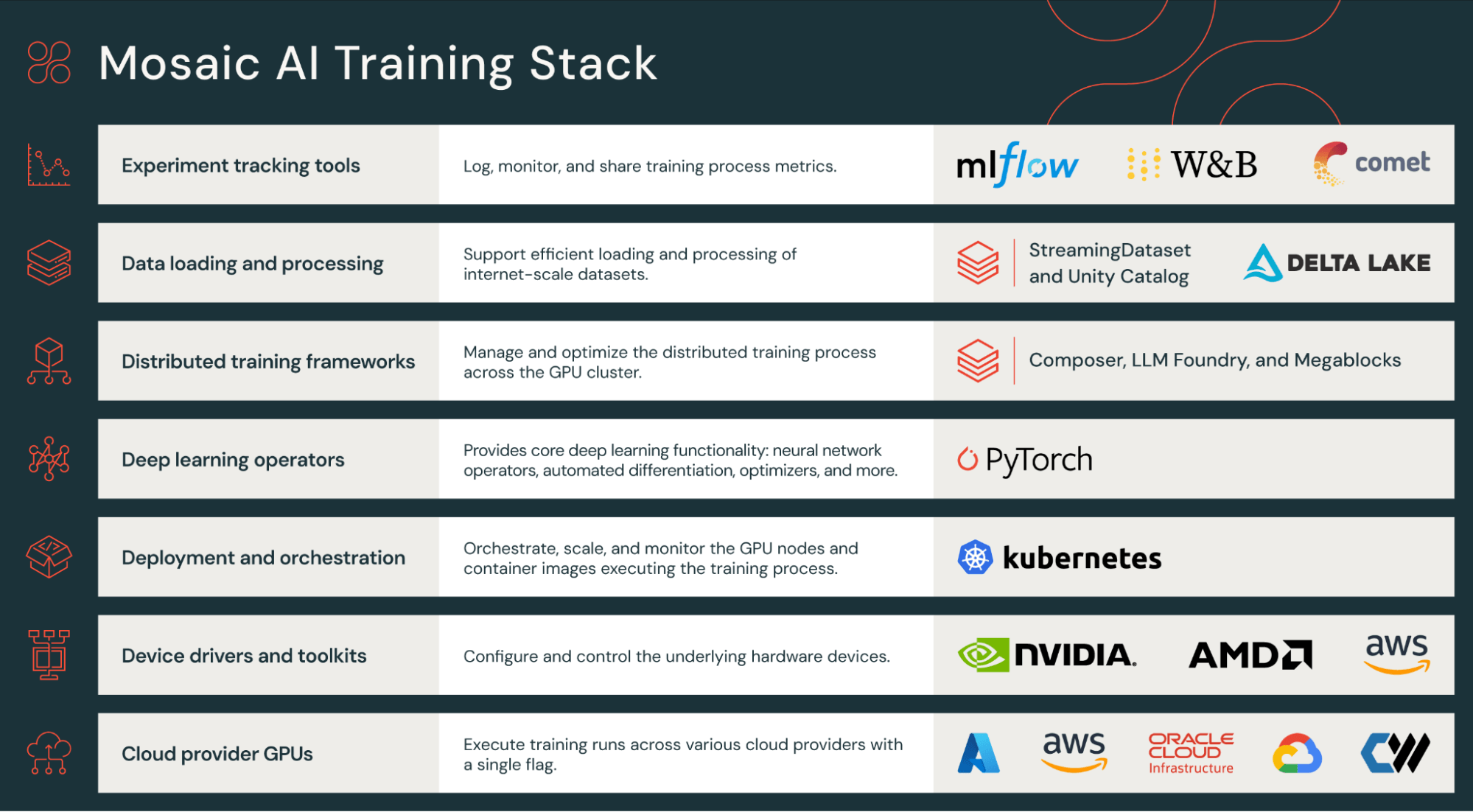
Mosaic AI Coaching stack
Coaching LLMs and different giant AI fashions requires the combination of quite a few elements, from {hardware} gadget drivers to job orchestration and all the best way as much as the neural community coaching loop. This course of is advanced and necessitates a variety of experience. Even a easy mistake, reminiscent of a misconfigured community driver, can result in a 5x decelerate in coaching pace!
To simplify this complexity and to ship an expertise that “simply works”, Mosaic AI Coaching gives an optimized coaching stack that handles all points of large-scale distributed coaching. The stack helps a number of GPU cloud suppliers (AWS, Azure, OCI, Coreweave, to call just a few), is configured with the most recent GPU drivers together with NVIDIA CUDA and AMD ROCm, and contains core neural community and coaching libraries (PyTorch, MegaBlocks, Composer, Streaming). Lastly, battle-tested scripts for coaching, fine-tuning, and evaluating LLMs can be found in LLMFoundry, enabling prospects to start out coaching their very own LLMs instantly.
“At Refuel, we acknowledge the worth of purpose-built, customized LLMs for particular use instances. Our newly launched mannequin, RefuelLLM-2, was skilled on the Mosaic AI Coaching infrastructure and gave us the flexibility to coordinate quite a few elements, from unstructured information to {hardware} gadget drivers to coaching libraries and job orchestration, in a single easy-to-use useful resource.” – Nihit Desai, Co-Founder & CTO, Refuel
Distributed coaching
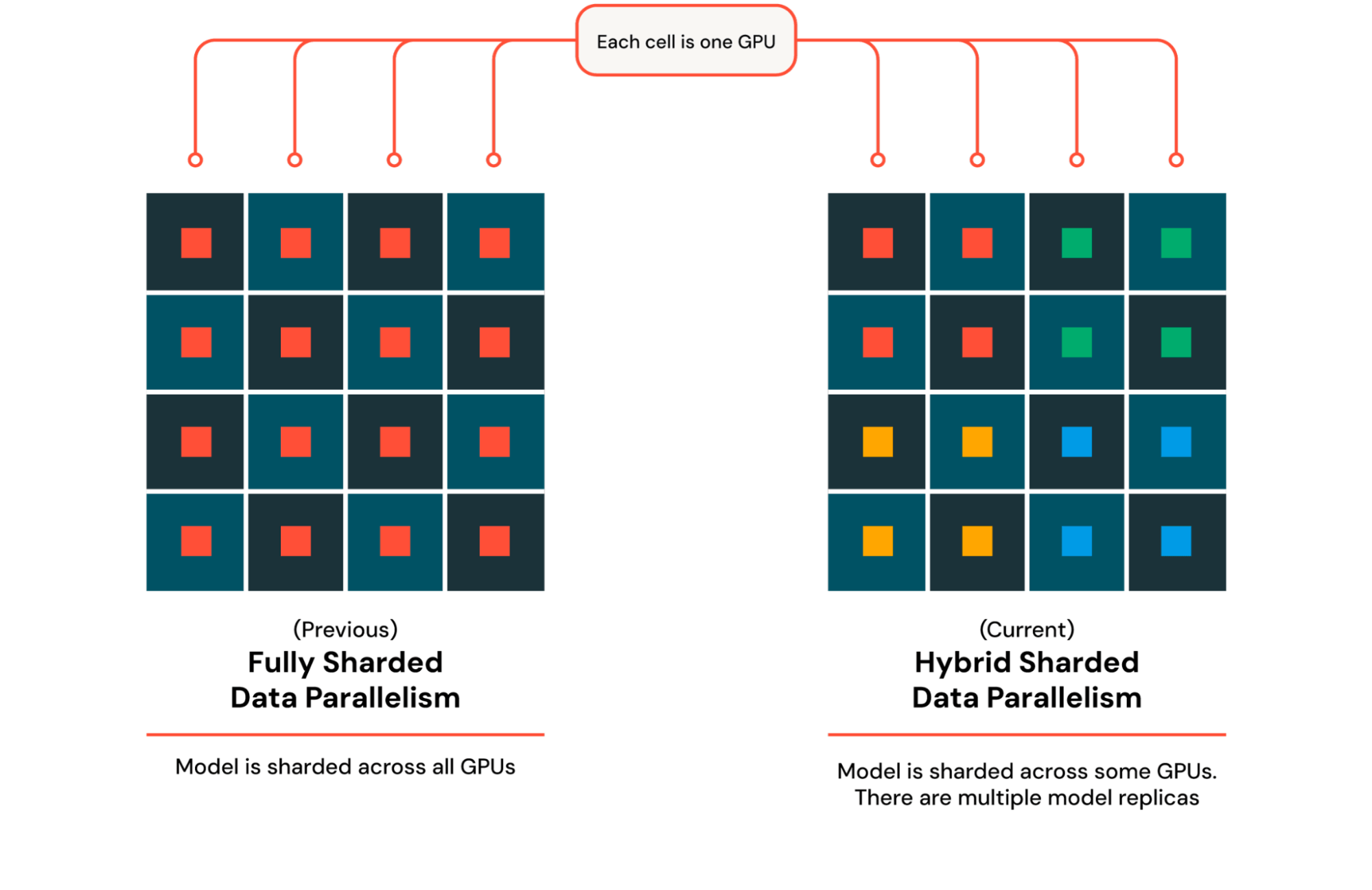
With a purpose to prepare fashions on 1000’s of GPUs, Mosaic AI Coaching leverages DTensor, a easy framework in PyTorch to explain how tensors are sharded and replicated. When extending mannequin coaching from one GPU to a number of GPUs, we regularly leverage Distributed Knowledge Parallel (DDP) coaching, which depends on replicating the mannequin and optimizer throughout totally different GPUs. When coaching a mannequin that doesn’t match within the reminiscence of a single GPU, as is the case with DBRX, we as an alternative use Absolutely Sharded Knowledge Parallel (FSDP) coaching, the place the mannequin and optimizer are sharded throughout a number of GPUs and gathered for an operation reminiscent of a matrix multiplication. Every operation that entails gathering and sharding throughout a number of GPUs slows down because the variety of machines will increase, so we use Hybrid Sharded Knowledge Parallel (HSDP) coaching, which shards the mannequin and optimizer throughout a set duplicate dimension after which copies this duplicate a number of occasions to replenish your complete cluster (Determine 3). With DTensor, we will assemble a tool mesh that describes how tensors are sharded and replicated and go it into Pytorch’s implementation of FSDP. For MoE fashions reminiscent of DBRX, we enhance coaching parallelism to incorporate knowledgeable parallelism, which locations totally different specialists on totally different GPUs. To spice up efficiency, we leverage MegaBlocks, an environment friendly implementation of knowledgeable parallelism. Moreover, we apply sequence size parallelism to assist lengthy context coaching, enormously enhancing assist for key use instances like Retrieval Augmented Technology (RAG). We combine all these applied sciences into Composer, our open-source coaching library which handles parallelism below the hood, giving customers a easy, clear interface to give attention to their mannequin and information.
Given an environment friendly parallelism setup, we leverage the open supply Streaming library to fetch information on-the-fly throughout coaching. Streaming ensures deterministic shuffling throughout 1000’s of machines with lower than 1 minute of startup overhead and no coaching overhead. After we encounter {hardware} failures, Streaming is ready to deterministically resume precisely the place it left off instantaneously. This determinism is important to making sure reproducible outcomes no matter {hardware} points or restarts. Past information shuffling, trendy LLM coaching usually entails a number of levels of coaching in a course of known as curriculum coaching, the place necessary, larger high quality information is upsampled in the direction of the tip of coaching. With only a few parameter overrides, Streaming natively helps superior options like these, mechanically updating dataset mixtures later into coaching.
Distributed checkpointing
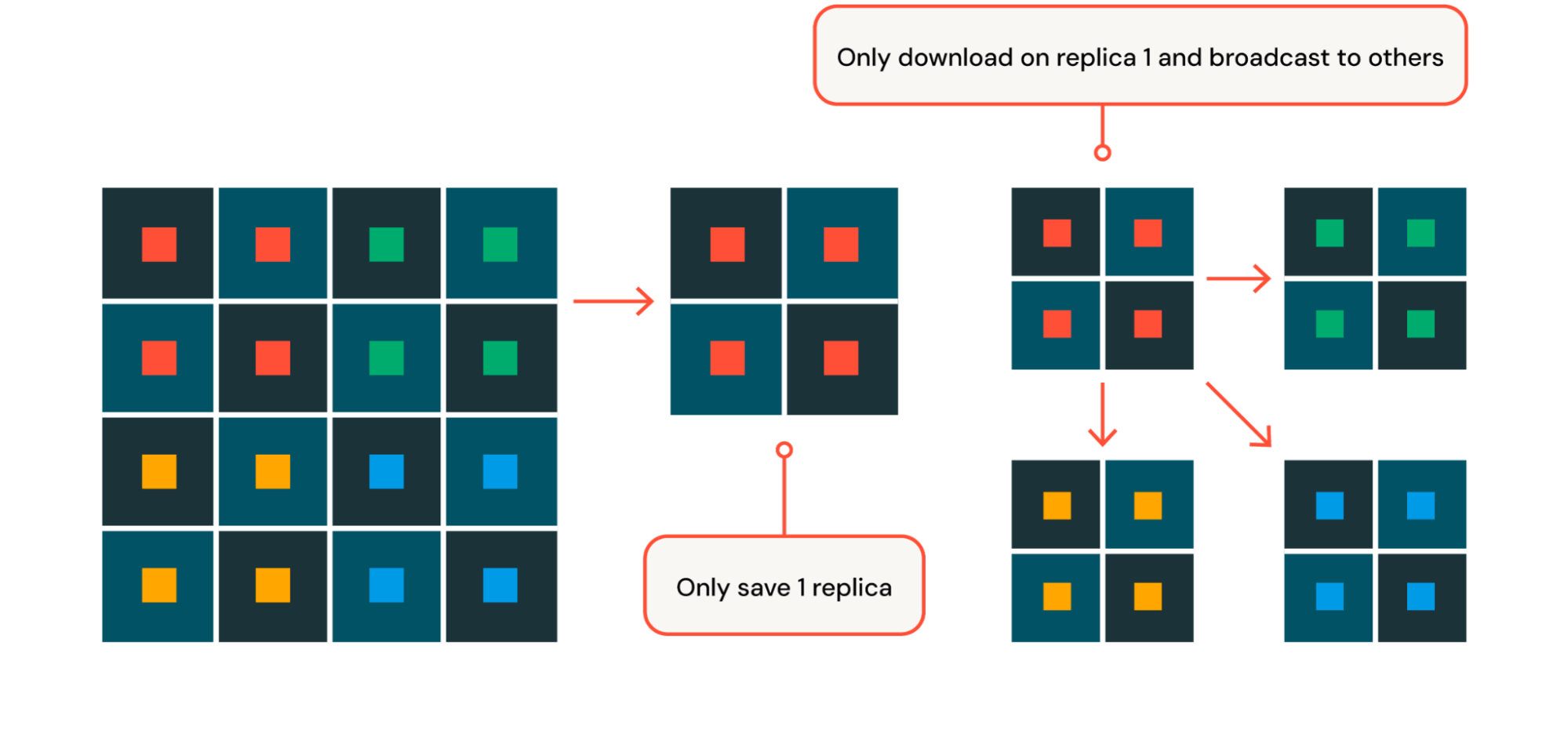
To make sure speedy restoration from {hardware} failures (extra on {hardware} failures later on this weblog put up!), Mosaic AI Coaching implements heavily-optimized checkpoint saving and loading. When pre-training, we leverage a sharded checkpoint the place every GPU saves or hundreds solely its sharded portion of the mannequin parameters and optimizer state. By spreading out the work of saving and loading throughout lots of of machines, we decrease blocking time to below 30 seconds throughout save and cargo, even when coaching fashions with lots of of billions of parameters and checkpoints which can be a number of terabytes in dimension reminiscent of DBRX. With HSDP, we additional optimize this course of by solely saving and loading checkpoint throughout the first duplicate and broadcasting to all different replicas when essential (Determine 4).
Coaching efficiency optimizations
Attaining the absolute best efficiency throughout LLM coaching is important to minimizing each coaching period and value, particularly given the size of LLM coaching, which frequently entails 1000’s of pricy high-end GPUs. For example, DBRX coaching spanned 3072 H100 GPUs throughout a 3-month period. Mosaic AI Coaching aggressively optimizes reminiscence utilization and computation to realize such SOTA coaching effectivity.
The reminiscence utilization of coaching LLM contains the mannequin parameters, optimizer state, gradients, and activations. These restrict the runnable coaching batch dimension, and as fashions scale, can turn out to be a important efficiency bottleneck. Word {that a} bigger batch dimension ends in bigger matrix multiplications that present larger GPU utilization. To deal with mannequin parameters, optimizer state, and gradients, we leverage PyTorch FSDP and HSDP as beforehand described. To deal with activation reminiscence, we use a mix of selective activation checkpointing and compression. Activation checkpointing recomputes as an alternative of saving a few of these intermediate tensors, saving reminiscence at the price of further computation. This extra reminiscence allows a bigger batch dimension in DBRX coaching. To use activation checkpointing effectively, we assist checkpointing the activations in a configurable method, the place we will simply specify mannequin granularity (full block, consideration, and so forth.) and vary (e.g., first-n layers, vary(m, okay) layers). Together with activation checkpointing, we’ve developed customized, low-level kernels to compress activations. As a substitute of storing all activations in 16-bit precision, we compress these activations into customized, lower-precision codecs, considerably lowering activation reminiscence whereas having a minimal impression on mannequin high quality. These reminiscence optimizations scale back the reminiscence footprint by almost 3x for giant fashions like DBRX.
Mosaic AI Coaching additionally optimizes computation, making certain the GPU is operating at maximal FLOPS so long as attainable. We first generate detailed occasion profiles (CPU, CUDA kernels, NCCL, and so forth.) of our fashions utilizing the PyTorch profiler in addition to customized benchmarks. These outcomes closely encourage additional enhancements, enabling us to all the time goal probably the most important bottleneck. For instance, we leverage performant operators from FlashAttention 2, MegaBlocks, and different customized kernels to keep away from CPU and reminiscence bottlenecks for key layers in DBRX. To allow quick, dropless MoEs, we reorder GPU and CPU occasions to make sure CUDA kernels should not blocked by gadget synchronization, additional avoiding CPU bottlenecks. To keep away from communication bottlenecks, we make use of different optimizations that maximizes the flops per GPU. Put collectively, this work allows coaching superior MoE architectures at almost the identical pace as commonplace transformers throughout a big number of scales.
GPU fault tolerance
Coaching LLMs entails orchestrating 1000’s of GPUs throughout lots of of nodes, introducing infrastructure scaling and reliability challenges. Node failures are extraordinarily frequent at this scale. We’ll focus on some key options of Mosaic AI Coaching that enabled our success.
To shortly detect and remediate device-level points, Mosaic AI Coaching ships with a sturdy set of GPU alerts leveraging NVIDIA’s prometheus metric exporter (DCGM Exporter) which detects frequent GPU errors (XID errors) reminiscent of ECC uncorrectable errors and remapping errors, GPU disconnections, and GPU ROM failures. We lengthen the DCGM operator configuration to observe GPU throttling to determine further GPU efficiency points, reminiscent of thermal and energy violations reported from the GPUs.
Mosaic AI Coaching additionally triggers automated cluster sweeps with smaller diagnostic workloads when sure configurable circumstances are met throughout coaching, reminiscent of when Mannequin FLOPs Utilization (MFU) drops under a pre-configured threshold. Upon diagnostic check failure, Mosaic AI Coaching cordons straggling nodes and mechanically resumes the run from the most recent checkpoint utilizing Composer’s autoresume performance and distributed checkpointing.
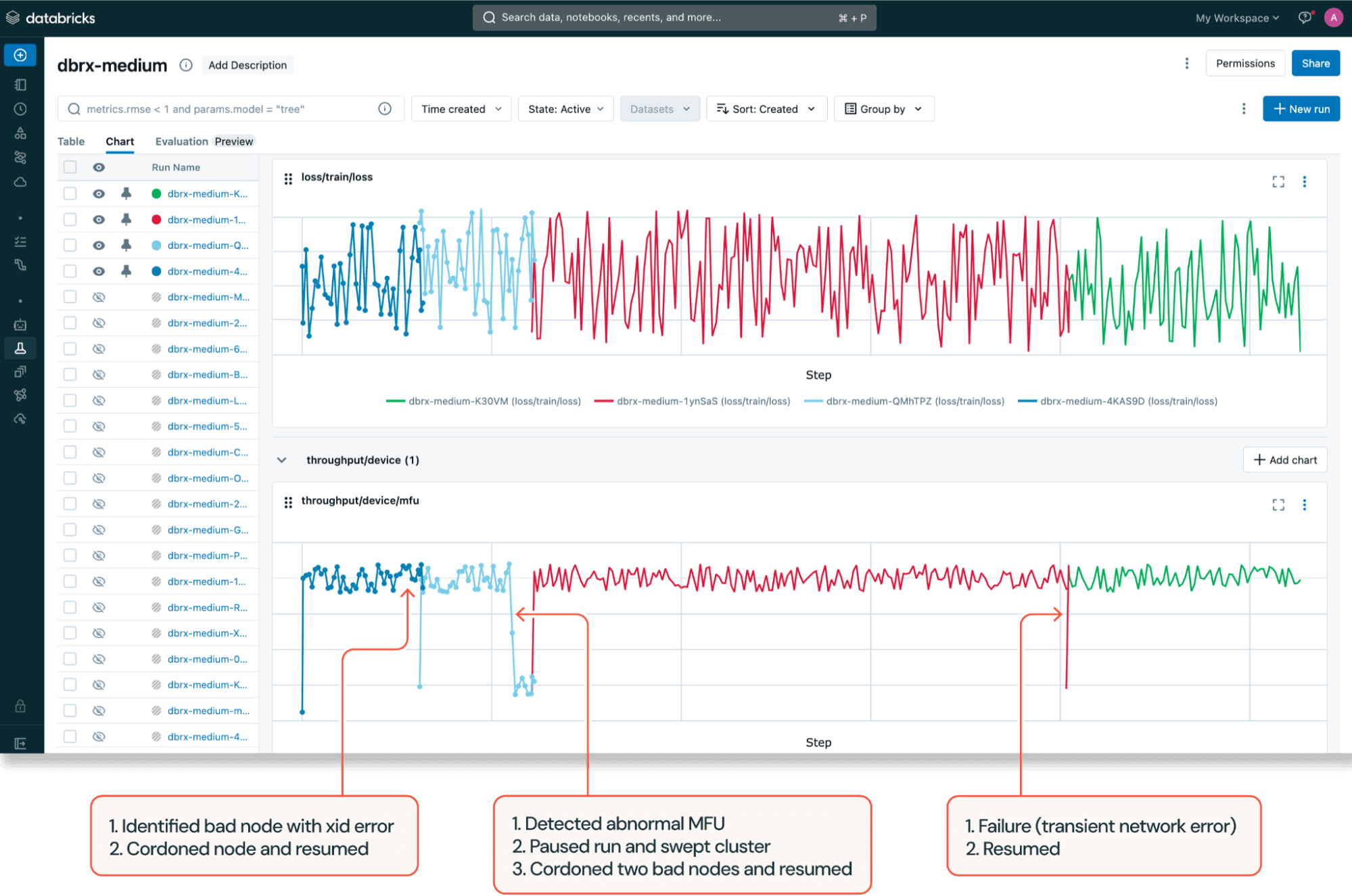
Together, these fault tolerance capabilities had been extraordinarily useful for DBRX coaching. With restricted GPU capability, even a slight drop within the variety of nodes obtainable might have enormously affected scheduling goodput, a time period coined by Google representing the fraction of time that every one the assets required to run the coaching job can be found. Our alerting and remediation system recognized varied GPU errors and recycled unhealthy nodes earlier than the run was scheduled, thereby making certain excessive scheduling goodput.
Community cloth fault tolerance
Mosaic AI Coaching gives the flexibility to pinpoint particular points throughout the GPUDirect Distant Direct Reminiscence Entry (GDRDMA) cloth, reminiscent of change port failures and full change failures.
To gather these metrics, Mosaic AI Coaching periodically schedules a set of quick-running blocking well being checks. These are canary deployments that stress check units of nodes to gather each compute and communication benchmarks. The compute checks embody multi-gpu CUDA stress checks to verify that GPUs run optimally at absolutely utilized workloads. The communication checks embody all-reduce NCCL checks between neighboring nodes utilizing the NVIDIA nccl-test methodology. Mosaic AI Coaching then consumes the metrics from these checks for various NCCL payload sizes and cordons off cluster nodes with any anomalies or failures.
When coaching DBRX, these community cloth checks recognized a number of change points that occurred throughout the three-month coaching interval. This enabled the run to renew on a smaller partition of nodes whereas the cloud supplier serviced the change outage.
Determine 6 exhibits the tough define of how our community cloth checks had been orchestrated:
- Mosaic AI Well being Checking API tracks and awaits goal nodes which can be prepared for checking.
- API spawns distributed coaching processes that run NCCL all scale back checks.
- RPC callbacks to well being checking API with collective communication and compute metrics.
- Well being Checking API cordons nodes with anomalous metrics.
Experiment monitoring
Along with alerts and GPU well being monitoring, Mosaic AI Coaching integrates with MLflow and different experiment trackers to supply real-time monitoring of coaching metrics, coaching progress, system metrics, and analysis outcomes. We used these to observe progress in any respect phases of DBRX coaching, whether or not for our preliminary experiments, well being checks, or last large-scale coaching run (see Determine 5).
To observe DBRX coaching progress and approximate last mannequin high quality, we ran a full sweep of analysis duties for each 1T tokens skilled utilizing the Mosaic Analysis Gauntlet throughout the complete 12 trillion tokens the mannequin was skilled on. By saving intermediate and fine-tuned checkpoints within the MLflow Mannequin Registry, we had been in a position to simply handle a number of variations of the mannequin for analysis and deploy with Databricks Mannequin Serving.
“Databricks Mosaic AI enabled us to coach Dynamo8B, an industry-leading basis mannequin, specializing in enterprise compliance and accountable AI for our prospects. The configured container pictures and out-of-the-box coaching scripts saved us weeks’ price of improvement time, and with Mosaic AI Coaching’s built-in speed-ups and GPU availability on-demand, it took us simply ten days to pretrain our 8-billion parameter multilingual LLM.” – Eric Lin, Head of Utilized AI, Dynamo AI
Begin coaching your personal customized LLM
To get began constructing your personal DBRX-grade customized LLM that leverages your enterprise information, take a look at the Mosaic AI Coaching product web page or contact us for extra info.
[ad_2]