[ad_1]
Ordered sequences, together with textual content, audio, and code, depend on place info for that means. Giant language fashions (LLMs), just like the Transformer structure, lack inherent ordering info and deal with sequences as units. Place Encoding (PE) addresses this by assigning an embedding vector to every place, which is essential for LLMs’ understanding. PE strategies, together with absolute and relative measures, are integral to LLMs, accommodating varied tokenization strategies. Nevertheless, token variability poses challenges for exact place addressing in sequences.
Initially, consideration mechanisms didn’t require PE as they have been used with RNNs. Reminiscence Community launched PE alongside consideration, using learnable embedding vectors for relative positions. PE gained traction with the Transformer structure, the place each absolute and relative PE variants have been explored. Numerous modifications adopted, resembling simplified bias phrases, and CoPE, which contextualizes place measurement. In contrast to RNNs, CoPE permits parallelization in Transformer coaching, enhancing effectivity. Some analysis works favor relative PE in current LLMs, with RoPE providing a modification-free implementation.
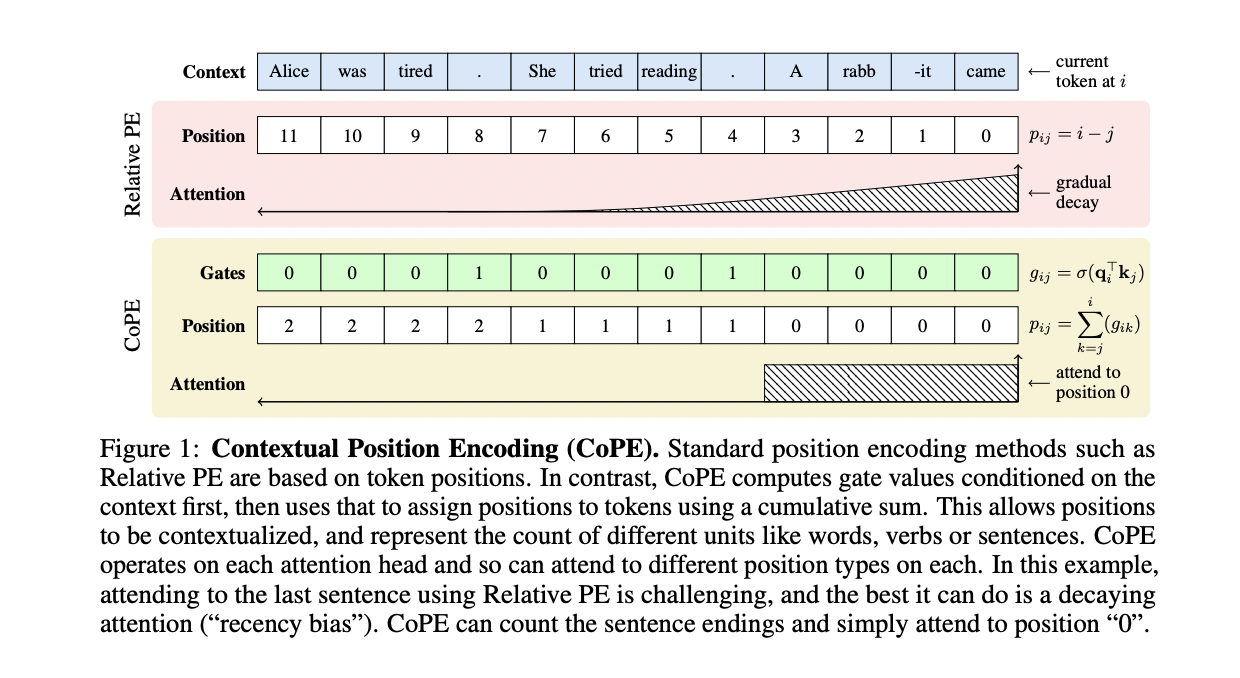
Researchers from Meta current Contextual Place Encoding (CoPE), COPE determines token positions primarily based on their context vectors. By computing gate values for earlier tokens utilizing their key vectors relative to the present token, CoPE establishes fractional positional values, requiring interpolation of assigned embeddings for computation. These embeddings improve the eye operation by incorporating positional info. CoPE excels in toy duties like counting and selective copying, surpassing token-based PE strategies, notably in out-of-domain eventualities. In language modeling duties utilizing Wikipedia textual content and code, CoPE persistently demonstrates superior efficiency, highlighting its real-world applicability.
In CoPE, place measurement is context-dependent, decided by gate values computed for every query-key pair, permitting differentiation by backpropagation. Place values are computed by aggregating gate values between the present and goal tokens. It generalizes relative PE by accommodating varied positional ideas, not simply token counts. In contrast to token positions, CoPE’s values may be fractional, necessitating interpolation between integer embeddings for place embeddings. The effectiveness of CoPE is demonstrated in toy duties and real-world purposes, showcasing its superiority over token-based PE strategies. In state-of-the-art LLMs, customary place encodings exhibit failures, particularly in duties requiring exact counting, indicating the necessity for extra superior position-addressing methods like CoPE.
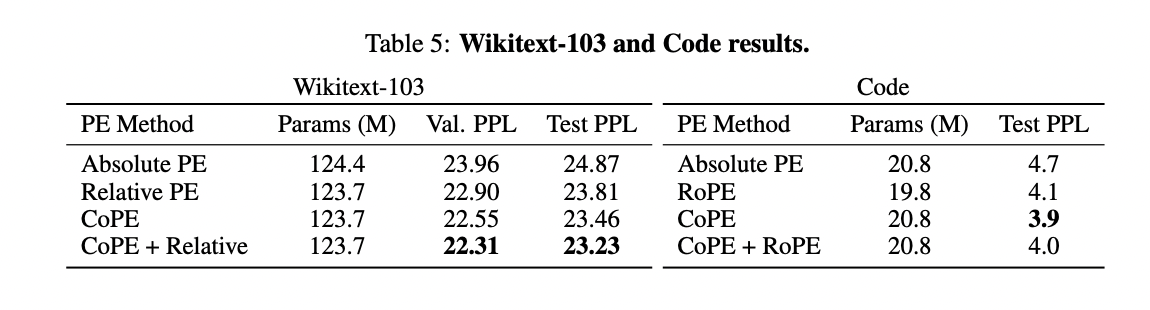
Absolute PE reveals the poorest efficiency among the many in contrast PE strategies. CoPE surpasses relative PE and exhibits additional enhancement when mixed with it, underscoring CoPE’s efficacy on the whole language modeling duties. Evaluating CoPE on code information reveals its superiority over Absolute PE and RoPE, with perplexity enhancements of 17% and 5%, respectively. Whereas combining RoPE and CoPE embeddings yields enhancements over RoPE alone, it doesn’t surpass the efficiency of CoPE alone. This underscores CoPE’s effectiveness in using context for improved modeling, notably in structured information domains like code.
The paper introduces CoPE, a sturdy place encoding technique that measures place contextually, diverging from token-based paradigms. This strategy affords enhanced flexibility in positional addressing, yielding efficiency enhancements throughout varied duties in textual content and code domains. CoPE’s potential extends to domains like video and speech, the place token place is perhaps much less appropriate. Future analysis might discover coaching bigger fashions with CoPE and evaluating their efficiency on downstream duties to evaluate its efficacy and applicability additional.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to affix our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]