[ad_1]
Synthetic intelligence (AI) improvement, significantly in giant language fashions (LLMs), focuses on aligning these fashions with human preferences to reinforce their effectiveness and security. This alignment is crucial in refining AI interactions with customers, making certain that the responses generated are correct and aligned with human expectations and values. Attaining this requires a mix of choice information, which informs the mannequin of fascinating outcomes, and alignment goals that information the coaching course of. These components are essential for enhancing the mannequin’s efficiency and skill to satisfy person expectations.
A big problem in AI mannequin alignment lies within the difficulty of underspecification, the place the connection between choice information and coaching goals just isn’t clearly outlined. This lack of readability can result in suboptimal efficiency, because the mannequin could need assistance to be taught successfully from the offered information. Underspecification happens when choice pairs used to coach the mannequin include irrelevant variations to the specified end result. These spurious variations complicate the educational course of, making it tough for the mannequin to concentrate on the elements that really matter. Present alignment strategies typically must account extra adequately for the connection between the mannequin’s efficiency and the choice information, probably resulting in a degradation within the mannequin’s capabilities.
Present strategies for aligning LLMs, reminiscent of these counting on contrastive studying goals and choice pair datasets, have made vital strides however have to be revised. These strategies sometimes contain producing two outputs from the mannequin and utilizing a decide, one other AI mannequin, or a human to pick the popular output. Nevertheless, this strategy can result in inconsistent choice alerts, as the standards for selecting the popular response may solely generally be clear or constant. This inconsistency within the studying sign can hinder the mannequin’s means to enhance successfully throughout coaching, because the mannequin could solely generally obtain clear steering on adjusting its outputs to align higher with human preferences.
Researchers from Ghent College – imec, Stanford College, and Contextual AI have launched two modern strategies to handle these challenges: Contrastive Studying from AI Revisions (CLAIR) and Anchored Choice Optimization (APO). CLAIR is a novel data-creation technique designed to generate minimally contrasting choice pairs by barely revising a mannequin’s output to create a most popular response. This technique ensures that the distinction between the successful and dropping outputs is minimal however significant, offering a extra exact studying sign for the mannequin. However, APO is a household of alignment goals that supply higher management over the coaching course of. By explicitly accounting for the connection between the mannequin and the choice information, APO ensures that the alignment course of is extra secure and efficient.
The CLAIR technique operates by first producing a dropping output from the goal mannequin, then utilizing a stronger mannequin, reminiscent of GPT-4-turbo, to revise this output right into a successful one. This revision course of is designed to make solely minimal adjustments, making certain that the distinction between the 2 outputs is targeted on probably the most related elements. This strategy differs considerably from conventional strategies, which could depend on a decide to pick the popular output from two independently generated responses. By creating choice pairs with minimal but significant contrasts, CLAIR gives a clearer and simpler studying sign for the mannequin throughout coaching.
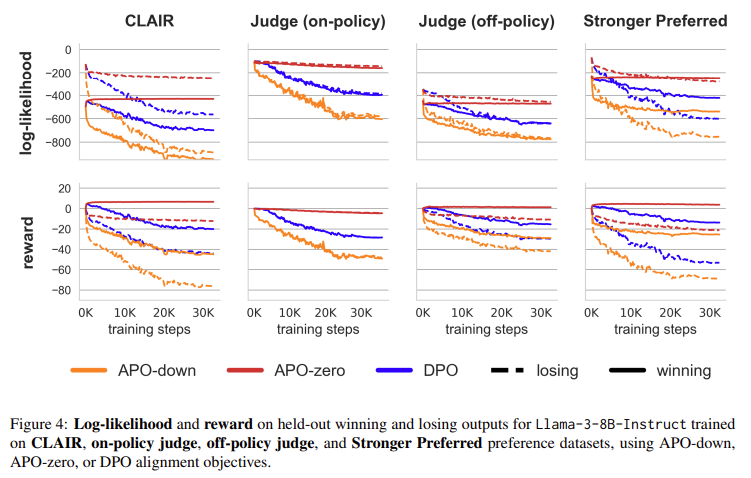
Anchored Choice Optimization (APO) enhances CLAIR by providing fine-grained management over the alignment course of. APO adjusts the probability of successful or dropping outputs primarily based on the mannequin’s efficiency relative to the choice information. For instance, the APO-zero variant will increase the likelihood of successful outputs whereas lowering the probability of dropping ones, which is especially helpful when the mannequin’s outputs are typically much less fascinating than the successful outputs. Conversely, APO-down decreases the probability of successful and dropping outputs, which may be useful when the mannequin’s outputs are already higher than the popular responses. This degree of management permits researchers to tailor the alignment course of extra intently to the precise wants of the mannequin and the information.
The effectiveness of CLAIR and APO was demonstrated by aligning the Llama-3-8B-Instruct mannequin utilizing quite a lot of datasets and alignment goals. The outcomes have been vital: CLAIR, mixed with the APO-zero goal, led to a 7.65% enchancment in efficiency on the MixEval-Onerous benchmark, which measures mannequin accuracy throughout a variety of advanced queries. This enchancment represents a considerable step in the direction of closing the efficiency hole between Llama-3-8B-Instruct and GPT-4-turbo, lowering the distinction by 45%. These outcomes spotlight the significance of minimally contrasting choice pairs and tailor-made alignment goals in enhancing AI mannequin efficiency.

In conclusion, CLAIR and APO provide a simpler strategy to aligning LLMs with human preferences, addressing the challenges of underspecification and offering extra exact management over the coaching course of. Their success in enhancing the efficiency of the Llama-3-8B-Instruct mannequin underscores their potential to reinforce the alignment course of for AI fashions extra broadly.
Try the Paper, Mannequin, and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.
[ad_2]