[ad_1]
Edge computing is now extra related than ever on the planet of synthetic intelligence (AI), machine studying (ML), and cloud computing. On the sting, low latency, trusted networks, and even connectivity aren’t assured. How can one embrace DevSecOps and fashionable cloud-like infrastructure, similar to Kubernetes and infrastructure as code, in an setting the place gadgets have the bandwidth of a fax machine and the intermittent connectivity and excessive latency of a satellite tv for pc connection? On this weblog publish, we current a case examine that sought to import elements of the cloud to an edge server setting utilizing open supply applied sciences.
Open Supply Edge Applied sciences
Just lately members of the SEI DevSecOps Innovation crew have been requested to discover an alternative choice to VMware’s vSphere Hypervisor in an edge compute setting, as latest licensing mannequin modifications have elevated its price. This setting would want to assist each a Kubernetes cluster and conventional digital machine (VM) workloads, all whereas being in a limited-connectivity setting. Moreover, it was essential to automate as a lot of the deployment as potential. This publish explains how, with these necessities in thoughts, the crew got down to create a prototype that will deploy to a single, naked metallic server; set up a hypervisor; and deploy VMs that will host a Kubernetes cluster.
First, we needed to think about hypervisor alternate options, such because the open supply Proxmox, which runs on high of the Debian Linux distribution. Nonetheless, because of future constraints, similar to the flexibility to use a Protection Info Programs Company (DISA) Safety Technical Implementation Guides (STIGs) to the hypervisor, this feature was dropped. Additionally, as of the time of this writing, Proxmox doesn’t have an official Terraform supplier that they preserve to assist cloud configuration. We needed to make use of Terraform to handle any sources that needed to be deployed on the hypervisor and didn’t need to depend on suppliers developed by third events exterior of Proxmox.
We determined to decide on the open supply Harvester hyperconverged infrastructure (HCI) hypervisor, which is maintained by SUSE. Harvester supplies a hypervisor setting that runs on high of SUSE Linux Enterprise (SLE) Micro 5.3 and RKE Authorities (RKE2). RKE2 is a Kubernetes distribution generally present in authorities areas. Harvester ties along with Cloud Native Computing Basis-supported tasks, similar to KubeVirt and Longhorn. Utilizing Kernel Digital Machine (KVM), KubeVirt allows the internet hosting of VMs which are managed via Kubernetes and Longhorn and supply a block storage answer to the RKE2 cluster. This answer stood out for 2 important causes: first, the supply of a DISA STIG for SUSE Linux Enterprise and second, the immutability of OS, which makes the basis filesystem learn solely in post-deployment.
Making a Deployment State of affairs
With the hypervisor chosen, work on our prototype might start. We created a small deployment state of affairs: a single node can be the goal for a deployment that sat in a community with out wider Web entry. A laptop computer with a Linux VM working is connected to the community to behave as our bridge between required artifacts from the Web and the native space community.
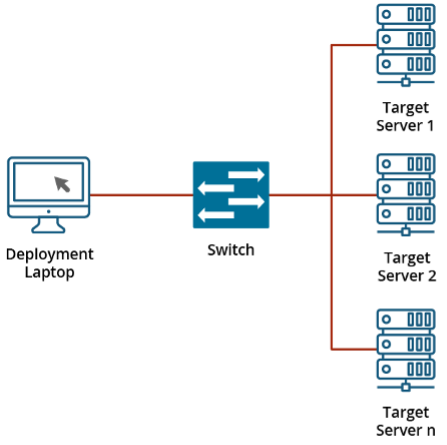{kind=link}
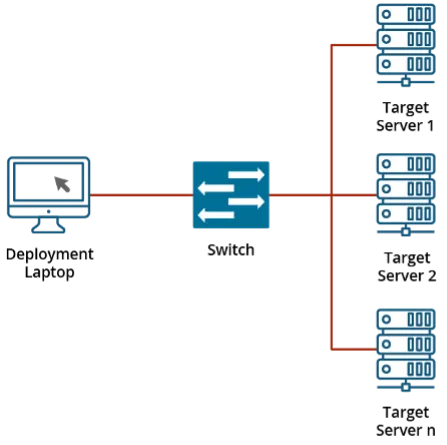
Determine 1: Instance of Community
Harvester helps an automatic set up utilizing the iPXE community boot setting and a configuration file. To realize this, an Ansible playbook was created to configure this VM, with these actions: set up software program packages together with Dynamic Host Configuration Protocol (DHCP) assist and an online server, configure these packages, and obtain artifacts to assist the community set up. The playbook helps variables to outline the community, the variety of nodes so as to add, and extra. This Ansible playbook helps work in the direction of the concept of minimal contact (i.e., minimizing the variety of instructions an operator would want to make use of to deploy the system). The playbook might be tied into an online software or one thing comparable that will current a graphical person interface (GUI) to the tip person, with a objective of eradicating the necessity for command-line instruments. As soon as the playbook runs, a server might be booted within the iPXE setting, and the set up from there’s automated. As soon as accomplished, a Harvester setting is created. From right here, the subsequent step of organising a Kubernetes cluster can start.
A fast apart: Regardless that we deployed Harvester on high of an RKE2 Kubernetes cluster, one ought to keep away from deploying extra sources into that cluster. There’s an experimental characteristic utilizing vCluster to deploy extra sources in a digital cluster alongside the RKE2 cluster. We selected to skip this step since VMs would have to be deployed for sources anyway.
With a Harvester node stood up, VMs might be deployed. Harvester develops a first-party Terraform supplier and handles authentication via a kubeconfig file. The usage of Harvester with KVM allows the creation of VMs from cloud photos and opens potentialities for future work with customization of cloud photos. Our take a look at setting used Ubuntu Linux cloud photos because the working system, enabling us to make use of cloud-init to configure the methods on preliminary start-up. From right here, we had a separate machine because the staging zone to host artifacts for standing up an RKE2 Kubernertes cluster. We ran one other Ansible playbook on this new VM to begin provisioning the cluster and initialize it with Zarf, which we’ll get again to. The Ansible playbook to provision the cluster is essentially primarily based on the open supply playbook printed by Rancher Authorities on their GitHub.
Let’s flip our consideration again to Zarf, a instrument with the tagline “DevSecOps for Airgap.” Initially a Naval Academy post-graduate analysis mission for deploying Kubernetes in a submarine, Zarf is now an open supply instrument hosted on GitHub. By a single, statically linked binary, a person can create and deploy packages. Principally, the objective right here is to collect all of the sources (e.g., helm charts and container photos) required to deploy a Kubernetes artifact right into a tarball whereas there’s entry to the bigger Web. Throughout package deal creation, Zarf can generate a public/non-public key for package deal signing utilizing Cosign.
A software program invoice of supplies (SBOM) can be generated for every picture included within the Zarf package deal. The Zarf instruments assortment can be utilized to transform the SBOMs to the specified format, CycloneDX or SPDX, for additional evaluation, coverage enforcement, and monitoring. From right here, the package deal and Zarf binary might be moved into the sting gadget to deploy the packages. ZarfInitPackageestablishes parts in a Kubernetes cluster, however the package deal might be custom-made, and a default one is offered. The 2 important issues that made Zarf stand out as an answer right here have been the self-contained container registry and the Kubernetes mutating webhook. There’s a chicken-and-egg downside when attempting to face up a container registry in an air-gapped cluster, so Zarf will get round this by splitting the information of the Docker registry picture right into a bunch of configmaps which are merged to get it deployed. Moreover, a typical downside of air-gapped clusters is that the container photos have to be re-tagged to assist the brand new registry. Nonetheless, the deployed mutating webhook will deal with this downside. As a part of the Zarf initialization, a mutating webhook is deployed that can change any container photos from deployments to be routinely up to date to consult with the brand new registry deployed by Zarf. These admission webhooks are a built-in useful resource of Kubernetes.
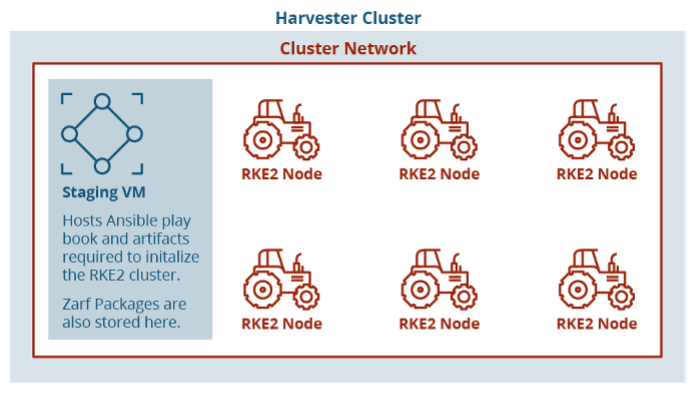{kind=link}
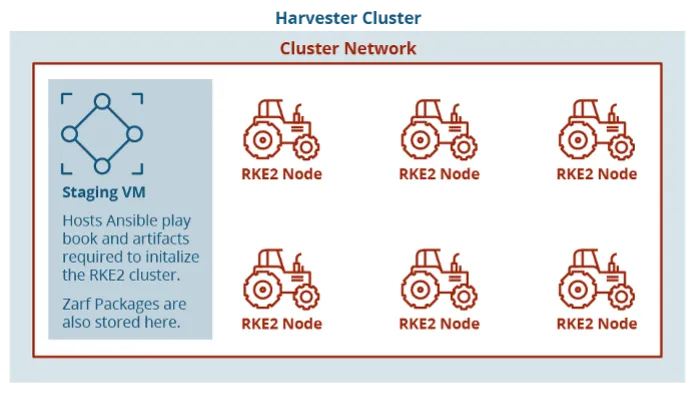
Determine 2: Format of Digital Machines on Harvester Cluster
Automating an Air-Gapped Edge Kubernetes Cluster
We now have an air-gapped Kubernetes cluster that new packages might be deployed to. This solves the unique slender scope of our prototype, however we additionally recognized future work avenues to discover. The primary is utilizing automation to construct auto-updated VMs that may be deployed onto a Harvester cluster with none extra setup past configuration of community/hostname info. Since these are VMs, extra work might be completed in a pipeline to routinely replace packages, set up parts to assist a Kubernetes cluster, and extra. This automation has the potential to take away necessities for the operator since they’ve a turn-key VM that may be deployed. One other answer for coping with Kubernetes in air-gapped environments is Hauler. Whereas not a one-to-one comparability to Zarf, it’s comparable: a small, statically linked binary that may be run with out dependencies and that has the flexibility to place sources similar to helm charts and container photos right into a tarball. Sadly, it wasn’t made obtainable till after our prototype was principally accomplished, however we’ve plans to discover use instances in future deployments.
It is a quickly altering infrastructure setting, and we stay up for persevering with to discover Harvester as its improvement continues and new wants come up for edge computing.
[ad_2]