[ad_1]
Abstract:
- DataBrain, a SaaS firm, was utilizing PostgreSQL by way of Amazon RDS to land and question incoming buyer information.
- Nonetheless, PostgreSQL couldn’t scale, rapidly ingest schemaless information, or effectively run analytics as DataBrain’s information grew.
- Plus, incoming buyer information had a dynamic schema, making it painful and costly for DataBrain to wash the information for PostgreSQL and run queries.
- Rockset solved these information issues, delaying the necessity to rent a knowledge engineer and saving DataBrain storage prices by offloading some information to Amazon S3.
The Working System for GTM Groups
Organizations perceive that their potential to make their clients comfortable and profitable is straight correlated to the standard of insights they will draw about every buyer. And these insights should not solely be related, however actionable in actual time. Understanding a buyer is confused right now as a substitute of tomorrow might be the distinction between protecting the client comfortable and protecting the client, interval. This drawback is very acute for groups whose job is to proactively have interaction with clients. That is the place DataBrain steps in.
DataBrain offers go-to-market groups with data-driven insights in regards to the well being of their accounts by leveraging real-time buyer information. By connecting to a variety of present SaaS instruments after which analyzing the information, DataBrain’s dashboard surfaces suggestions for account groups, in addition to permits them to drill down into information to find beneficial insights.

Maybe the account hasn’t been adopting new options, or it has had important contact factors with assist lately. That highlights a possible churn threat. Or maybe the account has taken benefit of latest capabilities, highlighting an upsell alternative. DataBrain analyzes a variety of knowledge factors throughout the client’s system and recommends potential actions.
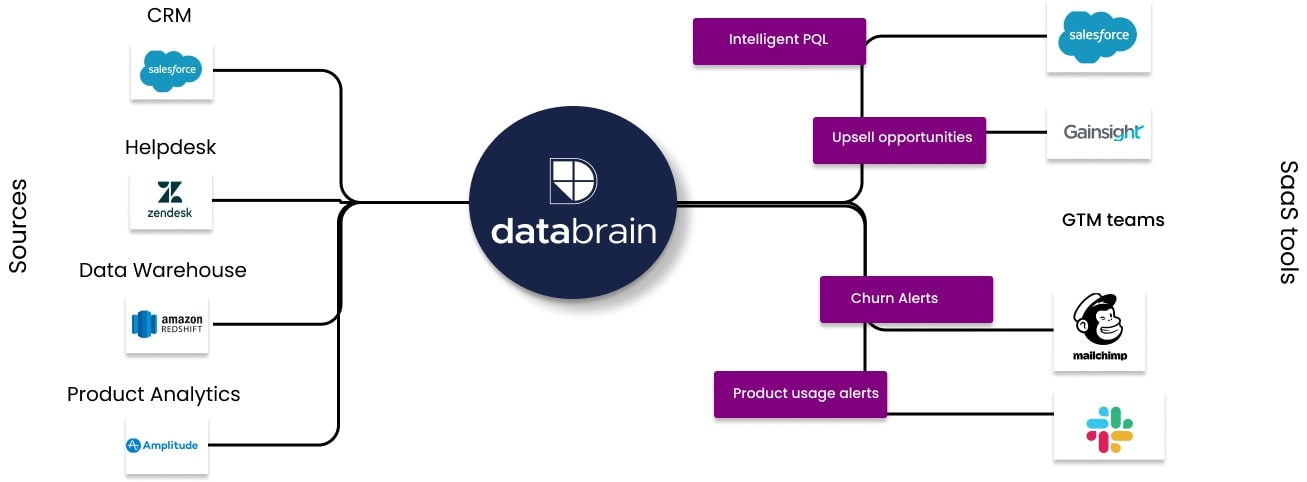
With DataBrain, GTM groups reminiscent of buyer success, gross sales operations and even product know tips on how to focus their time and craft their communication based mostly on real-time account information. CEO and founder Rahul Pattamatta describes DataBrain as “the working system for GTM groups.”
However as a fast, fast-growing firm in a aggressive area, DataBrain was operating into a number of challenges with its information stack.
Problem 1: Scaling PostgreSQL for Analytics
DataBrain was utilizing PostgreSQL by way of Amazon RDS to land and question each incoming buyer information in addition to inner firm information. This made sense when DataBrain didn’t have massive quantities of knowledge or advanced queries to run. PostgreSQL within the cloud was additionally simple to arrange and well-established as a expertise.
Nonetheless, DataBrain’s buyer base and utilization was rising quick. One buyer was already producing 60 million rows of knowledge. That was when DataBrain began to run into the pure limitations of PostgreSQL: excessive question latency for any kind of analytical question. PostgreSQL is simply not optimized for analytics. This was particularly obvious at scale.
“Writing SQL in opposition to an RDS occasion was simply unimaginable,” Pattamatta mentioned. “Our queries had been taking too lengthy and our app began to day out. This was unacceptable to our clients.”
DataBrain initially experimented with the extra analytics-optimized Amazon Redshift, however discovered it too gradual for its use case, with queries taking near 10 seconds.
Problem 2: Managing Always-Altering Schema on Buyer Knowledge
One other drawback DataBrain confronted was efficiently ingesting the semi-structured buyer information into PostgreSQL.
“We’ve to handle a dynamic schema and folks defining a bunch of various metrics of their JSON,” Pattamatta mentioned. “It was actually arduous for us to grasp what they had been sending us.”
Each time new columns had been added to JSON, the engineers at DataBrain went by way of nice effort to scan and establish the modifications within the schema earlier than updating the information. This wasn’t sustainable. DataBrain wanted a more-automated method to detect and handle schema modifications.
“I didn’t wish to rent a knowledge engineer to write down ETL scripts to make these transformations each time,” Pattamatta mentioned.
Problem 3: Accelerating Buyer Time-To-Worth
Lastly, DataBrain wanted to spice up its efficiency.
“This can be a aggressive area and with a view to stand out, I wished to verify our product has the quickest consumer expertise and our clients expertise the least time to their aha second available in the market,” Pattamatta mentioned.
This meant with the ability to mechanically index the information in the course of the preliminary ingest in order that clients can effortlessly get insights immediately on no matter questions they’ve.
“I need our product to be as self-service as potential,” Pattamatta mentioned. ”I noticed different options that required clients to spend quarter-hour with an engineer to arrange the preliminary integrations. I need my clients to simply level their integrations at us and have it work inside seconds.”
Serving to DataBrain Scale and Speed up
Pattamatta heard about Rockset on a podcast with Rockset’s CTO and co-founder Dhruba Borthakur.
“I used to be initially drawn to Rockset as a result of it appeared to supply a chic resolution to my schema drawback,” Pattamatta mentioned. “The truth that it might do analytics rapidly was additionally necessary.”
Pattamatta was impressed by how straightforward it was to deploy Rockset.
“The serverless nature of Rockset made it extremely easy to start out on,” he mentioned. “It took us solely a pair days to arrange our information pipelines into Rockset and after that, it was fairly simple. The docs had been nice.”
Resolution 1: Scale utilizing Rockset’s PostgreSQL integration
DataBrain took benefit of the native integration Rockset has with PostgreSQL. Desired datasets are immediately and mechanically synced into Rockset, which readies the information for queries in just a few seconds. Rockset then returns question outcomes, even for advanced analytical ones, in milliseconds.
Most significantly, Rockset is horizontally scalable. Compute and storage are utterly decoupled in Rockset, enabling DataBrain to cost-optimize for the specified efficiency degree. Apart from letting DataBrain keep away from doing analytics in expensive PostgreSQL, Rockset additionally allowed DataBrain to dump a big portion of its information from PostgreSQL into an S3 information lake, saving considerably on storage prices. And with a comparable connector for S3 (and many different sources), Rockset can mechanically keep in sync with each supply databases by studying their change streams.
Resolution 2: Ingest Dynamic, Semi-Structured Knowledge
Rockset helps schemaless ingestion of uncooked semi-structured information. The schema doesn’t should be recognized or outlined forward of time, and no clunky ETL pipelines are required. In different phrases, Rockset doesn’t require a schema however is however schema-aware, coupling the flexibleness of schemaless ingestion at write time with the power to deduce the schema at learn time. That is precisely what Databrain was searching for. By adopting Rockset, DataBrain didn’t want to rent a knowledge engineer simply to handle ETL scripts.
Resolution 3: Rockset’s Converged Index™
DataBrain wanted its clients’ semi-structured information to be listed rapidly so it might question the information instantly and present insights to clients immediately. Rockset solves this by way of its Converged Index expertise, which is optimized for various entry patterns, together with key-value, time-series, doc, search and aggregation queries.
Whereas most databases are optimized just for sure forms of information or queries, Rockset can return very quick question outcomes with out understanding prematurely the form of the information or the kind of queries. Each level lookups and mixture queries might be extraordinarily quick. Rockset’s P99 latency for filter queries on terabytes of knowledge is within the low milliseconds.
This gave DataBrain each the pace and suppleness to considerably increase the efficiency of its service whilst its buyer base grows.
Rockset Offers DataBrain Flexibility and Velocity
In abstract, DataBrain was in a position to reap the benefits of Rockset’s out-of-box integration with PostgreSQL to dump its analytical workloads into the quicker, extra cost-efficient Rockset. Rockset’s Sensible Schema characteristic was additionally vital, permitting DataBrain to make use of real-time SQL queries to extract significant insights from uncooked semi-structured information ingested with no predefined schema. Lastly, Rockset’s Converged Index allows low information latency and question latency, giving DataBrain the pace to remain forward of its opponents.
[ad_2]