[ad_1]
Information visualizations (DVs) have grow to be a typical follow within the massive knowledge period, utilized by varied functions and establishments to convey insights from large uncooked knowledge. Nevertheless, creating appropriate DVs stays a difficult process, even for consultants, because it requires visible evaluation experience and familiarity with the area knowledge. Additionally, customers should grasp complicated declarative visualization languages (DVLs) to precisely outline DV specs. To decrease the limitations to creating DVs and unlock their energy for most of the people, researchers have proposed a wide range of DV-related duties which have attracted important consideration from each trade and academia.
Current analysis has explored varied approaches to mitigate the challenges in knowledge visualization-related duties. Preliminary text-to-vis programs relied on predefined guidelines or templates, which had been environment friendly however restricted in dealing with the linguistic variability of consumer queries. To beat these limitations, researchers have turned to neural network-based strategies. For instance, Data2Vis conceptualizes visualization era as a sequence translation process, using an encoder-decoder neural structure. Equally, RGVisNet initiates the text-to-vis course of by retrieving a related question prototype, refining it via a graph neural community mannequin, after which adjusting the question to suit the goal state of affairs. Concurrently, vis-to-text has been proposed as a complementary process, with efficiency enhancements demonstrated via a twin coaching framework. Researchers have additionally outlined the duty of free-form query answering over knowledge visualizations, aiming to reinforce the understanding of knowledge and its visualizations. Additionally, a number of research have targeted on producing textual descriptions for knowledge visualizations, adopting sequence-to-sequence mannequin frameworks and using transformer-based architectures to translate visible knowledge into pure language summaries.
Researchers from PolyU, WeBank Co., Ltd, and HKUST suggest an efficient pre-trained language mannequin (PLM) known as DataVisT5. Constructing upon the text-centric T5 structure, DataVisT5 enhances the pre-training course of by incorporating a complete array of cross-modal datasets that combine pure language with knowledge visualization information, together with DV queries, database schemas, and tables. Impressed by giant language fashions which have integrated programming code into their pre-training knowledge, the researchers make use of CodeT5+ because the beginning checkpoint for DataVisT5, because it has been educated on code knowledge. To scale back coaching complexity, the researchers apply table-level database schema filtration. To beat the format consistency challenges between the information visualization and textual modalities, DataVisT5 introduces a unified encoding format for DV information that facilitates the convergence of textual content and DV modalities. Additionally, the pre-training targets for DataVisT5 embody the span corruption strategy of Masked Language Modeling (MLM) as utilized by the unique T5 mannequin, in addition to a Bidirectional Twin-Corpus goal that operates on source-target pairings. After the mixed-objective pre-training, the researchers conduct multi-task fine-tuning of DataVisT5 on DV-related duties, together with text-to-vis, vis-to-text, FeVisQA, and table-to-text.
Concisely, the important thing contributions of this analysis are:
- Researchers launched and launched DataVisT5: the primary PLM tailor-made for the joint understanding of textual content and DV.
- Enhanced the text-centric T5 structure to deal with cross-modal info. Their hybrid pre-training targets are conceived to unravel the complicated interaction between DV and textual knowledge, fostering a deeper integration of cross-modal insights.
- In depth experiments on public datasets for numerous DV duties together with text-to-vis, vis-to-text, FeVisQA, and table-to-text exhibit that DataVisT5 (proposed methodology) excels in multi-task settings, persistently outperforming sturdy baselines and establishing new SOTA performances.
Researchers have additionally offered primary definitions of varied elementary knowledge visualization-related ideas in order that customers can have a profound understanding of the proposed methodology.
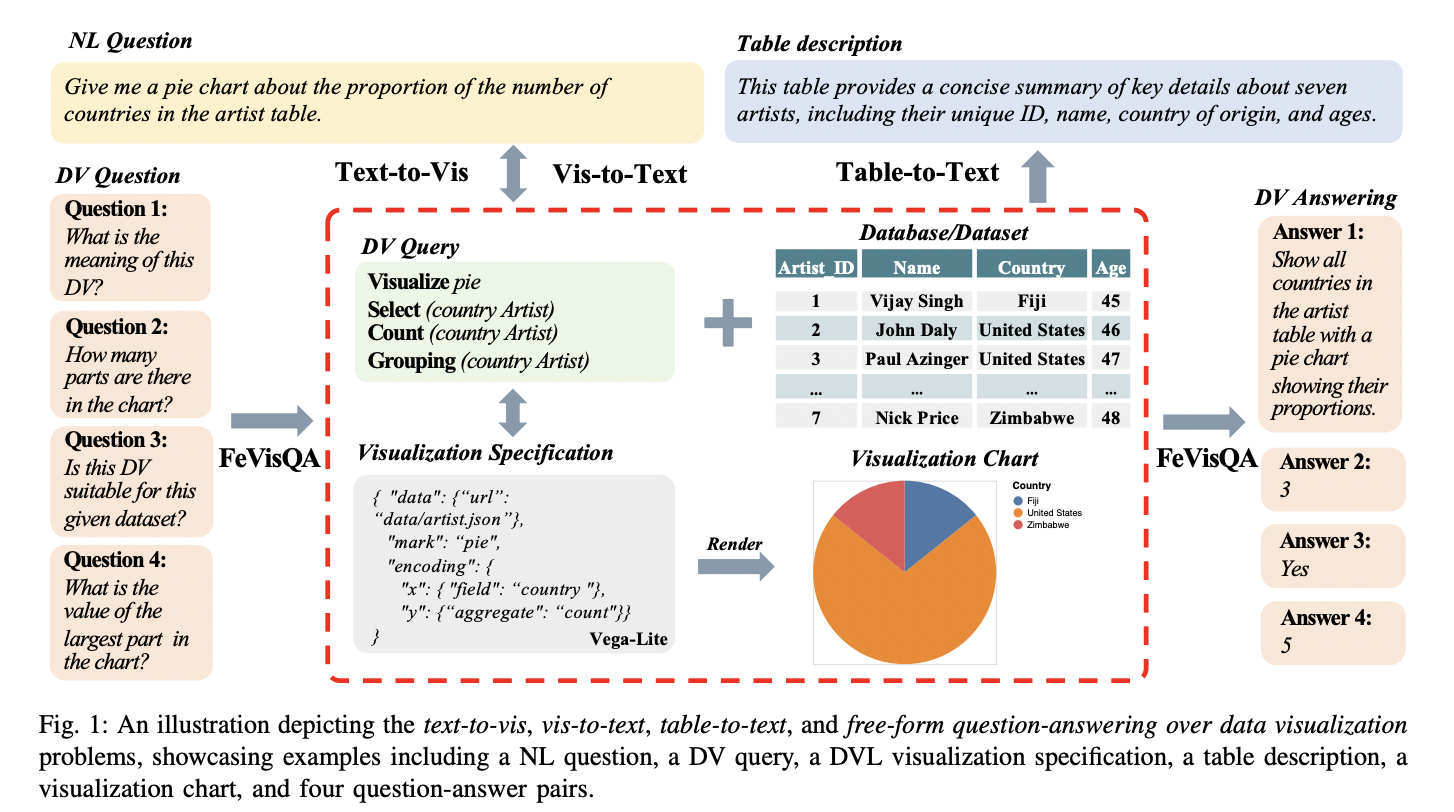
Pure language questions allow customers to formulate queries intuitively, even with out specialised DV or programming expertise. Declarative visualization languages, resembling Vega-Lite and ggplot2, present a set of specs to outline the development of visualizations, together with chart varieties, colours, sizes, and different visible properties. Visualization specs, encoded in JSON format, describe the dataset and its visible attributes based on the syntax of a selected DVL. The knowledge visualization question framework introduces a SQL-like question format to encapsulate the total spectrum of potential DVLs, permitting for conversion between totally different visualization specs. Lastly, the knowledge visualization charts are the visible representations, resembling scatters, bars, or maps, that convey the summarized knowledge and insights outlined by the visualization specification.
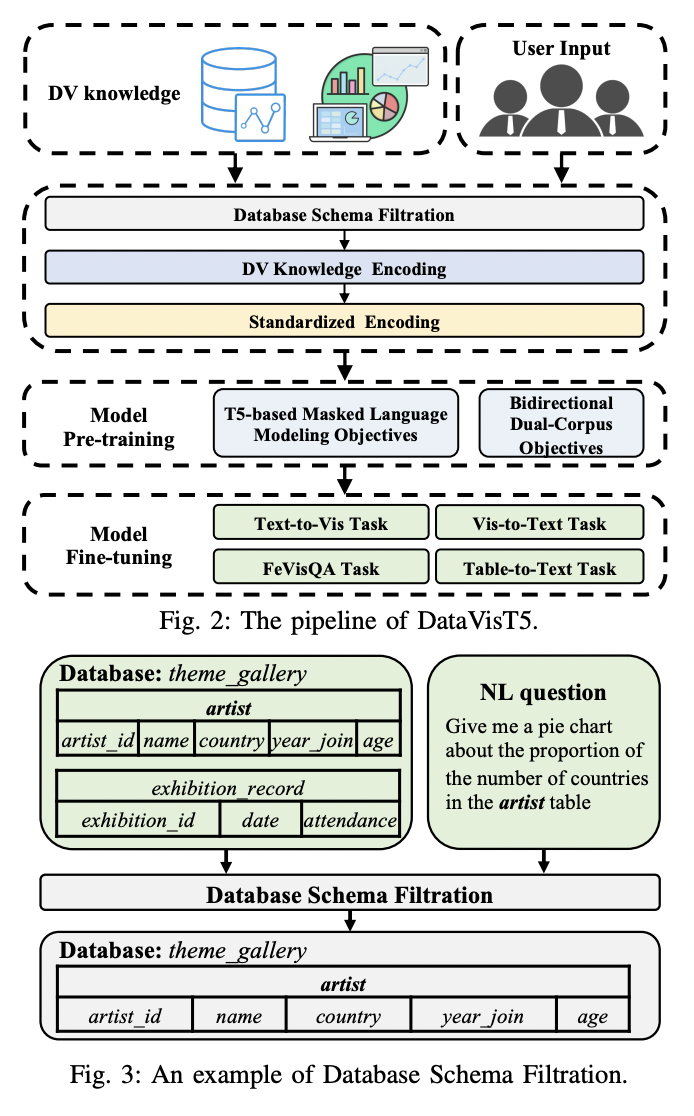
The proposed methodology DataVisT5, follows a complete pipeline comprising 5 principal levels: (1) Database schema filtration, (2) DV information Encoding, (3) Standardized Encoding, (4) Mannequin Pre-training, and (5) Mannequin Nice-tuning. The database schema filtration course of identifies the referenced tables within the given pure language query by evaluating n-grams extracted from the database schema with these within the textual content. This enables the acquisition of a sub-database schema that’s semantically aligned. The DV information encoding section then linearizes the DV information, together with DV queries, database schemas, and tables, right into a unified format. The standardized encoding stage normalizes this DV information to facilitate extra environment friendly studying. The ensuing corpus, in its unified type, is then used to pre-train the proposed DataVisT5 mannequin. Lastly, the pre-trained DataVisT5 undergoes multi-task fine-tuning on varied DV-related duties.
Database schema filtration method matches n-grams between the pure language query and database tables, figuring out related schema components and extracting a sub-schema to reduce info loss through the integration of knowledge visualization and textual content modalities.
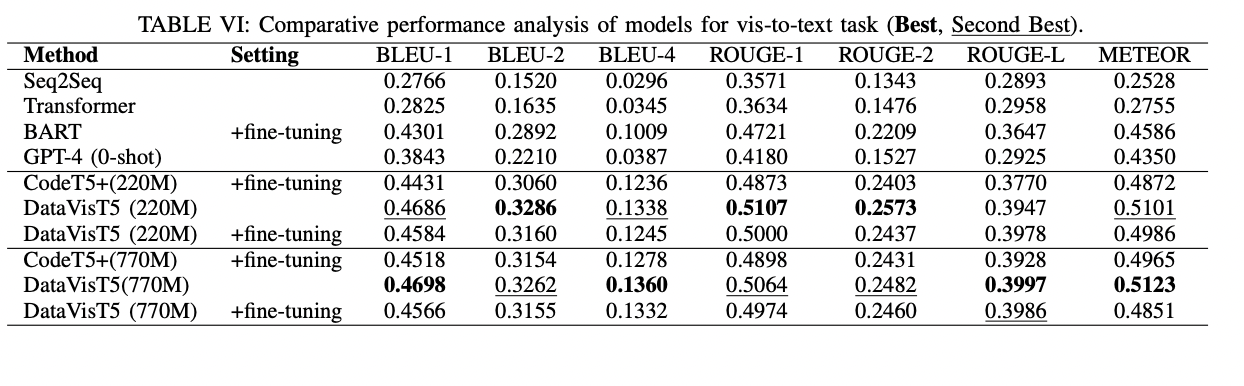
To deal with the text-DV modality hole, the researchers suggest a unified format for DV information illustration, enabling fashions to make the most of in depth pre-training on smaller datasets and mitigating efficiency decline from knowledge heterogeneity throughout multi-task coaching.
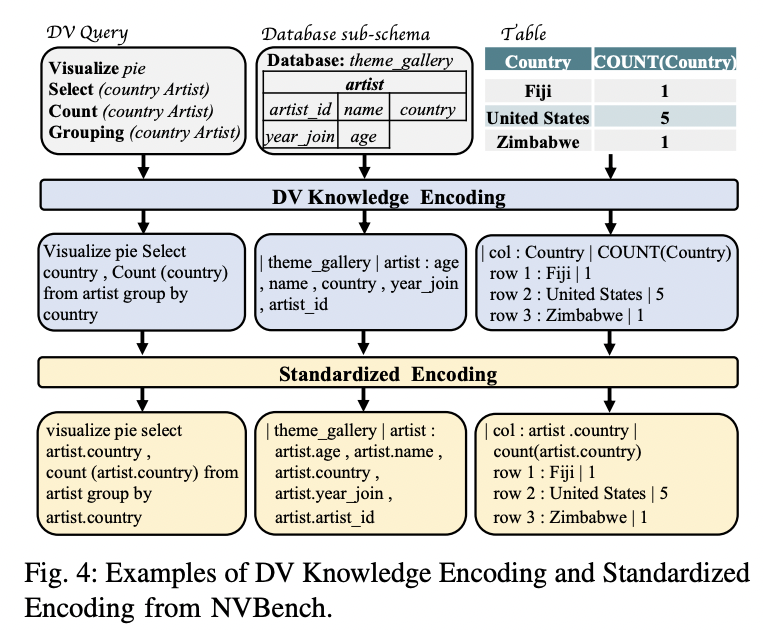

To mitigate the stylistic inconsistencies within the manually generated knowledge visualization queries, the researchers carried out a preprocessing technique. This consists of standardizing the column notation, formatting parentheses and quotes, dealing with ordering clauses, changing desk aliases with precise names, and changing all the question to lowercase. These steps assist mitigate the training challenges posed by the various annotation habits of a number of annotators, making certain a extra constant format for the DV information.

The researchers make use of a bidirectional dual-corpus pretraining technique, the place the mannequin is educated to translate randomly chosen supply and goal corpora in each instructions, enhancing the mannequin’s potential to be taught the connection between textual content and knowledge visualization information.
The researchers make use of temperature mixing to mix coaching knowledge from all duties, balancing the affect of every process and inspiring the mannequin to be taught representations helpful throughout varied corpora, resulting in improved generalization and robustness in dealing with numerous knowledge visualization duties.
DataVisT5 demonstrates important enhancements over current methods like Seq2Vis, Transformer, RGVisNet, ncNet, and GPT-4. In in depth experiments, this strategy achieved a exceptional 46.15% enhance within the EM metric on datasets with out be part of operations in comparison with the earlier state-of-the-art RGVisNet mannequin. Additionally, DataVisT5 outperformed the in-context studying strategy utilizing GPT-4 in eventualities involving be part of operations, enhancing the EM metric by 44.59% and 49.2%. Notably, in these difficult be part of operation eventualities the place different fashions have traditionally struggled, DataVisT5 achieved a formidable EM of 0.3451. The ablation research highlights the effectiveness of the proposed strategy, with finetuned fashions of 220M and 770M parameters persistently outperforming the finetuned CodeT5+ mannequin. These outcomes underscore the superior comprehension of DataVisT5 with regards to DV question syntax and semantics, benefiting from the hybrid targets pre-training.

On this research, the researchers have proposed an efficient pre-trained language mannequin known as DataVisT5, particularly designed to reinforce the mixing of cross-modal info in DV information and pure language associations. DataVisT5 introduces a singular mechanism to seize extremely related database schemas from pure language mentions of tables, successfully unifying and normalizing the encoding of DV information, together with DV queries, database schemas, and tables. The strong hybrid pre-training targets employed on this mannequin assist unravel the complicated interaction between DV and textual knowledge, fostering a deeper integration of cross-modal insights.
By extending the text-centric T5 structure to adeptly course of cross-modal info, DataVisT5 addresses a number of duties associated to knowledge visualization with exceptional efficiency. The in depth experimental outcomes exhibit that DataVisT5 persistently outperforms state-of-the-art fashions throughout a variety of DV duties, increasing the functions of pre-trained language fashions and pushing the boundaries of what’s achievable in automated knowledge visualization and interpretation. This analysis represents a big development within the subject and opens up new avenues for additional exploration and innovation.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.

[ad_2]