[ad_1]
Apache Druid is a distributed real-time analytics database generally used with person exercise streams, clickstream analytics, and Web of issues (IoT) gadget analytics. Druid is usually useful in use instances that prioritize real-time ingestion and quick queries.
Druid’s record of options consists of individually compressed and listed columns, numerous stream ingestion connectors and time-based partitioning. It’s identified to carry out effectively when used as designed: to carry out quick queries on massive quantities of knowledge. Nevertheless, utilizing Druid might be problematic when used exterior its regular parameters — for instance, to work with nested information.
On this article, we’ll talk about ingesting and utilizing nested information in Apache Druid. Druid doesn’t retailer nested information within the type usually present in, say, a JSON dataset. So, ingesting nested information requires us to flatten our information earlier than or throughout ingestion.
Flattening Your Information
We are able to flatten information earlier than or throughout ingestion utilizing Druid’s area flattening specification. We are able to additionally use different instruments and scripts to assist flatten nested information. Our last necessities and import information construction decide the flattening alternative.
A number of textual content processors assist flatten information, and probably the most in style is jq. jq is like JSON’s grep, and a jq command is sort of a filter that outputs to the usual output. Chaining filters by way of piping permits for highly effective processing operations on JSON information.
For the next two examples, we’ll create the governors.json file. Utilizing your favourite textual content editor, create the file and duplicate the next traces into it:
[
{
"state": "Mississippi",
"shortname": "MS",
"info": {"governor": "Tate Reeves"},
"county": [
{"name": "Neshoba", "population": 30000},
{"name": "Hinds", "population": 250000},
{"name": "Atlanta", "population": 19000}
]
},
{
"state": "Michigan",
"shortname": "MI",
"data": {"governor": "Gretchen Whitmer"},
"county": [
{"name": "Missauki", "population": 15000},
{"name": "Benzie", "population": 17000}
]
}
]
With jq put in, run the next from the command line:
$ jq --arg delim '_' 'scale back (tostream|choose(size==2)) as $i ({};
.[[$i[0][]|tostring]|be part of($delim)] = $i[1]
)' governors.json
The outcomes are:

Essentially the most versatile data-flattening technique is to put in writing a script or program. Any programming language will do for this. For demonstration functions, let’s use a recursive technique in Python.
def flatten_nested_json(nested_json):
out = {}
def flatten(njson, identify=""):
if sort(njson) is dict:
for path in njson:
flatten(njson[path], identify + path + ".")
elif sort(njson) is record:
i = 0
for path in njson:
flatten(path, identify + str(i) + ".")
i += 1
else:
out[name[:-1]] = njson
flatten(nested_json)
return out
The outcomes appear to be this:

Flattening may also be achieved throughout the ingestion course of. The FlattenSpec is a part of Druid’s ingestion specification. Druid applies it first throughout the ingestion course of.
The column names outlined right here can be found to different elements of the ingestion specification. The FlattenSpec solely applies when the information format is JSON, Avro, ORC, or Parquet. Of those, JSON is the one one which requires no additional extensions in Druid. On this article, we’re discussing ingestion from JSON information sources.
The FlattenSpec takes the type of a JSON construction. The next instance is from the Druid documentation and covers all of our dialogue factors within the specification:

The useFieldDiscovery flag is about to true above. This enables the ingestion specification to entry all fields on the foundation node. If this flag have been to be false, we’d add an entry for every column we wished to import.
Along with root, there are two different area definition sorts. The path area definition accommodates an expression of sort JsonPath. The “jq” sort accommodates an expression with a subset of jq instructions referred to as jackson-jq. The ingestion course of makes use of these instructions to flatten our information.
To discover this in additional depth, we’ll use a subset of IMDB, transformed to JSON format. The information has the next construction:

Since we aren’t importing all of the fields, we don’t use the automated area discovery choice.
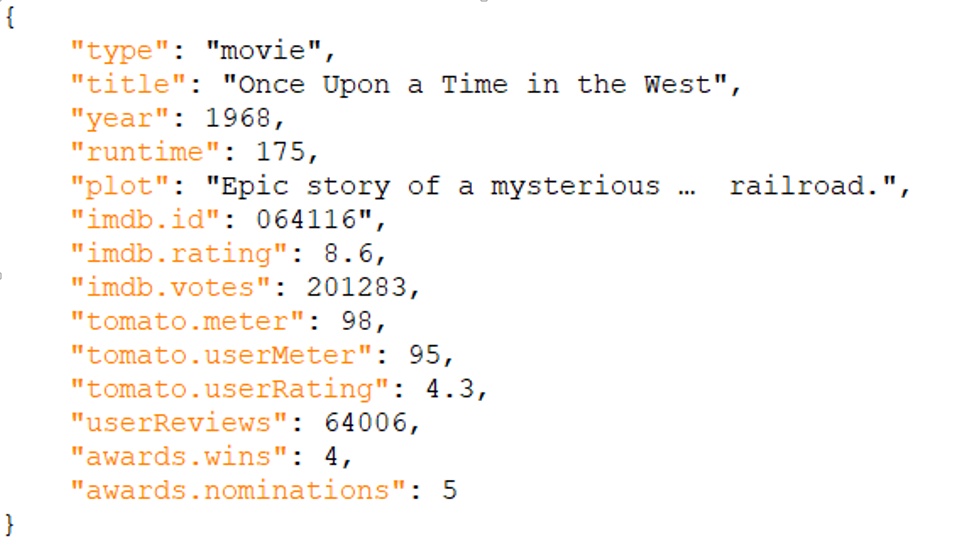
Our FlattenSpec seems like this:


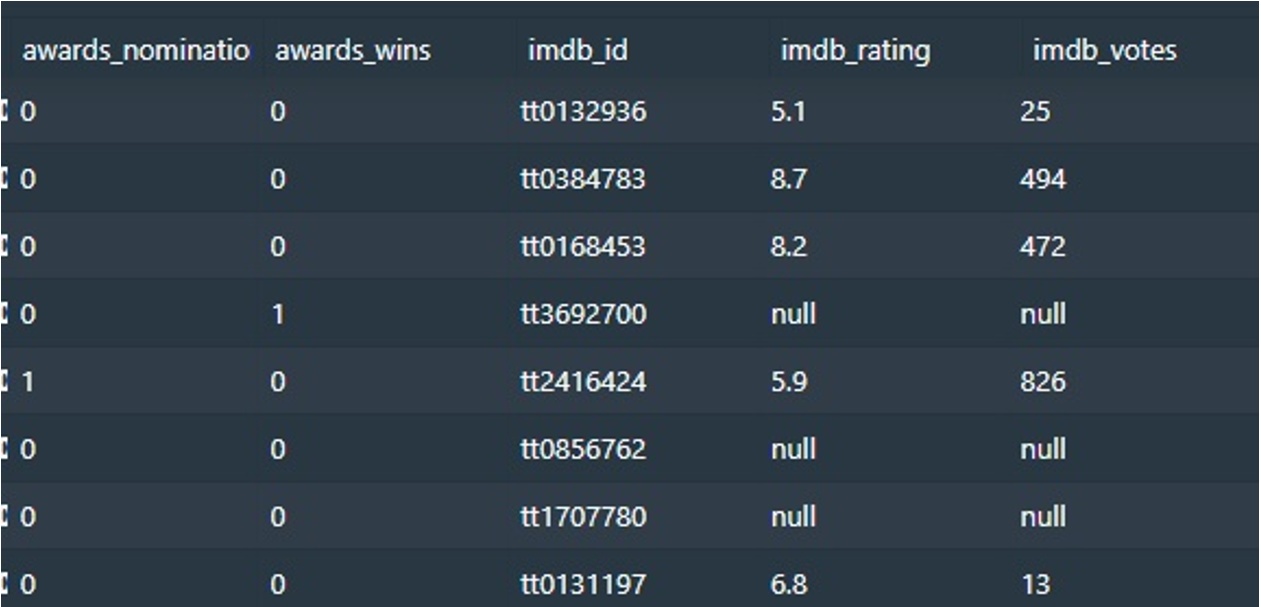
The newly created columns within the ingested information are displayed under:
Querying Flattened Information
On the floor, plainly querying denormalized information shouldn’t current an issue. Nevertheless it might not be as simple because it appears. The one non-simple information sort Druid helps is multi-value string dimensions.
The relationships between our columns dictate how we flatten your information. For instance, think about an information construction to find out these three information factors:
- The distinct depend of films launched in Italy OR launched within the USA
- The distinct depend of films launched in Italy AND launched within the USA
- The distinct depend of films which are westerns AND launched within the USA
Easy flattening of the nation and style columns produces the next:
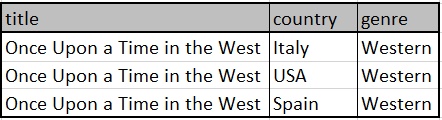
With the above construction, it’s not potential to get the distinct depend of films which are launched in Italy AND launched within the USA as a result of there are not any rows the place nation = “Italy” AND nation = “USA”.
Another choice is to import information as multi-value dimensions:
On this case, we will decide the “Italy” AND/OR “USA” quantity utilizing the LIKE operator, however not the connection between nations and genres. One group proposed another flattening, the place Druid imports each the information and record:

On this case, all three distinct counts are potential utilizing:
- Nation = ‘Italy’ OR County = ‘USA’
- International locations LIKE ‘Italy’ AND International locations LIKE ‘USA’
- Style = ‘Western’ AND International locations LIKE ‘USA’
Alternate options to Flattening Information
In Druid, it’s preferable to make use of flat information sources. But, flattening might not all the time be an choice. For instance, we might wish to change dimension values post-ingestion with out re-ingesting. Below these circumstances, we wish to use a lookup for the dimension.
Additionally, in some circumstances, joins are unavoidable because of the nature and use of the information. Below these situations, we wish to cut up the information into a number of separate information throughout ingestion. Then, we will adapt the affected dimension to hyperlink to the “exterior” information whether or not by lookup or be part of.
The memory-resident lookup is quick by design. All lookup tables should slot in reminiscence, and when this isn’t potential, a be part of is unavoidable. Sadly, joins come at a efficiency value in Druid. To indicate this value, we’ll carry out a easy be part of on an information supply. Then we’ll measure the time to run the question with and with out the be part of.
To make sure this check was measurable, we put in Druid on an previous 4GB PC working Ubuntu Server. We then ran a sequence of queries tailored from these Xavier Léauté used when benchmarking Druid in 2014. Though this isn’t the most effective strategy to becoming a member of information, it does present how a easy be part of impacts efficiency.
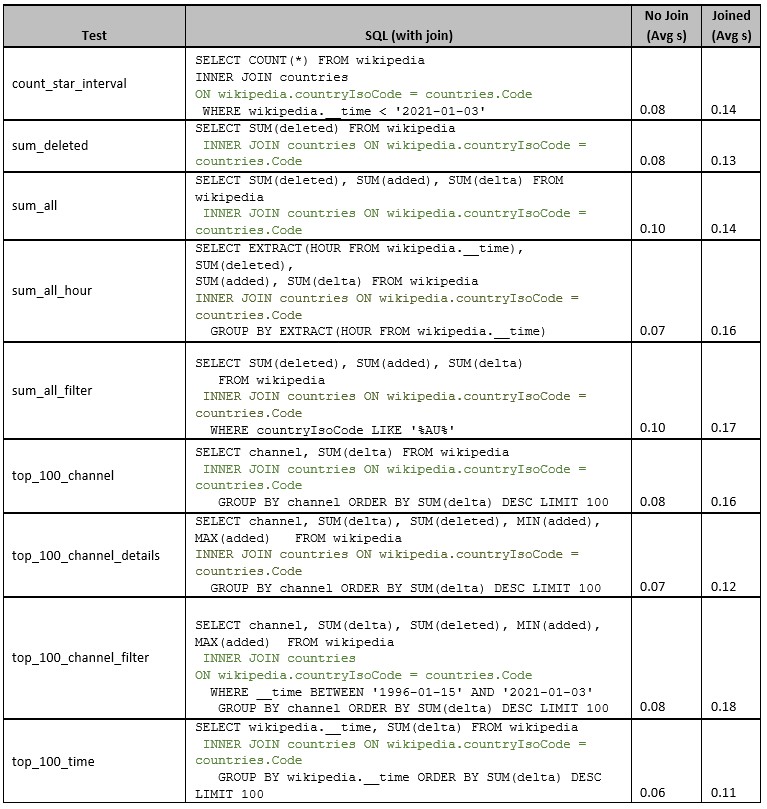
Because the chart demonstrates, every be part of makes the question run just a few seconds slower — as much as twice as sluggish as queries with out joins. This delay provides up as your variety of joins will increase.
Nested Information in Druid vs Rockset
Apache Druid is nice at doing what it was designed to do. Points happen when Druid works exterior these parameters, resembling when utilizing nested information.
Obtainable options to deal with nested information in Druid are, at greatest, clunky. A change within the enter information requires adapting your ingestion technique. That is true whether or not utilizing Druid’s native flattening or some type of pre-processing.
Distinction this with Rockset, a real-time analytics database that totally helps the ingestion and querying of nested information, making it accessible for quick queries. The flexibility to deal with nested information as is saves a number of information engineering effort in flattening information, or in any other case working round this limitation, as we explored earlier within the weblog.
Rockset indexes each particular person area with out the person having to carry out any handbook specification. There isn’t a requirement to flatten nested objects or arrays at ingestion time. An instance of how nested objects and arrays are introduced in Rockset is proven under:

In case your want is for flat information ingestion, then Druid could also be an acceptable alternative. When you want deeply nested information, nested arrays, or real-time outcomes from normalized information, think about a database like Rockset as an alternative. Be taught extra about how Rockset and Druid evaluate.
[ad_2]