[ad_1]
A serious problem within the discipline of pure language processing (NLP) is addressing the restrictions of decoder-only Transformers. These fashions, which type the spine of huge language fashions (LLMs), undergo from important points akin to representational collapse and over-squashing. Representational collapse happens when totally different enter sequences produce almost an identical representations, whereas over-squashing results in a lack of sensitivity to particular tokens because of the unidirectional stream of knowledge. These challenges severely hinder the flexibility of LLMs to carry out important duties like counting or copying sequences precisely, that are basic for varied computational and reasoning duties in AI functions.
Present strategies to sort out these challenges contain growing mannequin complexity and enhancing coaching datasets. Strategies akin to utilizing greater precision floating-point codecs and incorporating extra refined positional encodings have been explored. Nevertheless, these strategies are computationally costly and infrequently impractical for real-time functions. Present approaches additionally embody the usage of auxiliary instruments to help fashions in performing particular duties. Regardless of these efforts, basic points like representational collapse and over-squashing persist because of the inherent limitations of the decoder-only Transformer structure and the low-precision floating-point codecs generally used.
Researchers from Google DeepMind and the College of Oxford suggest a theoretical sign propagation evaluation to research how info is processed inside decoder-only Transformers. They give attention to the illustration of the final token within the ultimate layer, which is essential for next-token prediction. The proposed strategy identifies and formalizes the phenomena of representational collapse and over-squashing. Representational collapse is proven to happen when distinct enter sequences yield almost an identical representations attributable to low-precision floating-point computations. Over-squashing is analyzed by inspecting how info from earlier tokens is disproportionately squashed, resulting in diminished mannequin sensitivity. This strategy is important because it gives a brand new theoretical framework to know these limitations and presents easy but efficient options to mitigate them.
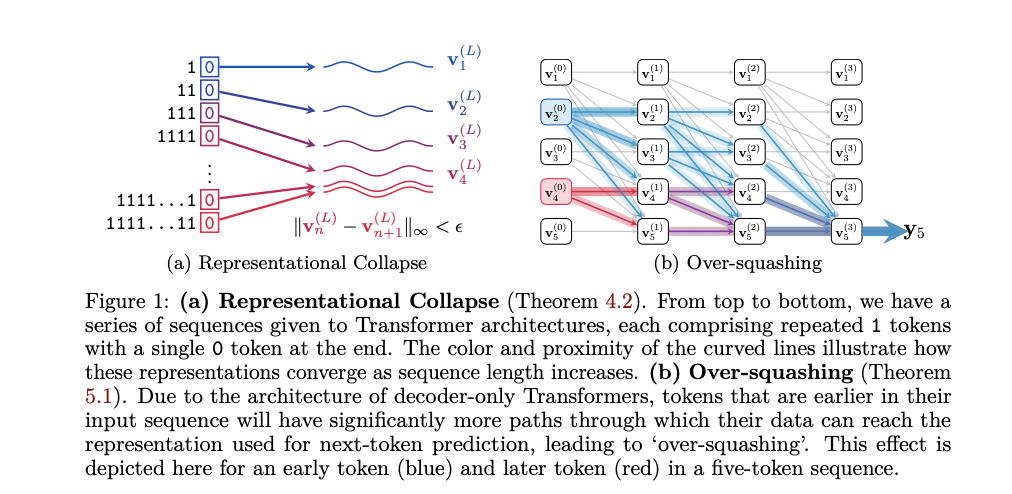
The proposed technique entails an in depth theoretical evaluation supported by empirical proof. The researchers use mathematical proofs and experimental information to show representational collapse and over-squashing. They make use of modern LLMs to validate their findings and illustrate how low floating-point precision exacerbates these points. The evaluation consists of inspecting consideration weights, layer normalization results, and positional encoding decay. The researchers additionally talk about sensible implications, such because the influence of quantization and tokenization on mannequin efficiency, and suggest including extra tokens to lengthy sequences as a sensible answer to forestall representational collapse.
The outcomes show that decoder-only Transformer fashions expertise important efficiency points attributable to representational collapse and over-squashing, significantly in duties requiring counting and copying sequences. Experiments performed on modern giant language fashions (LLMs) reveal a marked decline in accuracy as sequence size will increase, with fashions struggling to distinguish between distinct sequences. The empirical proof helps the theoretical evaluation, exhibiting that low-precision floating-point codecs exacerbate these points, resulting in frequent errors in next-token prediction. Importantly, the proposed options, akin to introducing extra tokens in sequences and adjusting floating-point precision, have been empirically validated, resulting in notable enhancements in mannequin efficiency and robustness in dealing with longer sequences. These findings spotlight the vital want to deal with basic architectural limitations in LLMs to boost their accuracy and reliability in sensible functions.
In conclusion, the paper gives an intensive evaluation of the restrictions inherent in decoder-only Transformer fashions, particularly specializing in the problems of representational collapse and over-squashing. By way of each theoretical exploration and empirical validation, the authors show how these phenomena impair the efficiency of huge language fashions (LLMs) in important duties akin to counting and copying sequences. The research identifies vital architectural flaws exacerbated by low-precision floating-point codecs and proposes efficient options to mitigate these issues, together with the introduction of extra tokens and precision changes. These interventions considerably improve mannequin efficiency, making them extra dependable and correct for sensible functions. The findings underscore the significance of addressing these basic points to advance the capabilities of LLMs in pure language processing duties.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 44k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]