[ad_1]
Pure language processing is advancing quickly, specializing in optimizing giant language fashions (LLMs) for particular duties. These fashions, typically containing billions of parameters, pose a big problem in customization. The goal is to develop environment friendly and higher strategies for fine-tuning these fashions to particular downstream duties with out prohibitive computational prices. This requires modern approaches to parameter-efficient fine-tuning (PEFT) that maximize efficiency whereas minimizing useful resource utilization.
One main downside on this area is the resource-intensive nature of customizing LLMs for particular duties. Conventional fine-tuning strategies usually replace all mannequin parameters, which may result in excessive computational prices and overfitting. Given the dimensions of recent LLMs, resembling these with sparse architectures that distribute duties throughout a number of specialised specialists, there’s a urgent want for extra environment friendly fine-tuning methods. The problem lies in optimizing efficiency whereas guaranteeing the computational burden stays manageable.
Present strategies for PEFT in dense-architecture LLMs embrace low-rank adaptation (LoRA) and P-Tuning. These strategies usually contain including new parameters to the mannequin or selectively updating present ones. As an illustration, LoRA decomposes weight matrices into low-rank elements, which helps cut back the variety of parameters that should be skilled. Nonetheless, these approaches have primarily centered on dense fashions and don’t absolutely exploit the potential of sparse-architecture LLMs. In sparse fashions, totally different duties activate totally different subsets of parameters, making conventional strategies much less efficient.
DeepSeek AI and Northwestern College researchers have launched a novel methodology referred to as Professional-Specialised Fantastic-Tuning (ESFT) tailor-made for sparse-architecture LLMs, particularly these utilizing a mixture-of-experts (MoE) structure. This methodology goals to fine-tune solely essentially the most related specialists for a given process whereas freezing the opposite specialists and mannequin elements. By doing so, ESFT enhances tuning effectivity and maintains the specialization of the specialists, which is essential for optimum efficiency. The ESFT methodology capitalizes on the MoE structure’s inherent skill to assign totally different duties to specialists, guaranteeing that solely the required parameters are up to date.
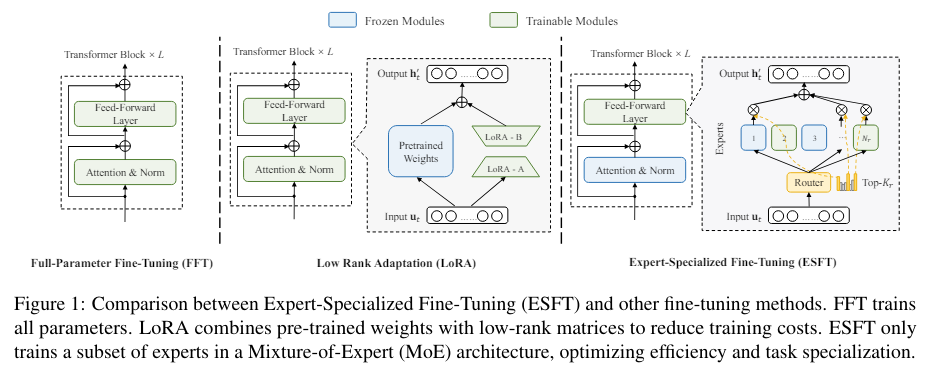
In additional element, ESFT includes calculating the affinity scores of specialists to task-specific information and choosing a subset of specialists with the very best relevance. These chosen specialists are then fine-tuned whereas the remainder of the mannequin stays unchanged. This selective method considerably reduces the computational prices related to fine-tuning. As an illustration, ESFT can cut back storage necessities by as much as 90% and coaching time by as much as 30% in comparison with full-parameter fine-tuning. This effectivity is achieved with out compromising the mannequin’s total efficiency, as demonstrated by the experimental outcomes.
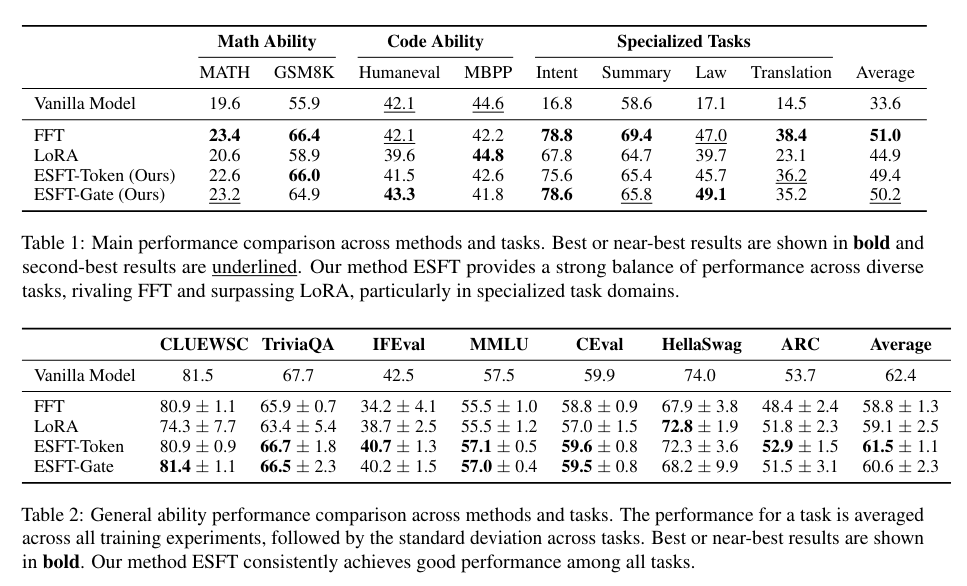
In varied downstream duties, ESFT not solely matched however typically surpassed the efficiency of conventional full-parameter fine-tuning strategies. For instance, in duties like math and code, ESFT achieved important efficiency positive factors whereas sustaining a excessive diploma of specialization. The strategy’s skill to effectively fine-tune a subset of specialists, chosen primarily based on their relevance to the duty, highlights its effectiveness. The outcomes confirmed that ESFT maintained normal process efficiency higher than different PEFT strategies like LoRA, making it a flexible and highly effective instrument for LLM customization.

In conclusion, the analysis introduces Professional-Specialised Fantastic-Tuning (ESFT) as an answer to the issue of resource-intensive fine-tuning in giant language fashions. By selectively tuning related specialists, ESFT optimizes each efficiency and effectivity. This methodology leverages the specialised structure of sparse-architecture LLMs to attain superior outcomes with decreased computational prices. The analysis demonstrates that ESFT can considerably enhance coaching effectivity, cut back storage and coaching time, and keep excessive efficiency throughout varied duties. This makes ESFT a promising method for future developments in customizing giant language fashions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.
[ad_2]