[ad_1]

The discharge of ChatGPT pushed the curiosity in and expectations of Giant Language Mannequin based mostly use instances to document heights. Each firm is seeking to experiment, qualify and finally launch LLM based mostly providers to enhance their inner operations and to degree up their interactions with their customers and prospects.
At Cloudera, now we have been working with our prospects to assist them profit from this new wave of innovation. Within the first article of this sequence, we’re going to share the challenges of Enterprise adoption and suggest a doable path to embrace these new applied sciences in a protected and managed method.
Highly effective LLMs can cowl various matters, from offering life-style recommendation to informing the design of transformer architectures. Nevertheless, enterprises have way more particular wants. They want the solutions for his or her enterprise context. For instance, if certainly one of your workers asks the expense restrict on her lunch whereas attending a convention, she is going to get into hassle if the LLM doesn’t have entry to the precise coverage your organization has put out. Privateness considerations loom massive, as many enterprises are cautious about sharing their inner information base with exterior suppliers to safeguard information integrity. This delicate steadiness between outsourcing and information safety stays a pivotal concern. Furthermore, the opacity of LLMs amplifies security worries, particularly when the fashions lack transparency when it comes to coaching information, processes, and bias mitigation.
The excellent news is that each one enterprise necessities could be achieved with the ability of open supply. Within the following part, we’re going to stroll you thru our latest Utilized Machine Studying Prototype (AMP), “LLM Chatbot Augmented with Enterprise Information”. This AMP demonstrates easy methods to increase a chatbot software with an enterprise information base to be context conscious, doing this in a manner that permits you to deploy privately anyplace even in an air gapped atmosphere. Better of all, the AMP was constructed with 100% open supply know-how.
The AMP deploys an Utility in CML that produces two totally different solutions, the primary one utilizing solely the information base the LLM was skilled on, and a second one which’s grounded in Cloudera’s context.
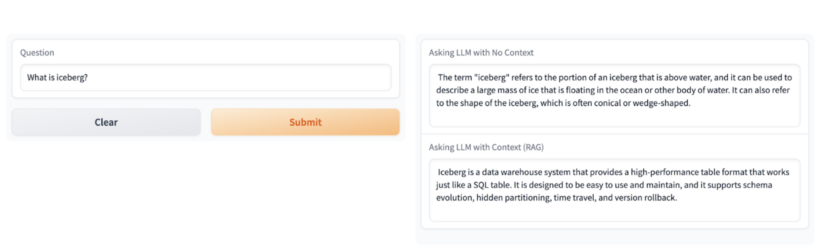
For instance, if you ask “What’s Iceberg?” The primary reply is a factual response explaining an iceberg as an enormous block of ice floating in water. For most individuals this can be a legitimate reply however in case you are an information skilled, iceberg is one thing utterly totally different. For these of us within the information world, Iceberg as a rule refers to an open supply high-performance desk format that’s the muse of the Open Lakehouse.
Within the following part, we’ll cowl the important thing particulars of the AMP implementation.
LLM AMP
AMPs are pre-built, end-to-end ML initiatives particularly designed to kickstart enterprise use instances. In Cloudera Machine Studying (CML), you possibly can choose and deploy an entire ML challenge from the AMP catalog with a single click on.
All AMPs are open supply and out there on GitHub, so even if you happen to don’t have entry to Cloudera Machine Studying you possibly can nonetheless entry the challenge and deploy it in your laptop computer or different platform with some tweeks.
When you deploy, the AMP executes a sequence of steps to configure and provision everythings to finish the end-to-end use case. Within the subsequent few sections we’ll undergo the primary steps on this course of.
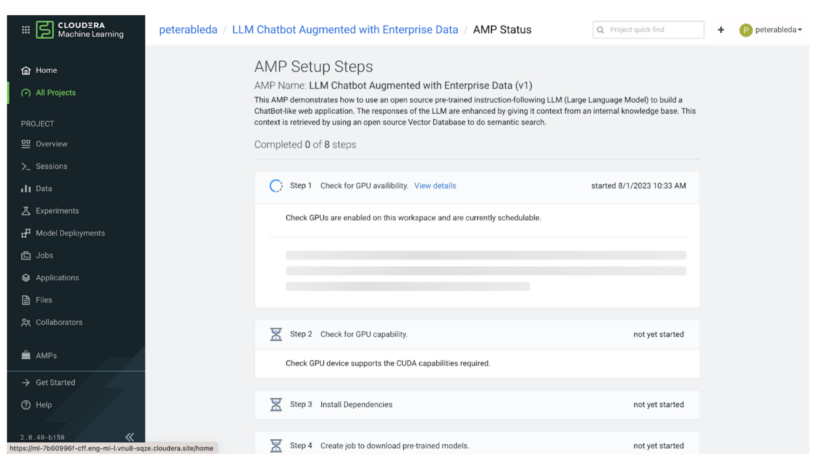
In steps 1 and a couple of the AMP executes a sequence of checks to ensure that the atmosphere has the mandatory compute sources to host this use case. The AMP is constructed with state-of-the-art open supply LLM know-how and requires not less than 1 NVIDIA GPU with CUDA compute functionality 5.0 or increased. (i.e., V100, A100, T4 GPUs).
As soon as the AMP confirms that the atmosphere has the required compute sources, it proceeds with Venture Setup. In Step 3, the AMP installs the dependencies from the necessities.txt file like transformers after which in steps 4 and 5 it downloads the configured fashions from HuggingFace. The AMP makes use of a sentence-transformer mannequin to map textual content to a high-dimensional vector area (embedding), enabling the execution of similarity searches and an H2O mannequin because the query answering LLM.
Steps 6 and seven carry out the ETL portion of the prototype. Throughout these steps, the AMP populates a Vector DB with an enterprise information base as embeddings for semantic search.

This isn’t strictly a part of the AMP however price noting that the standard of the AMP’s Chatbot responses will closely depend upon the standard of the info that it’s given for context. Thus it’s important that you just arrange and clear your information base to make sure top quality responses from the Chatbot.
For the information base the AMP makes use of pages from the Cloudera documentation, then it chunks and hundreds that information to an open supply embedding mannequin (the one which was downloaded within the earlier steps) and inserts the embeddings to a Milvus Vector Database.
Step 8 completes the prototype by deploying the person going through chatbot software. The beneath picture reveals the 2 solutions that the chatbot software produces, one with and one with out enterprise context.

As soon as the appliance receives a query it first, following the pink path, passes the query to the Open Supply Instruction-Tuned LLM to generate a solution.
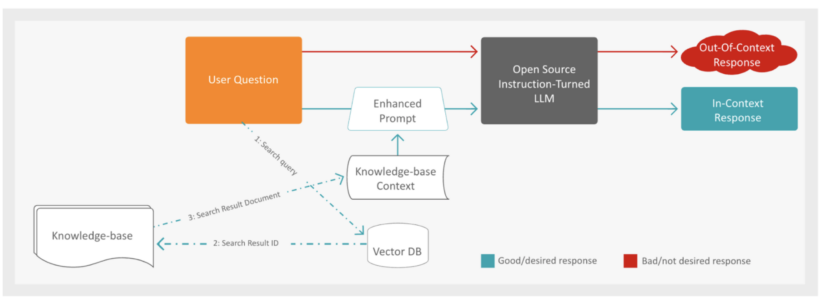
The method of RAG (Retrieval-Augmented Era) for producing a factual response to a person query entails a number of steps. First, the system augments the person’s query with further context from a information base. To realize this, the Vector Database is looked for paperwork which might be semantically closest to the person’s query, leveraging the usage of embeddings to seek out related content material.
As soon as the closest paperwork are recognized, the system retrieves the context through the use of the doc IDs and embeddings obtained within the search response. With the enriched context, the subsequent step is to submit an enhanced immediate to the LLM to generate the factual response. This immediate consists of each the retrieved context and the unique person query.
Lastly, the generated response from the LLM is introduced to the person via an online software, offering a complete and correct reply to their inquiry. This multi-step method ensures a well-informed and contextually related response, enhancing the general person expertise.
After all of the above steps are accomplished, you’ve got a completely functioning end-to-end deployment of the prototype.
Able to deploy the LLM AMP chatbot and improve your person expertise?
Head to Cloudera Machine Studying (CML) and entry the AMP catalog. With only a single click on, you possibly can choose and deploy the entire challenge, kickstarting your use case effortlessly. Don’t have entry to CML? No worries! The AMP is open-source and out there on GitHub. You possibly can nonetheless deploy it in your laptop computer or different platforms with minimal tweaks. Go to the GitHub repository right here.
If you wish to study extra concerning the AI options that Cloudera is delivering to our prospects, come take a look at our Enterprise AI web page.
Within the subsequent article of this sequence, we’ll delve into the artwork of customizing the LLM AMP to fit your group’s particular wants. Uncover easy methods to combine your enterprise information base seamlessly into the chatbot, delivering customized and contextually related responses. Keep tuned for sensible insights, step-by-step steering, and real-world examples to empower your AI use instances.
[ad_2]