[ad_1]
AI methods integrating pure language processing with database administration can unlock important worth by enabling customers to question customized information sources utilizing pure language. Present strategies like Text2SQL and Retrieval-Augmented Era (RAG) are restricted, dealing with solely a subset of queries: Text2SQL addresses queries translatable to relational algebra, whereas RAG focuses on level lookups inside databases. These strategies usually fall quick for complicated questions requiring area data, semantic reasoning, or world data. Efficient methods should mix the computational precision of databases with the language fashions’ reasoning capabilities, dealing with intricate queries past easy level lookups or relational operations.
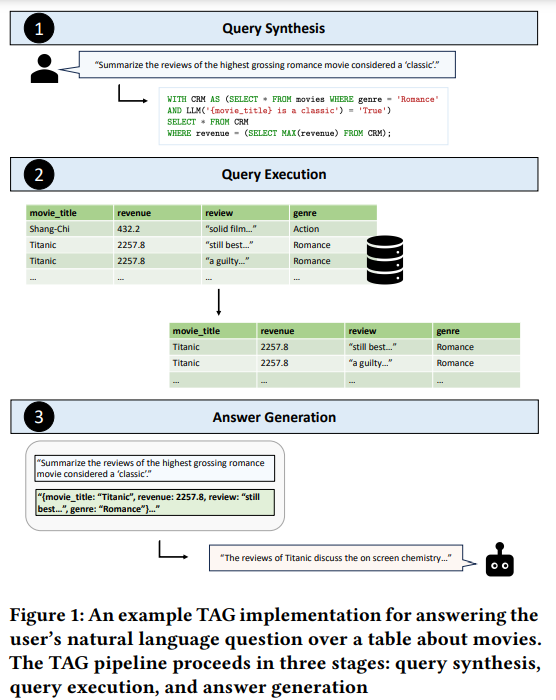
UC Berkeley and Stanford College researchers suggest Desk-Augmented Era (TAG), a brand new paradigm for answering pure language questions over databases. TAG introduces a unified method involving three steps: translating the person’s question into an executable database question (question synthesis), working this question to retrieve related information (question execution), and utilizing this information together with the question to generate a pure language reply (reply era). Not like Text2SQL and RAG, that are restricted to particular circumstances, TAG addresses a broader vary of queries. Preliminary benchmarks present that current strategies obtain lower than 20% accuracy, whereas TAG implementations can enhance efficiency by 20-65%, highlighting its potential.
Text2SQL analysis, together with datasets like WikiSQL, Spider, and BIRD, focuses on changing pure language queries into SQL however doesn’t handle queries requiring further reasoning or data. RAG enhances language fashions by leveraging exterior textual content collections, with fashions like dense desk retrieval (DTR) and join-aware desk retrieval extending RAG to tabular information. Nonetheless, TAG expands past these strategies by integrating language mannequin capabilities into question execution and database operations for actual computations. Prior analysis on semi-structured information and agentic information assistants explores associated ideas, however TAG goals to leverage a broader vary of language mannequin capabilities for various question sorts.
The TAG mannequin solutions pure language queries by following three fundamental steps: question synthesis, question execution, and reply era. First, it interprets the person’s question right into a database question (question synthesis). Then, it executes this question to retrieve related information from the database (question execution). Lastly, it makes use of the retrieved information and the unique question to generate a pure language reply (reply era). TAG extends past conventional strategies like Text2SQL and RAG by incorporating complicated reasoning and data integration. It helps numerous question sorts, information fashions, and execution engines and explores iterative and recursive era patterns for enhanced question answering.
In evaluating the TAG mannequin, a benchmark was created utilizing modified queries from the BIRD dataset to check semantic reasoning and world data. The benchmark included 80 queries, break up evenly between these requiring world data and reasoning. The hand-written TAG mannequin persistently outperformed different strategies, reaching as much as 55% accuracy general and demonstrating superior efficiency on comparability queries. Different baselines, together with Text2SQL, RAG, and Retrieval + LM Rank, struggled, particularly with reasoning queries, displaying decrease accuracy and better execution instances. The hand-written TAG mannequin additionally achieved the quickest execution time and offered thorough solutions, significantly in aggregation queries.
In conclusion, The TAG mannequin was launched as a unified method for answering pure language questions utilizing databases. Benchmarks have been developed to evaluate queries requiring world data and semantic reasoning, revealing that current strategies like Text2SQL and RAG fall quick, reaching lower than 20% accuracy. In distinction, hand-written TAG pipelines demonstrated as much as 65% accuracy, highlighting the potential for important developments in integrating LMs with information administration methods. TAG presents a broader scope for dealing with various queries, underscoring the necessity for additional analysis to discover its capabilities and enhance efficiency totally.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Here’s a extremely really useful webinar from our sponsor: ‘Constructing Performant AI Functions with NVIDIA NIMs and Haystack’
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]