[ad_1]
Advances in vision-language fashions (VLMs) have proven spectacular widespread sense, reasoning, and generalization talents. Which means creating a completely impartial digital AI assistant, that may carry out day by day pc duties via pure language is feasible. Nevertheless, higher reasoning and commonsense talents don’t mechanically result in clever assistant habits. AI assistants are used to finish duties, behave rationally, and get better from errors, not simply present believable responses primarily based on pre-training information. So, a technique is required to show pre-training talents into sensible AI “brokers.” Even the perfect VLMs, like GPT-4V and Gemini 1.5 Professional, nonetheless battle to carry out the correct actions when finishing machine duties.
This paper discusses three present strategies. The primary technique is coaching multi-modal digital brokers, which face challenges like machine management being accomplished instantly on the pixel degree in a coordinate-based motion house, and the stochastic and unpredictable nature of machine ecosystems and the web. The second technique is Environments for machine management brokers. These environments are designed for analysis, and supply a restricted vary of duties in absolutely deterministic and stationary settings. The final technique is Reinforcement studying (RL) for LLM/VLMs, the place analysis with RL for basis fashions focuses on single-turn duties like choice optimization, however optimizing for single-turn interplay from knowledgeable demonstrations can result in sub-optimal methods for multi-step issues.
Researchers from UC Berkeley, UIUC, and Google DeepMind have launched DigiRL (RL for Digital Brokers), a novel autonomous RL technique for coaching machine management brokers. The ensuing agent attains state-of-the-art efficiency on a number of Android device-control duties. The coaching course of entails two phases: first, an preliminary offline RL part to initialize the agent utilizing present information, adopted by an offline-to-online RL part, that’s used for fine-tuning the mannequin obtained from offline RL on on-line information. To coach on-line RL a scalable and parallelizable Android studying atmosphere was developed that features a strong general-purpose evaluator (common error price 2.8% towards human judgment) primarily based on VLM.
Researchers carried out experiments to guage the efficiency of DigiRL on difficult Android machine management issues. It is very important perceive if DigiRL has the potential to provide brokers that may be taught successfully via autonomous interplay, whereas nonetheless with the ability to make the most of offline information for studying. So, a comparative evaluation was carried out on DigiRL towards the next:
- State-of-the-art brokers constructed round proprietary VLMs utilizing a number of prompting and retrieval-style methods.
- Operating imitation studying on static human demonstrations with the identical instruction distribution
- A filtered Habits Cloning strategy.
An agent educated utilizing DigiRL was examined on varied duties from the Android within the Wild dataset (AitW) with actual Android machine emulators. The agent achieved a 28.7% enchancment over the prevailing state-of-the-art brokers (elevating the success price from 38.5% to 67.2%) 18B CogAgent. It additionally outperformed the earlier high autonomous studying technique primarily based on Filtered Habits Cloning by greater than 9%. Furthermore, regardless of having just one.3B parameters, the agent carried out higher than superior fashions like GPT-4V and Gemini 1.5 Professional (17.7% success price). This makes it the primary agent to attain state-of-the-art efficiency in machine management utilizing an autonomous offline-to-online RL strategy.
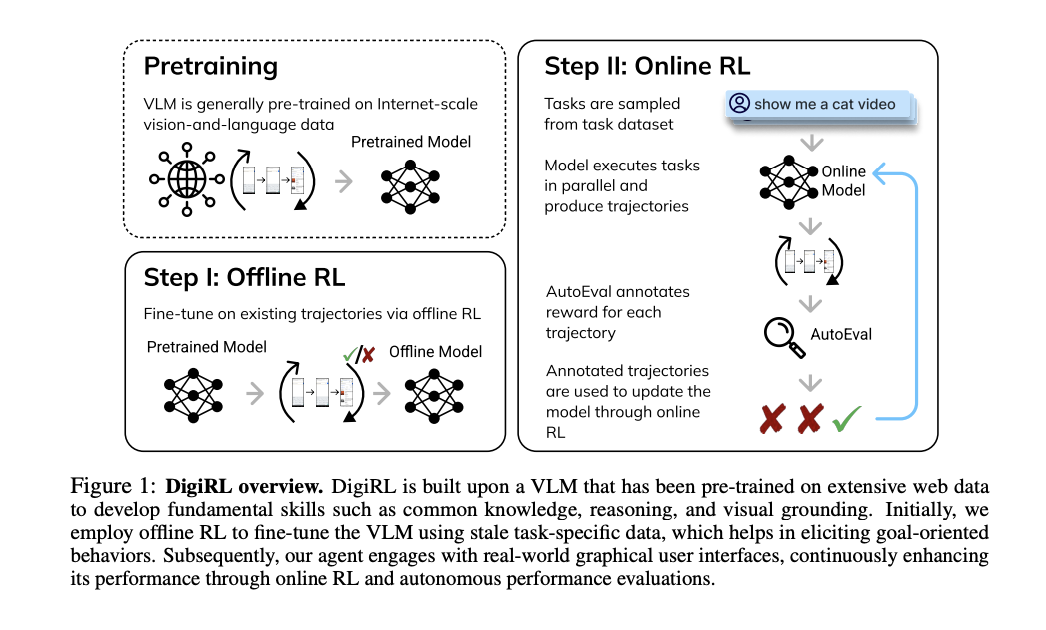
In abstract, researchers proposed DigiRL, a novel autonomous RL strategy for coaching device-control brokers that units a brand new state-of-the-art efficiency on a number of Android management duties from AitW. A scalable and parallelizable Android atmosphere was developed to attain this with a sturdy VLM-based general-purpose evaluator for fast on-line information assortment. The agent educated on DigiRL achieved a 28.7% enchancment over the prevailing state-of-the-art brokers 18B CogAgent. Nevertheless, the coaching was restricted to duties from the AitW dataset as an alternative of all attainable machine duties. So, future work consists of constructing algorithmic analysis and increasing the duty house, making DigiRL the bottom algorithm.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 45k+ ML SubReddit

Sajjad Ansari is a remaining 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.
[ad_2]