[ad_1]
Introduction
At present, producers’ subject upkeep is commonly extra reactive than proactive, which may result in expensive downtime and repairs. Traditionally, knowledge warehouses have supplied a performant, extremely structured lens into historic reporting however have left customers wanting for efficient predictive options. Nevertheless, the Databricks Information Intelligence Platform permits companies to implement each historic and predictive evaluation on the identical copy of their knowledge. Producers can leverage predictive upkeep options to establish and tackle potential points earlier than they change into enterprise essential buyer dealing with issues. Databricks supplies end-to-end machine studying options together with instruments for knowledge preparation, mannequin coaching, and root trigger evaluation reporting. This weblog goals to make clear methods to implement predictive options for IoT anomaly detection with a unified and scalable strategy.
Drawback Assertion
Scaling present codebases and talent units is a key theme in growing IoT predictive upkeep options given the huge knowledge volumes concerned. We regularly see companies expertise a rise in defect charges and not using a clear clarification. Whereas there could already be a workforce of information scientists who’re expert in utilizing Pandas for knowledge manipulation and evaluation on small subsets of their knowledge – for instance, analyzing significantly notable journeys one after the other – these groups can simply apply their present code to their whole large-scale IoT dataset by utilizing Databricks. Within the examples beneath, we’ll spotlight methods to deploy Pandas code in an simply distributable manner, with out knowledge scientists having to be taught a totally new set of instruments and applied sciences to develop and preserve the answer. Moreover, ML experimentation usually runs in silos, with knowledge scientists working domestically and manually on their very own machines on completely different copies of information. This will result in a scarcity of reproducibility and collaboration, making it tough to run ML efforts throughout a corporation. Databricks addresses this problem by enabling MLflow, an open-source software for unified machine studying mannequin experimentation, registry, and deployment. With MLflow, knowledge scientists can simply observe and reproduce their experiments, in addition to deploy their fashions into manufacturing.
Instance 1: Operating Present Anomaly Detection Code on Databricks
For example methods to use Databricks for IoT anomaly detection, let’s contemplate a dataset of sensor knowledge from a fleet of engines. The dataset contains sensor readings similar to temperature, stress, and oil density, in addition to a label indicating whether or not or not every knowledge level signaled a defect. For this instance, we’ll take the prevailing code that runs on a subset of our knowledge. Our intention is emigrate some present, single node code which we’ll ultimately run in parallel throughout a Spark cluster. Even earlier than we scale our code, we get the advantages of a collaborative interface that allows tooling similar to in-notebook dashboarding for exploratory evaluation, and Databricks Assistant for code writing and troubleshooting.
On this instance, we copy Pandas code right into a Databricks pocket book with one easy addition for studying the desk from our group’s unified knowledge lake, and instantly get some extent and click on interface for exploring our knowledge:
import pandas as pd
pandas_bronze = spark.learn.desk('sensor_bronze_table').toPandas()
encoded_factory = pd.get_dummies(pandas_bronze['factory_id'], prefix='ohe')
pandas_bronze.drop('factory_id', axis=1)
options = pd.concat(encoded_factory, axis=1)
options['rolling_mean_density'] = options[density].shift(1).ewm(5).imply()
options = options.fillna(methodology='ffill')
show(options)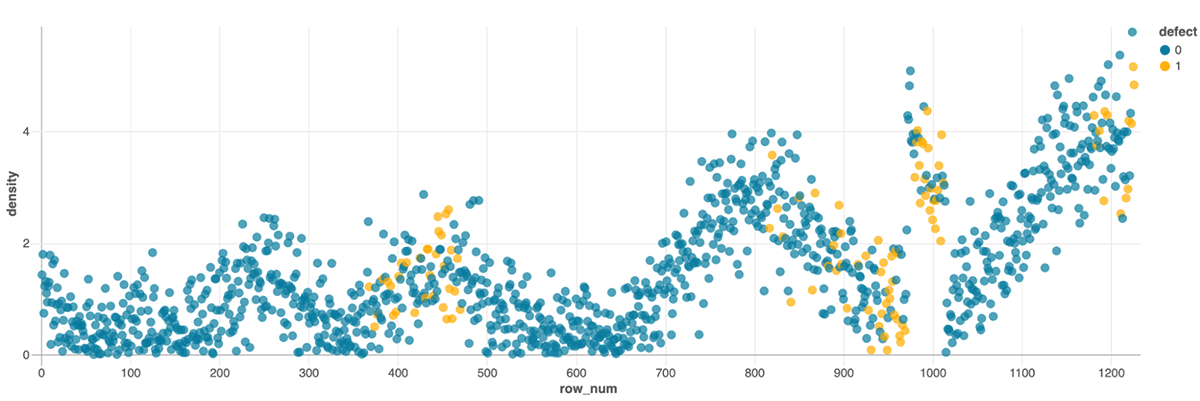
Instance 2: MLops for Manufacturing
Subsequent, we’ll use Databricks and MLflow to simply observe and reproduce your experiments, permitting you to iterate and enhance in your mannequin over time. Our purpose is to construct a machine studying mannequin that may precisely predict whether or not a given knowledge level is a defect based mostly on the sensor readings, with out having to duplicate knowledge and fashions throughout completely different groups, roles, or techniques. By including a easy autolog() perform, you may robotically observe details about every try to resolve an ML drawback similar to mannequin artifacts, library dependencies, mannequin parameters, and efficiency metrics. We will use these fashions to assist establish and tackle engine defects earlier than they change into a serious situation, in batch or actual time pipelines.
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.linear_model import LogisticRegression
model_name = f"lr_{config['model_name']}"
mlflow.sklearn.autolog() # Autolog creates the run and provides the vital info for us
# Outline mannequin, match it, and create predictions. Defer logging to autolog()
lr = LogisticRegression()
lr.match(X_train_oversampled, y_train_oversampled)
predictions = lr.predict(X_test)
# Downstream pipelines can now simply use the mannequin
feature_data = spark.learn.desk(config['silver_features']).toPandas()
model_uri = f'fashions:/{config["model_name"]}/Manufacturing'
production_model = mlflow.pyfunc.load_model(model_uri)
feature_data['predictions'] = production_model.predict(feature_data)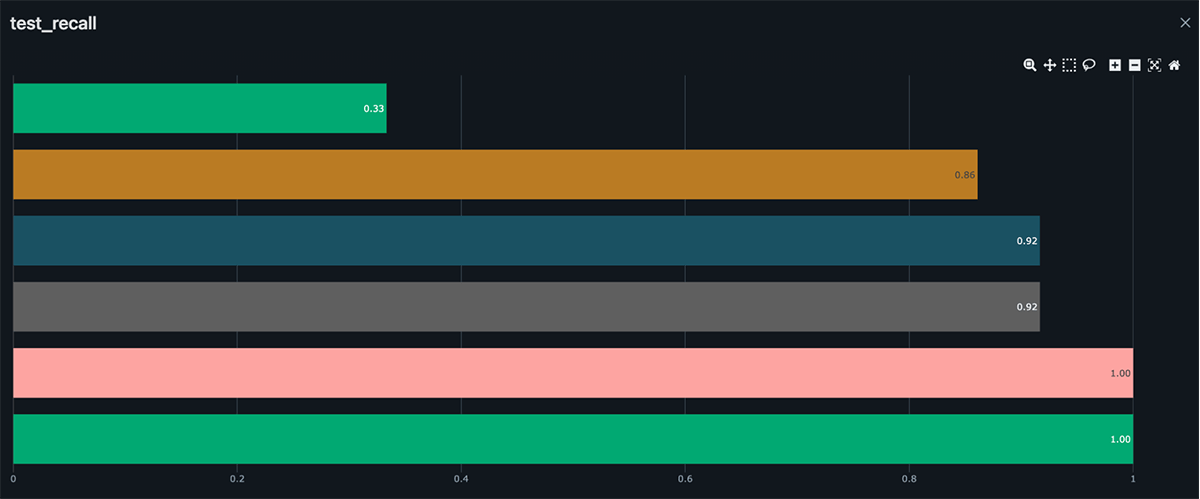
Instance 3: Distributing Pandas on Spark
Now that we’ve ported our present code to Databricks and enhanced the monitoring, reproducibility, and operationalization of our ML fashions, we need to scale them throughout our whole dataset. You possibly can’t beat the efficiency of Apache Spark for distributed computing, however knowledge scientists usually don’t need to be taught one other framework or alter the code they’ve already developed. Happily, Spark provides numerous approaches to horizontally scaling Pandas workloads to run throughout your whole dataset. We’ll discover three completely different choices beneath:
a. PySpark Pandas
On this instance, we’ll use PySpark Pandas to make use of the identical code for constructing options from Instance 1, however this time it is going to run in parallel throughout many nodes on a Spark cluster. Your code can use this parallelization to effectively scale with large datasets, with out rewriting the logic. Observe that the code is equivalent to Instance 1 aside from the pandas import assertion and utilizing pandas_api() as a substitute of toPandas() to outline the DataFrame.
import pyspark.pandas as ps
features_ps = spark.learn.desk('sensor_bronze_table').orderBy('timestamp').pandas_api()
encoded_factory = ps.get_dummies(features_ps['factory_id'], prefix='ohe')
features_ps = features_ps.drop('factory_id', axis=1)
features_ps = ps.concat([features_ps, encoded_factory], axis=1)b. Pandas UDFs
PySpark Pandas doesn’t cowl each use case for Pandas – at instances, you’ll want extra granular management over your operations or use a library that doesn’t have a PySpark implementation. We will use Pandas UDFs for these circumstances. A Pandas UDF permits us to create a perform that accepts a well-recognized object, on this case a Pandas Collection, and function on it as we might domestically. At execution time, nonetheless, this code will run in parallel throughout the Spark cluster. The one code change we have to make is to embellish our perform with @pandas_udf. On this instance, we’ll use an ARIMA mannequin to make temperature forecasts in parallel so as to add a function with larger predictive worth to our dataset.
from pyspark.sql.features import pandas_udf
from statsmodels.tsa.arima.mannequin import ARIMA
@pandas_udf("double")
def forecast_arima(temperature: pd.Collection) -> pd.Collection:
mannequin = ARIMA(temperature, order=(1, 2, 4))
model_fit = mannequin.match()
return model_fit.predict()
# Minimal Spark code - simply cross one column and add one other. We nonetheless use Pandas for our logic
features_temp = features_ps.to_spark().withColumn('predicted_temp', forecast_arima('temperature'))c. applyInPandas
Rounding off our approaches to parallelizing Pandas code is applyInPandas. Just like the Pandas UDFs strategy in Instance 3b, applyInPandas lets you write a perform that accepts a well-recognized object (a whole Pandas DataFrame) and takes care of distributing the execution of the code throughout the Spark cluster. On this strategy, nonetheless, we begin by grouping by some key (within the instance beneath, device_id). The grouping key will decide which knowledge is processed collectively, for instance all the information the place device_id is the same as 1 will get grouped into one Pandas DataFrame, device_id equal to 2 is grouped into one other Pandas DataFrame, and so forth. This enables us to take code that beforehand ran on one system at a time and scale that out throughout a whole cluster, which considerably accelerates the processing of information at scale. We additionally present the anticipated output schema of our applyInPandas perform in order that Spark can leverage PyArrow to serialize the ends in an environment friendly manner. On this easy instance, we’ll take an exponentially weighted transferring common for every system’s gasoline density and ahead fill any null values:
def add_rolling_density(pdf: pd.DataFrame) -> pd.DataFrame:
pdf['rolling_mean_density'] = pdf['density'].shift(1).ewm(span=600).imply()
pdf = pdf.fillna(methodology='ffill').fillna(0)
return pdf
rolling_density_schema = ‘device_id string, trip_id int, airflow_rate double, density double’
features_density = features_temp.groupBy('device_id').applyInPandas(add_rolling_density, rolling_density_schema)Conclusion
In conclusion, utilizing Databricks for IoT predictive upkeep provides an a variety of benefits, together with the power to simply scale ML workloads, collaborate throughout groups, and deploy fashions into manufacturing. Through the use of Databricks, knowledge scientists can apply their present Pandas expertise and code to work with large-scale IoT knowledge, with out having to be taught a totally new set of applied sciences. This enables them to rapidly construct and deploy IoT anomaly detection fashions, serving to to establish and tackle engine defects earlier than they change into a serious situation. In brief, Databricks supplies a strong and versatile platform for knowledge scientists to use their present Pandas expertise to large-scale IoT knowledge. When you’re an information scientist or knowledge science chief trying to scale your knowledge and AI workloads, attempt our Distributed ML for IoT resolution accelerator and enhance the effectiveness of your predictive upkeep initiatives.
Right here is the hyperlink to this resolution accelerator.
[ad_2]