[ad_1]

Fast-paced knowledge and actual time evaluation current us with some superb alternatives. Don’t blink—otherwise you’ll miss it! Each group has some knowledge that occurs in actual time, whether or not it’s understanding what our customers are doing on our web sites or watching our programs and tools as they carry out mission important duties for us. This real-time knowledge, when captured and analyzed in a well timed method, might ship great enterprise worth. For instance:
- In manufacturing, fast-moving knowledge offers the one approach to detect—and even predict and forestall—defects in actual time earlier than they propagate throughout a whole manufacturing cycle. This may scale back defect charges, rising product yield. We will additionally improve effectiveness of preventative upkeep—or transfer to predictive upkeep—of kit, decreasing the price of downtime with out losing any worth from wholesome tools.
- In telecommunications, fast-moving knowledge is crucial once we’re seeking to optimize the community, bettering high quality, consumer satisfaction, and total effectivity. With this, we are able to scale back buyer churn and total community operational prices.
- In monetary companies, fast-moving knowledge is important for real-time danger and risk assessments. We will transfer to predictive fraud and breach prevention, vastly rising the safety of buyer knowledge and monetary property. With out real-time analytics we received’t catch the threats till after they’ve precipitated important injury. We will additionally profit from real-time inventory ticker analytics, and different extremely monetizable knowledge property.
By capitalizing on the enterprise worth of fast-moving and real-time analytics, we are able to do some recreation altering issues. We will scale back prices, remove pointless work, enhance buyer satisfaction and expertise, and scale back churn. We will get to sooner root-cause evaluation and turn out to be proactive as an alternative of reactive to adjustments in markets, enterprise operations, and buyer habits. We will get the leap on competitors, scale back surprises that trigger disruption, have higher organizational operational well being, and scale back pointless waste and price in all places.
The necessity for real-time choice assist and automation is evident.
Nevertheless, there are some key capabilities that may make real-time analytics a sensible and utilized actuality. What we’d like is:
- An openness to assist a variety in streaming ingest sources, together with NiFi, Spark Streaming, Flink, in addition to APIs for languages like C++, Java, and Python.
- The power to assist not simply “insert” sort knowledge adjustments, however Insert+replace patterns as nicely, to accommodate each new knowledge, and altering knowledge.
- Flexibility for various use circumstances. Completely different knowledge streams could have totally different traits, and having a platform versatile sufficient to adapt, with issues like versatile partitioning for instance, will probably be important in adapting to totally different supply quantity traits.
On high of those core important capabilities, we additionally want the next:
- Petabyte and bigger scalability—significantly useful in predictive analytics use circumstances the place excessive granularity and deep histories are important to coaching AI fashions to higher precision.
- Versatile use of compute assets on analytics—which is much more essential as we begin performing a number of various kinds of analytics, some important to every day operations and a few extra exploratory and experimental in nature, and we don’t wish to have useful resource calls for collide.
- Skill to deal with complicated analytic queries—particularly once we’re utilizing real-time analytics to reinforce present enterprise dashboards and stories with massive, complicated, long-running enterprise intelligence queries typical for these use circumstances, and never having the real-time dimension sluggish these down in any means.
And all of this could ideally be delivered in a straightforward to deploy and administer knowledge platform out there to work in any cloud.
A novel structure to optimize for real-time knowledge warehousing and enterprise analytics:
Cloudera Knowledge Platform (CDP) provides Apache Kudu as a part of our Knowledge Hub cloud service, offering a constant, reliable approach to assist the ingestion of information streams into our analytics atmosphere, in actual time, and at any scale. CDP additionally provides the Cloudera Knowledge Warehouse (CDW) as a containerized service with the flexibleness to scale up and down as wanted, and a number of CDW situations might be configured towards the identical knowledge to offer totally different configurations and scaling choices to optimize for workload efficiency and price. This additionally achieves workload isolation, so we are able to run mission important workloads impartial from experimental and exploratory ones and no person steps on anybody’s toes accidentally.
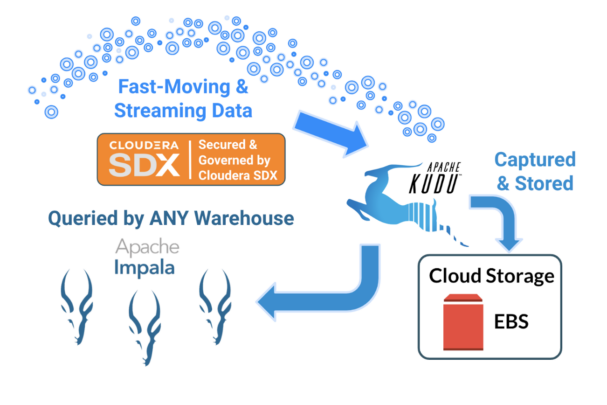
Fig. 1: Kudu & Impala for Actual-Time Knowledge Warehousing
Key options of Apache Kudu embrace:
Assist for Apache NiFi, Spark Streaming, and Flink pre-integrated and out of the field. Kudu additionally has native assist for C++, Java, and Python APIs for capturing knowledge streams from functions and parts based mostly on these languages. With such a variety of ingest sorts, Kudu can get something you want from any real-time knowledge supply.
- Full assist for insert and Insert+replace syntax for very versatile knowledge stream dealing with. Having the ability to seize not simply new knowledge, but additionally modified knowledge, vastly facilitates Change Knowledge Seize (CDC) use circumstances in addition to some other use case involving knowledge that will change over time, and never at all times be additive.
- Skill to make use of a number of totally different versatile partitioning schemes to accommodate any real-time knowledge, no matter every stream’s explicit traits. Ensuring knowledge is ready to land in actual time and be accessed simply as quick requires a “greatest match” partitioning scheme. Kudu has this coated.
Key options of Cloudera Knowledge Warehouse embrace:
- Highly effective Apache Impala question engine able to dealing with large scale knowledge units and sophisticated, lengthy operating enterprise knowledge warehouse (EDW) queries, to assist conventional dashboards and stories, augmented by real-time knowledge.
- Containerized service to run each a number of compute clusters towards the identical knowledge, and to configure every cluster with its personal distinctive traits (occasion sorts, preliminary and progress sizing parameters, and workload conscious auto scaling capabilities).
- Full lifecycle assist together with Cloudera Knowledge Engineering (CDE) for knowledge preparation, Cloudera Knowledge Movement (CDF) for streaming knowledge administration, and Cloudera Machine Studying (CML) for simple inclusion of information science and machine studying within the analytics. That is particularly needed when combining real-time knowledge with ready knowledge, and including predictive ideas into our augmented dashboards and stories.
CDW integrates Kudu in Knowledge Hub companies with containerized Impala to supply straightforward to deploy and administer, versatile real-time analytics. With this distinctive structure, we assist secure and constant ingestion of big volumes of fast paced knowledge, harder with versatile, workload-isolated knowledge warehousing companies. We get optimized value/efficiency on complicated workloads over large scale knowledge.
Able to cease blinking and by no means miss a beat?
Let’s take a detailed take a look at learn how to get began with CDP, Kudu, CDW, and Impala and develop a recreation altering real-time analytics platform.
Take a look at our current weblog on integrating Apache Kudu on Cloudera Knowledge Hub and Apache Impala on Cloudera Knowledge Warehouse to discover ways to implement this in your Cloudera Knowledge Platform atmosphere.
[ad_2]