[ad_1]
Introduction
Polars is a high-performance DataFrame library designed for velocity and effectivity. It leverages all accessible cores in your machine, optimizes queries to reduce pointless operations, and manages datasets bigger than your RAM. With a constant API and strict schema adherence, Python Polars ensures predictability and reliability. Written in Rust, it presents C/C++ stage efficiency, totally controlling vital elements of the question engine for optimum outcomes.
Overview:
- Find out about Polars, a high-performance DataFrame library in Rust.
- Uncover Apache Arrow, which Polars leverages for quick information entry and manipulation.
- Polars helps deferred, optimized operations and quick outcomes, providing versatile question execution.
- Uncover the streaming capabilities of Polars, particularly its potential to deal with massive datasets in chunks.
- Perceive Polars strict schemas to make sure information integrity and predictability, minimizing runtime errors.

Key Ideas of Polars
- Apache Arrow Format: Polars makes use of Apache Arrow, an environment friendly columnar reminiscence format, to allow quick information entry and manipulation. This ensures excessive efficiency and seamless interoperability with different Arrow-based programs.
- Lazy vs Keen Execution: It helps lazy execution, deferring operations for optimization, and keen execution, performing operations instantly. Lazy execution optimizes computations, whereas keen execution offers immediate outcomes.
- Streaming: Polars can deal with streaming information and processing massive datasets in chunks. This reduces reminiscence utilization and is good for real-time information evaluation.
- Contexts: Polars contexts outline the scope of knowledge operations, offering construction and consistency in information processing workflows. The first contexts are choice, filtering, and aggregation.
- Expressions: Expressions in Polars symbolize information operations like arithmetic, aggregations, and filtering. They permit for the environment friendly constructing of complicated information processing and its pipelines.
- Strict Schema Adherence: It enforces a strict schema, requiring identified information sorts earlier than executing queries. This ensures information integrity and reduces runtime errors.
Additionally Learn: Is Pypolars the New Different to Pandas?
Python Polars Expressions
Set up Polars with ‘pip set up polars.’
We are able to learn the info and describe it like in Pandas
df = pl.read_csv('iris.csv')
df.head() # it will show form, datatypes of the columns and first 5 rows
df.describe() # it will show primary descriptive statistics of columnsSubsequent up we will choose completely different columns with primary operations.
df.choose(pl.sum('sepal_length').alias('sum_sepal_length'),
pl.imply('sepal_width').alias('mean_sepal_width'),
pl.max('species').alias('max_species'))
# retuens an information body with given column names and operations carried out on them.We are able to additionally choose utilizing polars.selectors
import polars.selectors as cs
df.choose(cs.float()) # returns all columns with float information sorts
# we will additionally search with sub-strings or regex
df.choose(cs.comprises('width')) # returns the columns which have 'width' within the title.Now we will use conditionals.
df.choose(pl.col('sepal_width'),
pl.when(pl.col("sepal_width") > 2)
.then(pl.lit(True))
.in any other case(pl.lit(False))
.alias("conditional"))
# This returns a further column with boolean values with true when sepal_width > 2Patterns within the strings will be checked, extracted, or changed.
df_1 = pl.DataFrame({"id": [1, 2], "textual content": ["123abc", "abc456"]})
df_1.with_columns(
pl.col("textual content").str.exchange(r"abcb", "ABC"),
pl.col("textual content").str.replace_all("a", "-", literal=True).alias("text_replace_all"),
)
# exchange one match of abc on the finish of a phrase (b) with ABC and all occurrences of a with -Filtering columns
df.filter(pl.col('species') == 'setosa',
pl.col('sepal_width') > 2)
# returns information with solely setosa species and the place sepal_width > 2Groupby on this high-performance dataframe library in Rust.
df.group_by('species').agg(pl.len(),
pl.imply('petal_width'),
pl.sum('petal_length'))
The above returns the variety of values by species and the imply of petal_width, the sum of petal_length by species.
Joins
Along with typical interior, outer, and left joins, polars have ‘semi’ and ‘anti.’ Let’s take a look at the ‘semi’ be a part of.
df_cars = pl.DataFrame(
{
"id": ["a", "b", "c"],
"make": ["ford", "toyota", "bmw"],
}
)
df_repairs = pl.DataFrame(
{
"id": ["c", "c"],
"value": [100, 200],
}
)
# now an interior be a part of produces with a number of rows for every automotive that has had a number of restore jobs
df_cars.be a part of(df_repairs, on="id", how="semi")
# this produces a single row for every automotive that has had a restore job carried outThe ‘anti’ be a part of produces a DataFrame displaying all of the automobiles from df_cars for which the ID is just not current within the df_repairs DataFrame.
We are able to concat dataframes with easy syntax.
df_horizontal_concat = pl.concat(
[
df_h1,
df_h2,
],
how="horizontal",
) # this returns wider dataframe
df_horizontal_concat = pl.concat(
[
df_h1,
df_h2,
],
how="vertical",
) # this returns longer dataframeLazy API
The above examples present that the keen API executes the question instantly. The lazy API, however, evaluates the question after making use of varied optimizations, making the lazy API the popular choice.
Let’s take a look at an instance.
q = (
pl.scan_csv("iris.csv")
.filter(pl.col("sepal_length") > 5)
.group_by("species")
.agg(pl.col("sepal_width").imply())
)
# how question graph with out optimization - set up graphviz
q.show_graph(optimized=False)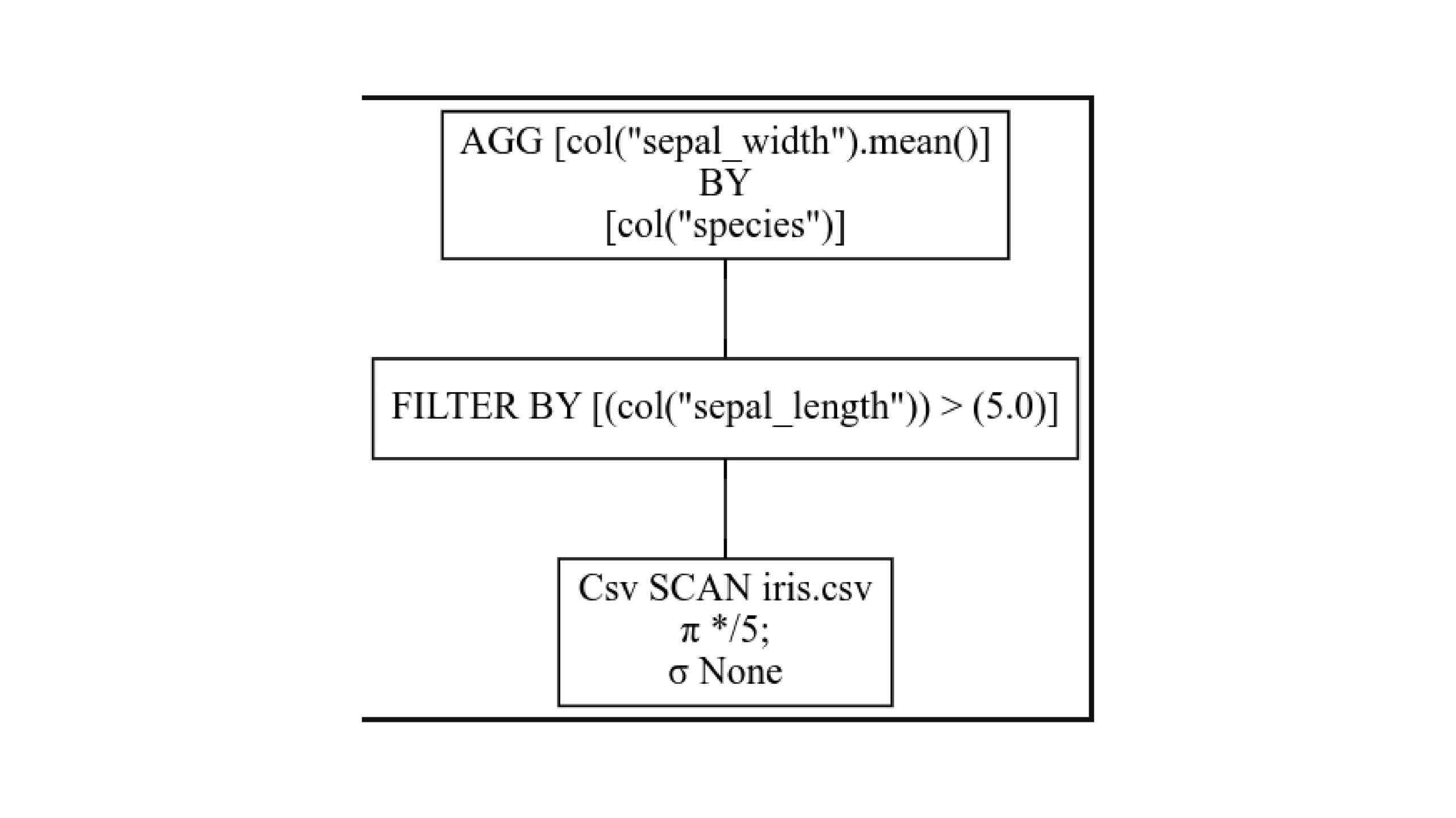
Learn from backside to prime. Every field is one stage within the question plan. Sigma stands for SELECTION and signifies choice primarily based on filter circumstances. Pi stands for PROJECTION and signifies selecting a subset of columns.
Right here, we select all 5 columns, and no alternatives are made whereas studying the CSV file. Then, we filter by the column and combination one after one other.
Now, take a look at the optimized question plan with q.show_graph(optimized=True)
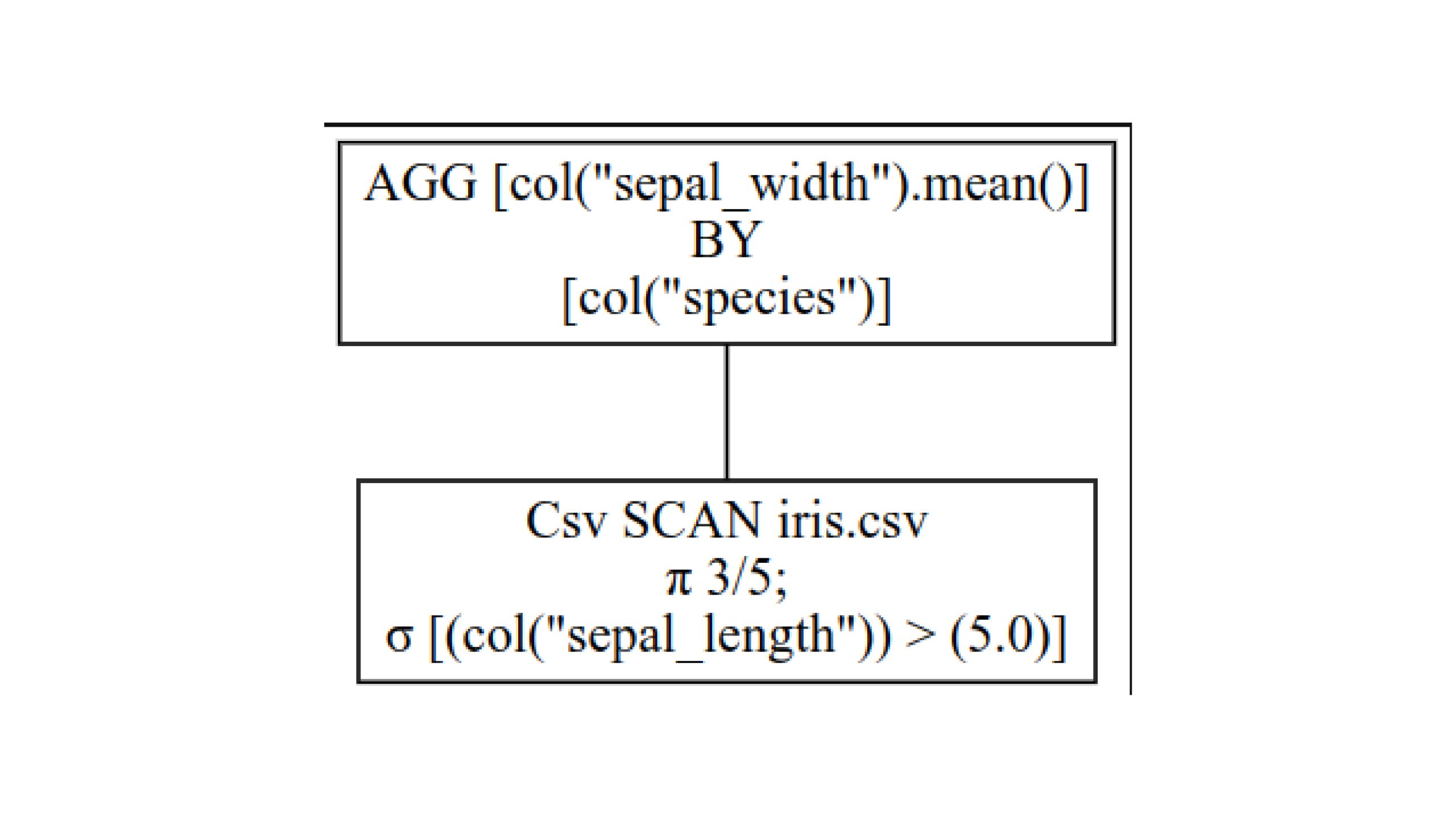
Right here, we select solely 3 out of 5 columns, as subsequent queries are completed on solely them. Even in them, we choose information primarily based on the filter situation. We’re not loading another information. Now, we will combination the chosen information. Thus, this methodology is far quicker and requires much less reminiscence.
We are able to gather the outcomes now. We are able to course of the info in batches if the entire dataset doesn’t match within the reminiscence.
q.gather()
# to course of in batches
q.gather(streaming=True)Polars is rising in reputation, and lots of libraries like scikit-learn, seaborn, plotly, and others assist Polars.
Conclusion
Polars presents a sturdy, high-performance DataFrame library for velocity, effectivity, and scalability. With options like Apache Arrow integration, lazy and keen execution, streaming information processing, and strict schema adherence, Polars stands out as a flexible device for information professionals. Its constant API and use of Rust guarantee optimum efficiency, making it a necessary device in fashionable information evaluation workflows.
Steadily Requested Questions
A. Polars is a high-performance DataFrame library designed for velocity and effectivity. In contrast to Pandas, Polars leverages all accessible cores in your machine, optimizes queries to reduce pointless operations, and may handle datasets bigger than your RAM. Moreover, this high-performance dataframe is written in Rust, providing C/C++ stage efficiency.
A. Polars makes use of Apache Arrow, an environment friendly columnar reminiscence format, which permits quick information entry and manipulation. This integration ensures excessive efficiency and seamless interoperability with different Arrow-based programs, making it perfect for dealing with massive datasets effectively.
A. Lazy execution in Polars defers operations for optimization, permitting the system to optimize your complete question plan earlier than executing it, which might result in vital efficiency enhancements. Keen execution, however, performs operations instantly, offering immediate outcomes however with out the identical stage of optimization.
A. Polars can course of massive datasets in chunks by means of their streaming capabilities. This strategy reduces reminiscence utilization and is good for real-time information evaluation, enabling the high-performance dataframe to effectively deal with information that exceeds the accessible RAM.
A. Polars requires strict schema adherence, which requires figuring out information sorts earlier than executing queries. This ensures information integrity, reduces runtime errors, and permits for extra predictable and dependable information processing, making it a sturdy selection for information evaluation.
[ad_2]