[ad_1]
Transformer-based LLMs like ChatGPT and LLaMA excel in duties requiring area experience and sophisticated reasoning resulting from their massive parameter sizes and in depth coaching knowledge. Nevertheless, their substantial computational and storage calls for restrict broader functions. Quantization addresses these challenges by changing 32-bit parameters to smaller bit sizes, enhancing storage effectivity and computational pace. Excessive quantization, or binarization, maximizes effectivity however reduces accuracy. Whereas methods like retaining key parameters or near-one-bit illustration supply enhancements, they nonetheless need assistance with points like data loss, ample coaching knowledge, and restricted flexibility in adapting to totally different parameter scales and vocabularies.
Researchers from Mohamed bin Zayed College of AI and Carnegie Mellon College introduce Totally Binarized Massive Language Fashions (FBI-LLM), coaching large-scale binary language fashions from scratch to match the efficiency of full-precision counterparts. Utilizing autoregressive distillation (AD) loss, they preserve equal mannequin dimensions and coaching knowledge, reaching aggressive perplexity and task-specific outcomes. Their coaching process distills from a full-precision instructor, permitting steady coaching from random initializations. Empirical evaluations on fashions starting from 130M to 7B parameters show minimal efficiency gaps in comparison with full-precision fashions, highlighting the potential for specialised {hardware} and new computational frameworks.
Neural community binarization converts mannequin parameters to a 1-bit format, considerably enhancing effectivity and lowering storage, however typically at the price of accuracy. Methods like BinaryConnect and Binarized Neural Networks (BNN) use stochastic strategies and clipping capabilities to coach binary fashions. Additional developments like XNOR-Web and DoReFa-Web introduce scaling components and techniques to reduce quantization errors. In massive language fashions, partial binarization strategies like PB-LLM and BiLLM preserve key parameters at full precision, whereas BitNet b1.58 makes use of a set of {-1, 0, 1} for parameters. Current approaches like BitNet and OneBit make use of quantization-aware coaching for higher efficiency.
FBI-LLM modifies transformer-based LLMs by changing all linear modules, besides the causal head, with FBI-linear and conserving embedding and layer norm modules at full precision to keep up semantic info and activation scaling. FBI-linear binarizes full-precision parameters utilizing the signal perform and applies full-precision scaling components to columns, initialized based mostly on column averages, to cut back errors and preserve efficiency. For coaching, FBI-LLM employs autoregressive distillation, utilizing a full-precision instructor mannequin to information a binarized pupil mannequin through cross-entropy loss between their outputs. The Straight-By means of Estimator (STE) permits gradient propagation by the non-differentiable signal perform, guaranteeing efficient optimization.
Within the experiments, the researchers applied the FBI-LLM methodology following a W1A16 configuration, which quantizes mannequin parameters to 1-bit whereas retaining activation values at 16-bit precision. They skilled FBI-LLMs of various sizes—130M, 1.3B, and 7B—utilizing the Amber dataset, a big corpus comprising 1.26 trillion tokens from numerous sources. The coaching utilized an Adam optimizer with particular settings and employed autoregressive distillation with LLaMA2-7B because the instructor mannequin. Analysis throughout duties like BoolQ, PIQA, and Winogrande confirmed FBI-LLMs reaching aggressive zero-shot accuracy and perplexity metrics, surpassing comparable binarized and full-precision fashions in a number of cases. Storage effectivity evaluation demonstrated substantial compression advantages in comparison with full-precision LLMs, whereas technology checks illustrated FBI-LLMs’ capability for fluent and knowledgeable content material creation throughout totally different prompts.
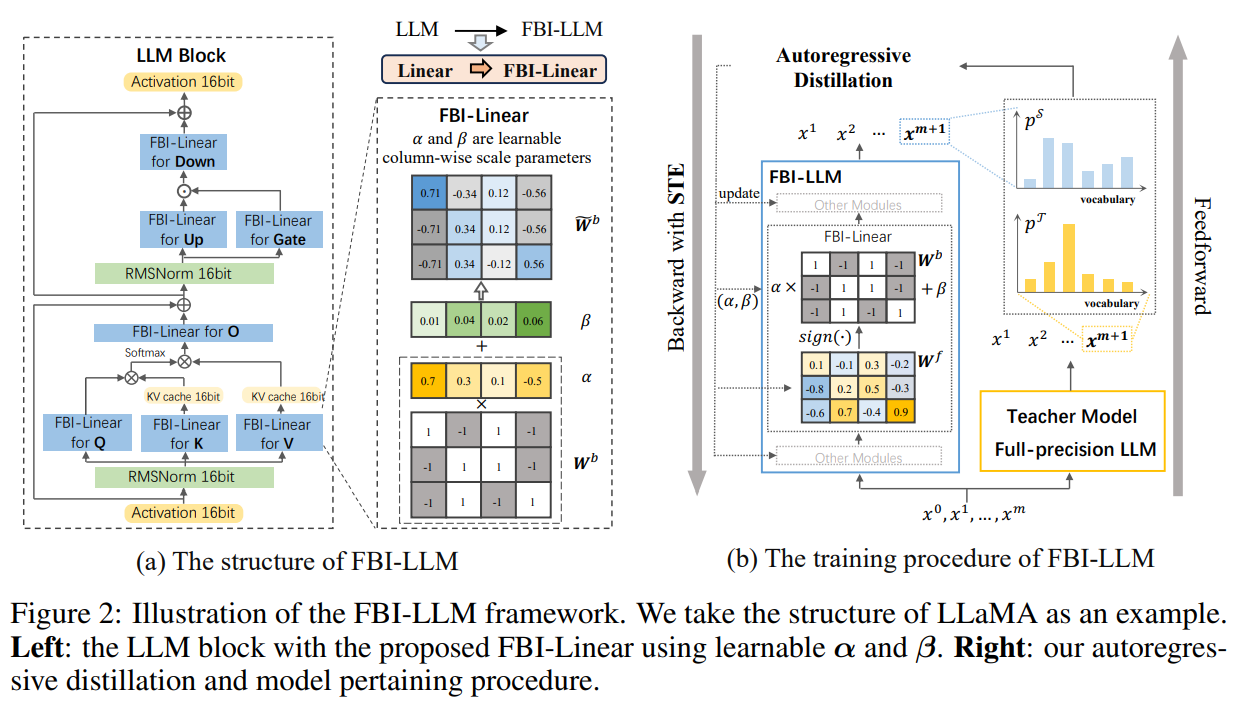
The proposed framework employs autoregressive distillation to realize a 1-bit weight binarization of LLMs from scratch. Experimental outcomes throughout totally different mannequin sizes—130M, 1.3B, and 7B—show that FBI-LLM surpasses present benchmarks whereas successfully balancing mannequin dimension and efficiency. Nevertheless, there are notable limitations. Binarization unavoidably results in efficiency degradation in comparison with full-precision fashions, and the distillation course of provides computational overhead. Present {hardware} constraints additionally hinder direct pace enhancements from binarized LLMs. Moreover, moral considerations surrounding pretrained LLMs, together with biases, privateness dangers, and misinformation, persist even after binarization.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]