[ad_1]
Empowering LLMs to deal with lengthy contexts successfully is important for a lot of functions, however standard transformers require substantial assets for prolonged context lengths. Lengthy contexts improve duties like doc summarization and query answering. But, a number of challenges come up: transformers’ quadratic complexity will increase coaching prices, LLMs need assistance with longer sequences even after fine-tuning, and acquiring high-quality long-text datasets is tough. To mitigate these points, strategies like modifying consideration mechanisms or token compression have been explored, however they usually lead to data loss, hindering exact duties like verification and query answering.
Researchers from Tsinghua and Xiamen Universities launched FocusLLM, a framework designed to increase the context size of decoder-only LLMs. FocusLLM divides lengthy textual content into chunks and makes use of a parallel decoding mechanism to extract and combine related data. This method enhances coaching effectivity and flexibility, permitting LLMs to deal with texts as much as 400K tokens with minimal coaching prices. FocusLLM outperforms different strategies in duties like query answering and long-text comprehension, demonstrating superior efficiency on Longbench and ∞-Bench benchmarks whereas sustaining low perplexity on intensive sequences.
Latest developments in long-context modeling have launched numerous approaches to beat transformer limitations. Size extrapolation strategies, like positional interpolation, intention to adapt transformers to longer sequences however usually battle with distractions from noisy content material. Different strategies modify consideration mechanisms or use compression to handle lengthy texts however fail to make the most of all tokens successfully. Reminiscence-enhanced fashions enhance long-context comprehension by integrating data into persistent reminiscence or encoding and querying lengthy texts in segments. Nevertheless, these strategies face limitations in reminiscence size extrapolation and excessive computational prices, whereas FocusLLM achieves better coaching effectivity and effectiveness on extraordinarily lengthy texts.
The methodology behind FocusLLM entails adapting the LLM structure to deal with extraordinarily lengthy textual content sequences. FocusLLM segments the enter into chunks, every processed by an augmented decoder with further trainable parameters. Native context is appended to every chunk, permitting for parallel decoding, the place candidate tokens are generated concurrently throughout chunks. This method reduces computational complexity considerably, significantly with lengthy sequences. FocusLLM’s coaching makes use of an auto-regressive loss, specializing in predicting the following token, and employs two loss capabilities—Continuation and Repetition loss—to enhance the mannequin’s skill to deal with various chunk sizes and contexts.
The analysis of FocusLLM highlights its sturdy efficiency in language modeling and downstream duties, particularly with long-context inputs. Educated effectively on 8×A100 GPUs, FocusLLM surpasses LLaMA-2-7B and different fine-tuning-free strategies, sustaining secure perplexity even with prolonged sequences. On downstream duties utilizing Longbench and ∞-Bench datasets, it outperformed fashions like StreamingLLM and Activation Beacon. FocusLLM’s design, that includes parallel decoding and environment friendly chunk processing, allows it to deal with lengthy sequences successfully with out the computational burden of different fashions, making it a extremely environment friendly answer for long-context duties.
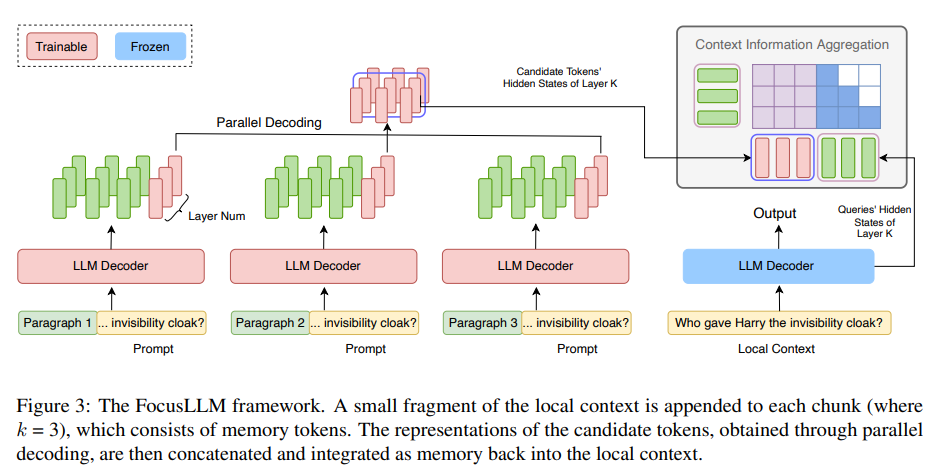
In conclusion, FocusLLM introduces a framework that considerably extends the context size of LLMs by using a parallel decoding technique. This method divides lengthy texts into manageable chunks, extracting important data from every and integrating it into the context. FocusLLM performs superior downstream duties whereas sustaining low perplexity, even with sequences as much as 400K tokens. Its design permits for exceptional coaching effectivity, enabling long-context processing with minimal computational and reminiscence prices. This framework presents a scalable answer for enhancing LLMs, making it a useful instrument for long-context functions.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]