[ad_1]
Giant language fashions (LLMs) have proven promise in powering autonomous brokers that management pc interfaces to perform human duties. Nevertheless, with out fine-tuning on human-collected activity demonstrations, the efficiency of those brokers stays comparatively low. A key problem lies in growing viable approaches to construct real-world pc management brokers that may successfully execute advanced duties throughout various functions and environments. The present methodologies, which depend on pre-trained LLMs with out task-specific fine-tuning, have achieved solely restricted success, with reported activity success charges starting from 12% to 46% in latest research.
Earlier makes an attempt to develop pc management brokers have explored varied approaches, together with zero-shot and few-shot prompting of enormous language fashions, in addition to fine-tuning strategies. Zero-shot prompting strategies make the most of pre-trained LLMs with none task-specific fine-tuning, whereas few-shot approaches present a small variety of examples to the LLM. Nice-tuning strategies contain additional coaching the LLM on activity demonstrations, both end-to-end or for particular capabilities like figuring out interactable UI parts. Notable examples embody SeeAct, WebGPT, WebAgent, and Synapse. Nevertheless, these present strategies have limitations by way of efficiency, area generalization, or the complexity of duties they’ll deal with successfully.
Google DeepMind and Google researchers current ANDROIDCONTROL, a large-scale dataset of 15,283 human demonstrations of duties carried out in Android apps. A key function of ANDROIDCONTROL is that it gives each high-level and low-level human-generated directions for each activity, enabling the investigation of activity complexity ranges that fashions can deal with whereas providing richer supervision throughout coaching. Additionally, it’s the most various UI management dataset so far, comprising 15,283 distinctive duties throughout 833 completely different Android apps. This variety permits for the technology of a number of take a look at splits to measure efficiency each out and in of the duty area coated by the coaching information. The proposed methodology entails using ANDROIDCONTROL to quantify how fine-tuning scales when utilized to low and high-level duties, each in-domain and out-of-domain, and evaluating fine-tuning approaches with varied zero-shot and few-shot baselines.

The ANDROIDCONTROL dataset was collected over a yr by way of crowdsourcing. Crowdworkers had been supplied with generic function descriptions for apps throughout 40 completely different classes and requested to instantiate these into particular duties involving apps of their alternative. This strategy led to the gathering of 15,283 activity demonstrations spanning 833 Android apps, together with common apps in addition to much less common or regional ones. For every activity, annotators first supplied a high-level pure language description. Then, they carried out the duty on a bodily Android gadget, with their actions and related screenshots captured. Importantly, annotators additionally supplied low-level pure language descriptions of every motion earlier than executing it. The ensuing dataset accommodates each high-level and low-level directions for every activity, enabling evaluation of various activity complexity ranges. Cautious dataset splits had been created to measure in-domain and out-of-domain efficiency.
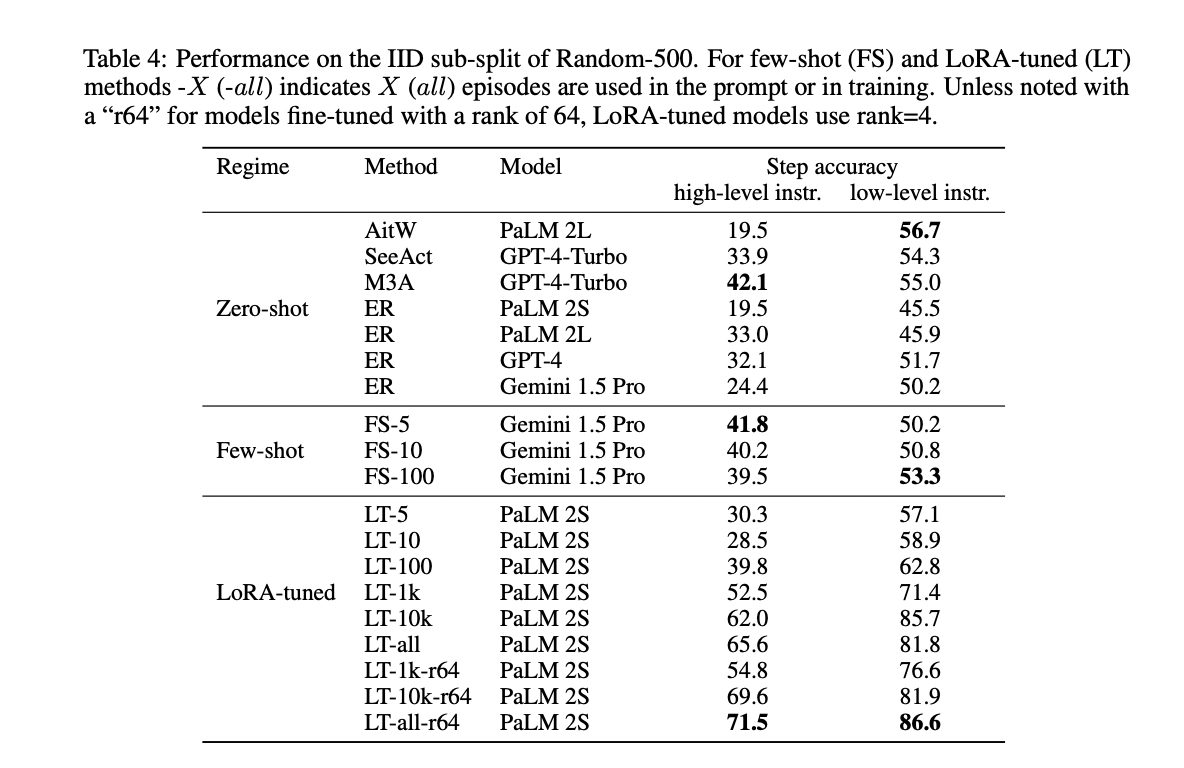
The outcomes present that for in-domain analysis on the IDD subset, LoRA-tuned fashions outperform zero-shot and few-shot strategies when skilled with adequate information, regardless of utilizing the smaller PaLM 2S mannequin. Even with simply 5 coaching episodes (LT-5), LoRA-tuning surpasses all non-finetuned fashions on low-level directions. For prime-level directions, 1k episodes are required. The most effective LoRA-tuned mannequin achieves 71.5% accuracy on high-level and 86.6% on low-level directions. Amongst zero-shot strategies, AitW with PaLM 2L performs finest (56.7%) on low-level, whereas M3A with GPT-4 is highest (42.1%) on high-level directions, probably benefiting from incorporating high-level reasoning. Surprisingly, few-shot efficiency is usually inferior to zero-shot throughout the board. The outcomes spotlight the sturdy in-domain advantages of fine-tuning, particularly for extra information.
This work launched ANDROIDCONTROL, a big and various dataset designed to check mannequin efficiency on low and high-level duties, each in-domain and out-of-domain, as coaching information is scaled. By analysis of LoRA fine-tuned fashions on this dataset, it’s predicted that reaching 95% accuracy on in-domain low-level duties would require round 1 million coaching episodes, whereas 95% episode completion fee on 5-step high-level in-domain duties would require roughly 2 million episodes. These outcomes recommend that whereas probably costly, fine-tuning could also be a viable strategy for acquiring excessive in-domain efficiency throughout activity complexities. Nevertheless, out-of-domain efficiency requires one to 2 orders of magnitude extra information, indicating that fine-tuning alone could not scale effectively and extra approaches could also be useful, particularly for strong efficiency on out-of-domain high-level duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 44k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.
[ad_2]