[ad_1]
Giant Language Fashions (LLMs) have gained important traction in numerous domains, revolutionizing purposes from conversational brokers to content material era. These fashions exhibit distinctive capabilities in comprehending and producing human-like textual content, enabling subtle purposes throughout numerous fields. Nevertheless, the deployment of LLMs necessitates sturdy mechanisms to make sure secure and accountable person interactions. Present practices typically make use of content material moderation options like LlamaGuard, WildGuard, and AEGIS to filter LLM inputs and outputs for potential security dangers. Regardless of offering preliminary safeguards, these instruments face limitations. They typically lack granular predictions of hurt sorts or provide solely binary outputs as an alternative of possibilities, limiting personalized hurt filtering or threshold changes. Additionally, most options present fixed-size fashions, which can not align with particular deployment wants. With that, the absence of detailed directions for setting up coaching knowledge hampers the event of fashions sturdy towards adversarial prompts and truthful throughout identification teams.
Researchers have made important strides in content material moderation, notably for human-generated content material on on-line platforms. Instruments like Perspective API have been instrumental in detecting poisonous language. Nevertheless, these assets typically fall brief when utilized to the distinctive context of human prompts and LLM-generated responses. Current developments in LLM content material moderation have emerged via fine-tuning approaches, as seen in fashions like Llama-Guard, Aegis, MD-Decide, and WildGuard.
The event of sturdy security fashions hinges on high-quality knowledge. Whereas human-computer interplay knowledge is plentiful, its direct use presents challenges as a result of restricted constructive examples, lack of adversarial and numerous knowledge, and privateness issues. LLMs, using their huge pre-trained data, have demonstrated distinctive capabilities in producing artificial knowledge aligned with human necessities. Within the security area, this method permits for the creation of numerous and extremely adversarial prompts that may successfully check and enhance LLM security mechanisms.
Security insurance policies play a vital position in deploying AI methods in real-world eventualities. These insurance policies present pointers for acceptable content material in each person inputs and mannequin outputs. They serve twin functions: guaranteeing consistency amongst human annotators and facilitating the event of zero-shot/few-shot classifiers as out-of-the-box options. Whereas the classes of disallowed content material are largely constant for each inputs and outputs, the emphasis differs. Enter insurance policies concentrate on prohibiting dangerous requests or makes an attempt to elicit dangerous content material, whereas output insurance policies primarily intention to stop the era of any dangerous content material.
Researchers from Google current ShieldGemma, a spectrum of content material moderation fashions starting from 2B to 27B parameters, constructed on Gemma2. These fashions filter each person enter and mannequin output for key hurt sorts, adapting to numerous software wants. The innovation lies in a novel methodology for producing high-quality, adversarial, numerous, and truthful datasets utilizing artificial knowledge era strategies. This method reduces human annotation effort and has broad applicability past safety-related challenges. By combining scalable architectures with superior knowledge era, ShieldGemma addresses the restrictions of present options, providing extra nuanced and adaptable content material filtering throughout totally different deployment eventualities.
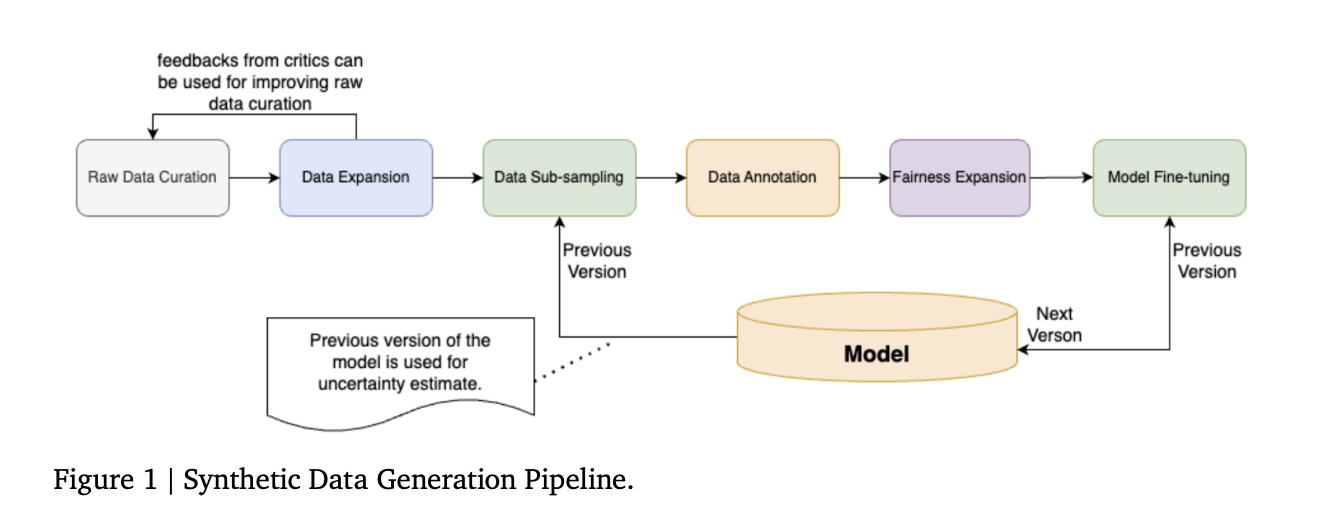
ShieldGemma introduces a complete method to content material moderation based mostly on the Gemma2 framework. The tactic defines an in depth content material security taxonomy for six hurt sorts: Sexually Express Info, Hate Speech, Harmful Content material, Harassment, Violence, and Obscenity and Profanity. This taxonomy guides the mannequin’s decision-making course of for each person enter and mannequin output eventualities.
The core innovation lies within the artificial knowledge curation pipeline. This course of begins with uncooked knowledge era utilizing AART (Automated Adversarial Pink Teaming) to create numerous, adversarial prompts. The information is then expanded via a self-critiquing and era framework, enhancing semantic and syntactic variety. The dataset is additional augmented with examples from Anthropic HH-RLHF to extend selection.
To optimize the coaching course of, ShieldGemma employs a cluster-margin algorithm for knowledge sub-sampling, balancing uncertainty and variety. The chosen knowledge undergoes human annotation, with equity enlargement utilized to enhance illustration throughout numerous identification classes. Lastly, the mannequin is fine-tuned utilizing supervised studying on Gemma2 Instruction-Tuned fashions of various sizes (2B, 9B, and 27B parameters).
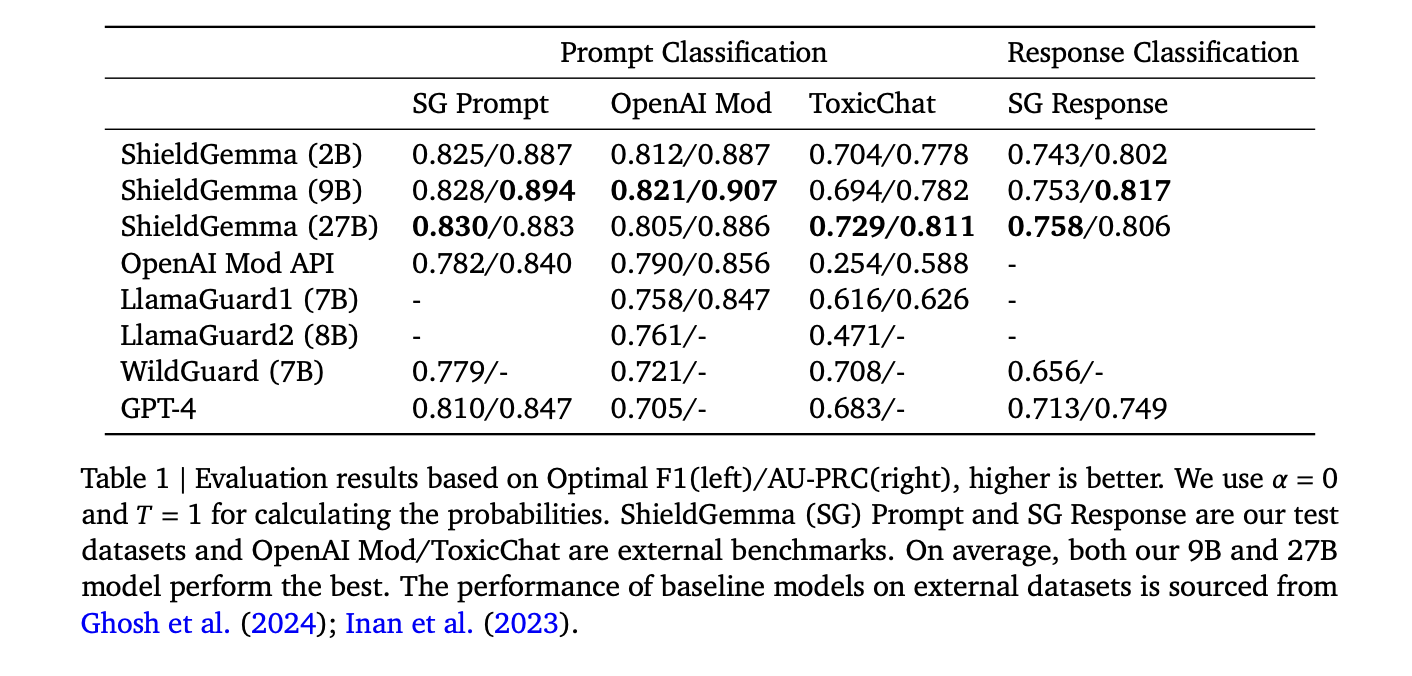
ShieldGemma (SG) fashions exhibit superior efficiency in binary classification duties throughout all sizes (2B, 9B, and 27B parameters) in comparison with baseline fashions. The SG-9B mannequin, specifically, achieves a ten.8% greater common AU-PRC on exterior benchmarks than LlamaGuard1, regardless of having the same mannequin measurement and coaching knowledge quantity. Additionally, the 9B mannequin’s F1 rating surpasses that of WildGuard and GPT-4 by 4.3% and 6.4%, respectively. Inside the ShieldGemma household, efficiency is constant on inner benchmarks. Nevertheless, on exterior benchmarks, the 9B and 27B fashions present barely higher generalization functionality, with common AU-PRC scores 1.2% and 1.7% greater than the 2B mannequin, respectively. These outcomes spotlight ShieldGemma’s effectiveness in content material moderation duties throughout numerous mannequin sizes.
ShieldGemma marks a major development in security content material moderation for Giant Language Fashions. Constructed on Gemma2, this suite of fashions (2B to 27B parameters) demonstrates superior efficiency throughout numerous benchmarks. The important thing innovation lies in its novel artificial knowledge era pipeline, producing high-quality, numerous datasets whereas minimizing human annotation. This technique extends past security purposes, probably benefiting numerous AI growth domains. By outperforming present baselines and providing versatile deployment choices, ShieldGemma enhances the protection and reliability of LLM interactions. Sharing these assets with the analysis group goals to speed up progress in AI security and accountable deployment.
Try the Paper and HF Mannequin Card. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.

[ad_2]