[ad_1]
Giant language fashions (LLMs) face challenges in successfully using further computation at take a look at time to enhance the accuracy of their responses, notably for advanced duties. Researchers are exploring methods to allow LLMs to assume longer on tough issues, just like human cognition. This functionality may doubtlessly unlock new avenues in agentic and reasoning duties, allow smaller on-device fashions to exchange datacenter-scale LLMs and supply a path towards common self-improvement algorithms with decreased human supervision. Nevertheless, present approaches present combined outcomes, with some research demonstrating enhancements in LLM outputs utilizing test-time computation, whereas others reveal restricted effectiveness on advanced duties like math reasoning. These conflicting findings underscore the necessity for a scientific evaluation of various approaches for scaling test-time computes in LLMs.
Researchers have made important progress in enhancing language mannequin efficiency on mathematical reasoning duties by numerous approaches. These embrace continued pretraining on math-focused information, enhancing the LLM proposal distribution by focused optimization and iterative reply revision, and enabling LLMs to profit from further test-time computation utilizing finetuned verifiers. A number of strategies have been proposed to reinforce LLMs with test-time computing, akin to hierarchical speculation seek for inductive reasoning, software augmentation, and studying thought tokens for extra environment friendly use of further test-time computing. Nevertheless, the effectiveness of those strategies varies relying on the precise drawback and the bottom LLM used. For simpler issues the place the bottom LLM can produce cheap responses, iterative refinement of preliminary solutions by a sequence of revisions could also be simpler. In distinction, for tougher issues requiring exploration of assorted high-level approaches, sampling impartial responses in parallel or using tree-search in opposition to a process-based reward mannequin could be extra useful. The evaluation of test-time compute scaling in language fashions, notably for math reasoning issues the place the bottom reality is unknown, stays an vital space of analysis.
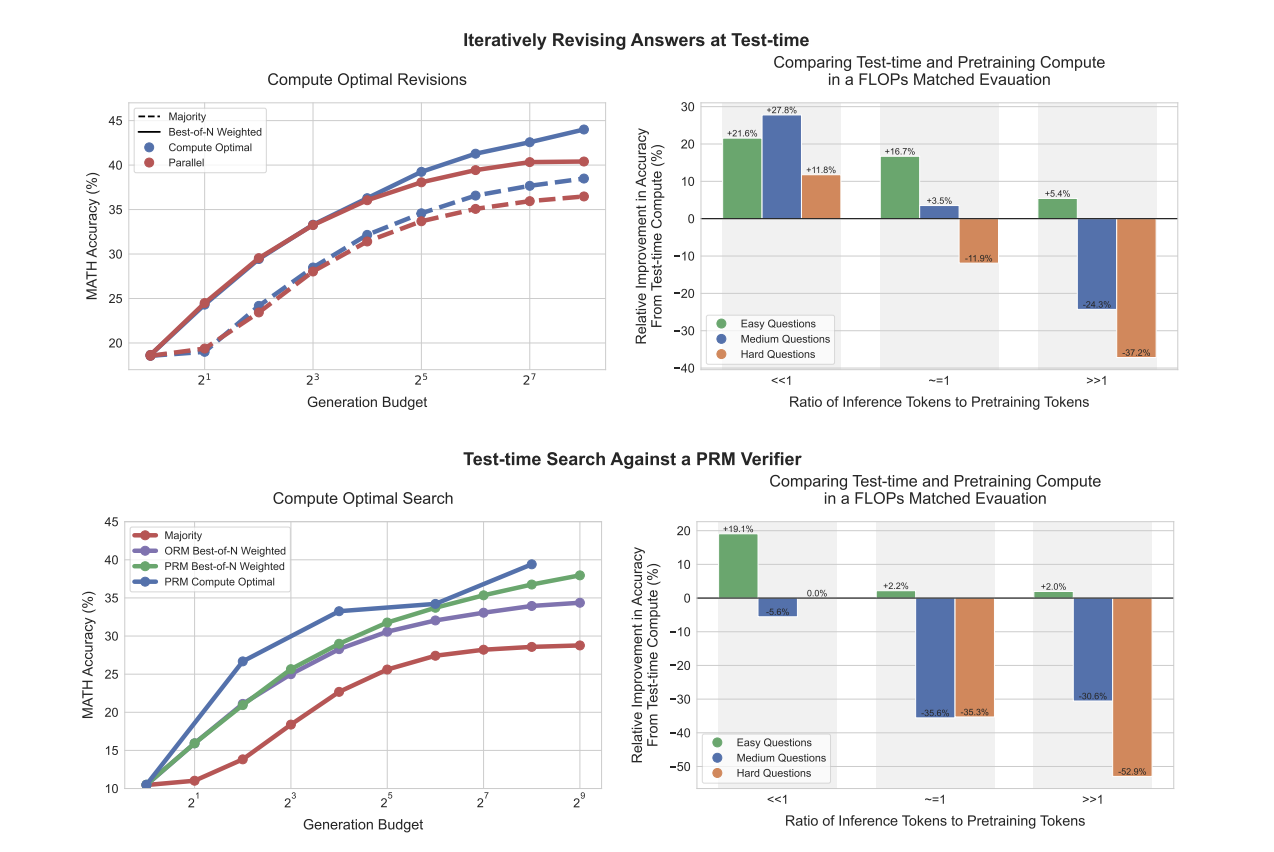
Researchers from UC Berkeley, and Google DeepMind suggest an adaptive “compute-optimal” technique for scaling test-time computing in LLMs. This method selects the simplest methodology for using further computation primarily based on the precise immediate and query issue. By using a measure of query issue from the bottom LLM’s perspective, the researchers can predict the efficacy of test-time computation and implement this compute-optimal technique in follow. This adaptive allocation of test-time compute considerably improves scaling efficiency, surpassing best-of-N baselines whereas utilizing roughly 4 instances much less computation for each revision and search strategies. The researchers then evaluate the effectiveness of their improved test-time compute scaling technique in opposition to the choice of pretraining bigger fashions.
The usage of further test-time computation in LLMs will be considered by a unified perspective of modifying the mannequin’s predicted distribution adaptively at test-time. This modification will be achieved by two essential approaches: altering the proposal distribution and optimizing the verifier. To enhance the proposal distribution, researchers have explored strategies akin to RL-inspired finetuning (e.g., STaR, ReSTEM) and self-critique methods. These approaches allow the mannequin to reinforce its personal outputs at take a look at time by critiquing and revising its preliminary responses iteratively. Finetuning fashions on on-policy information with Greatest-of-N guided enhancements have proven promise in advanced reasoning duties.
For verifier optimization, the normal best-of-N sampling methodology will be enhanced by coaching a process-based verifier or course of reward mannequin (PRM). This method permits for predictions of correctness at every intermediate step of an answer, reasonably than simply the ultimate reply. By using these per-step predictions, a extra environment friendly and efficient tree search will be carried out over the answer house, doubtlessly outperforming naive best-of-N sampling. These strategies of modifying the proposal distribution and optimizing the verifier type two impartial axes of research in enhancing test-time computation for language fashions. The effectiveness of every method could fluctuate relying on the precise process and mannequin traits.
The method includes choosing optimum hyperparameters for a given test-time technique to maximise efficiency advantages. To implement this, the researchers introduce a technique for estimating query issue, which serves as a key think about figuring out the simplest compute allocation. Query issue is outlined utilizing the bottom LLM’s efficiency, binning questions into 5 issue ranges primarily based on the mannequin’s move@1 fee. This model-specific issue measure proved extra predictive of test-time compute efficacy than hand-labeled issue bins. To make the technique sensible with out counting on ground-truth solutions, the researcher’s approximate query issue utilizing a model-predicted notion primarily based on realized verifier scores. This method permits for issue evaluation and technique choice with out realizing the proper reply upfront. The compute-optimal technique is then decided for every issue bin utilizing a validation set and utilized to the take a look at set. This methodology permits adaptive allocation of test-time compute assets, doubtlessly resulting in important enhancements in efficiency in comparison with uniform or ad-hoc allocation methods.
This research analyzes numerous approaches for optimizing test-time compute scaling in LLMs, together with search algorithms with course of verifiers (PRMs) and refining the proposal distribution by revisions. Beam search outperforms best-of-N at decrease era budgets, however this benefit diminishes as budgets improve. Sequential revisions typically outperform parallel sampling, with the optimum ratio between the 2 relying on query issue. Simpler questions profit extra from sequential revisions, whereas more durable questions require a steadiness between sequential and parallel computing. The effectiveness of search strategies varies primarily based on query issue, with beam search displaying enhancements on medium-difficulty issues however indicators of over-optimization on simpler ones. By optimally choosing methods primarily based on query issue and compute price range, the compute-optimal scaling method can outperform the parallel best-of-N baseline utilizing as much as 4x much less test-time compute. The research additionally reveals that test-time computing is extra useful for straightforward to medium-difficulty questions or in settings with decrease inference masses, whereas pretraining is simpler for difficult questions or excessive inference necessities.

This research demonstrates the significance of adaptive “compute-optimal” methods for scaling test-time computes in LLM’s. By predicting test-time computation effectiveness primarily based on query issue, researchers applied a sensible technique that outperformed best-of-N baselines utilizing 4x much less computation. A comparability between further test-time compute and bigger pre-trained fashions confirmed that for straightforward to intermediate questions, test-time compute typically outperforms elevated pretraining. Nevertheless, for probably the most difficult questions, further pretraining stays simpler. These findings counsel a possible shift in direction of allocating fewer FLOPs to pretraining and extra to inference sooner or later, highlighting the evolving panorama of LLM optimization and deployment.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Neglect to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.

[ad_2]